MySQL字符串前缀索引使用
来源:脚本之家
时间:2023-02-25 09:47:19 190浏览 收藏
小伙伴们有没有觉得学习数据库很有意思?有意思就对了!今天就给大家带来《MySQL字符串前缀索引使用》,以下内容将会涉及到索引、前缀、mysql字符串,若是在学习中对其中部分知识点有疑问,或许看了本文就能帮到你!
1. 前缀索引与全部索引概念
怎么给字符串字段加索引?现在,几乎所有的系统都支持邮箱登录,如何在邮箱这样的字段上建立合理的索引,是我们今天要讨论的问题。
假设,你现在维护一个支持邮箱登录的系统,用户表是这么定义的
create table SUser( ID bigint unsigned primary key, email varchar(64), name varchar(64), ... )engine=innodb;
由于要使用邮箱登录,所以业务代码中一定会出现类似于这样的语句:
select f1, f2 from SUser where email='xxx';
我们知道,如果email这个字段上没有索引,那么这个语句就只能做全表扫描。
MySQL支持全部索引与前缀索引。MySQL是支持前缀索引的,也就是说,你可以定义字符串的一部分作为索引。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
比如,这两个在email字段上创建索引的语句:
-- 全部索引,索引字段为email整个字符串 alter table SUser add index index1(email); -- 前缀索引,6表示索引字段为email的前6位 alter table SUser add index index2(email(6));
第一个语句创建的index1索引里面,包含了每个记录的整个字符串;而第二个语句创建的index2索引里面,对于每个记录都是只取前6个字节。
2. 前缀索引与全部索引数据结构
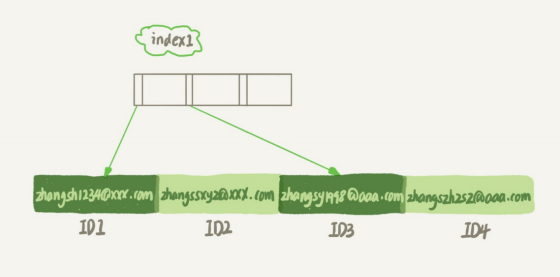
这两种不同的定义在数据结构和存储上有什么区别呢?如图2和3所示,就是这两个索引的示意图。
mysql全部索引数据结构
mysql前缀索引数据结构
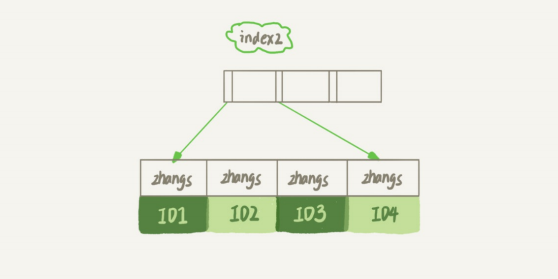
从图中你可以看到,由于email(6)这个索引结构中每个邮箱字段都只取前6个字节(即:zhangs),所以占用的空间会更小,这就是使用前缀索引的优势。但,这同时带来的损失是,可能会增加额外的记录扫描次数。
3. 前缀索引与全部索引引执行流程
接下来,我们再看看下面这个语句,在这两个索引定义下分别是怎么执行的。
如 index1(即email整个字符串的索引结构),执行顺序是这样的:
- 从index1索引树找到满足索引值是’zhangssxyz@xxx.com’的这条记录,取得ID2的值;
- 到主键上查到主键值是ID2的行,判断email的值是正确的,将这行记录加入结果集;
- 取index1索引树上刚刚查到的位置的下一条记录,发现已经不满足email='zhangssxyz@xxx.com’的条件了,循环结束。
这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
如 index2(即email(6)索引结构),执行顺序是这样的:
- 从index2索引树找到满足索引值是’zhangs’的记录,找到的第一个是ID1;
- 到主键上查到主键值是ID1的行,判断出email的值不是’zhangssxyz@xxx.com’,这行记录丢弃;
- 取index2上刚刚查到的位置的下一条记录,发现仍然是’zhangs’,取出ID2,再到ID索引上取整行然后判断,这次值对了,将这行记录加入结果集;
- 重复上一步,直到在idxe2上取到的值不是’zhangs’时,循环结束。
在这个过程中,要回主键索引取4次数据,也就是扫描了4行。
通过这个对比,你很容易就可以发现,使用前缀索引后,可能会导致查询语句读数据的次数变多。
4. 前缀索引长度如何取舍
对于这个查询语句来说,如果你定义的index2不是email(6)而是email(7),也就是说取email字段的前7个字节来构建索引的话,即满足前缀’zhangss’的记录只有一个,也能够直接查到ID2,只扫描一行就结束了。
也就是说使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查 使询成本。
于是,你就有个问题:当要给字符串创建前缀索引时,有什么方法能够确定我应该使用多长的前缀呢?实际上,我们在建立索引时关注的是区分度,区分度越高越好。因为区分度越高,意味着重复的键值越少。因此,我们可以通过统计索引上有多少个不同的值来判断要使用多长的前缀。
首先,你可以使用下面这个语句,算出这个列上有多少个不同的值:
select count(distinct email) as L from SUser;
然后,依次选取不同长度的前缀来看这个值,比如我们要看一下4~7个字节的前缀索引,可以用这个语句:
select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser;
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例,比如5%。然后,在返回的L4~L7中,找出不小于 L * 95%的值,假设这里L6、L7都满足,你就可以选择前缀长度为6。
5. 前缀索引对覆盖索引的影响
前面我们说了使用前缀索引可能会增加扫描行数,这会影响到性能。其实,前缀索引的影响不止如此,我们再看一下另外一个场景。
你先来看看这个SQL语句
select id,email from SUser where email='zhangssxyz@xxx.com';
与前面例子中的SQL语句
select id,name,email from SUser where email='zhangssxyz@xxx.com';
id是主键,email是索引,name不是索引的情况下,先说结论,当email是全部索引的时候第一个sql会走覆盖索引,第二个不会走覆盖索引,当email为前缀索引的时候哪怕前缀为全部字符串长度依然无法走覆盖索引。
所以,如果使用index1(即email整个字符串的索引结构)的话,可以利用覆盖索引,从index1查到结果后直接就返回了,不需要回到ID索引再去查一次。而如果使用index2(即email(6)索引结构)的话,就不得不回到ID索引再去判断email字段的值。
即使你将index2的定义修改为email(18)的前缀索引,这时候虽然index2已经包含了所有的信息,但InnoDB还是要回到id索引再查一下,因为系统并不确定前缀索引的定义是否截断了完整信息。
也就是说,使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是你在选择是否使用前缀索引时需要考虑的一个因素。
6. 其他解决方案
对于类似于邮箱这样的字段来说,使用前缀索引的效果可能还不错。但是,遇到前缀的区分度不够好的情况时,我们要怎么办呢?
比如,我们国家的身份证号,一共18位,其中前6位是地址码,所以同一个县的人的身份证号前6位一般会是相同的。假设你维护的数据库是一个市的公民信息系统,这时候如果对身份证号做长度为6的前缀索引的话,这个索引的区分度就非常低了。按照我们前面说的方法,可能你需要创建长度为12以上的前缀索引,才能够满足区分度要求。但是,索引选取的越长,占用的磁盘空间就越大,相同的数据页能放下的索引值就越少,搜索的效率也就会越低。
那么,如果我们能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?这种方法,既可以占用更小的空间,也能达到相同的查询效率。答案是,有的。
第一种方式是使用倒序存储。 第 如果你存储身份证号的时候把它倒过来存,每次查询的时候,你可以这么写:
select field_list from t where id_card = reverse('input_id_card_string');
由于身份证号的最后6位没有地址码这样的重复逻辑,所以最后这6位很可能就提供了足够的区分度。当然了,实践中你不要忘记使用count(distinct)方法去做个验证。
第二种方式是使用 第 hash h 字段。 字 你可以在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
然后每次插入新记录的时候,都同时用crc32()这个函数得到校验码填到这个新字段。由于校验码可能存在冲突,也就是说两个不同的身份证号通过crc32()函数得到的结果可能是相同的,所以你的查询语句where部分要判断id_card的值是否精确相同。
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
这样,索引的长度变成了4个字节,比原来小了很多。
接下来,我们再一起看看使用倒序存储和使用 使 hash h 字段这两种方法的异同点。 字首先,它们的相同点是,都不支持范围查询。倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经没有办法利用索引方式查出身份证号码在[ID_X, ID_Y]的所有市民了。同样地,hash字段的方式也只能支持等值查询。
它们的区别,主要体现在以下三个方面:
- 从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而hash字段方法需要增加一个字段。当然,倒序存储方式使用4个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个hash字段也差不多抵消了。
- 在CPU消耗方面,倒序方式每次写和读的时候,都需要额外调用一次reverse函数,而hash字段的方式需要额外调用一次crc32()函数。如果只从这两个函数的计算复杂度来看的话,reverse函数额外消耗的CPU资源会更小些。
- 从查询效率上看,使用hash字段方式的查询性能相对更稳定一些。因为crc32算出来的值虽然有冲突的概率,但是概率非常小,可以认为每次查询的平均扫描行数接近1。而倒序存储方式毕竟还是用的前缀索引的方式,也就是说还是会增加扫描行数。
7. 梳理总结
总体来说的话全部索引会占用一部分空间,但是可以走覆盖索引,区分度比较高,减少回表次数,前缀索引虽然减少了部分空间,但是需要平衡区分度,而且需要时刻关注表中索引字段的变化,因为随着数据的变化区分度也会变化,可能原来前缀6个字段区分度就能达到95%以上,但是随着数据增加前6个字段只能达到60%的区分度,另外一点就是覆盖索引无法使用,虽然倒叙或者hash能解决空间问题,但是又会产生新的问题,比如需要函数,增加字段等,是查询效率降低,折中选择全部索引会更加稳妥,效率更高,当然对于特定的字符串比如自己公司email,前6位足够区分,而且后续不会有改动,这时前缀索引既能减少空间占用,又能达到与全部索引一样的效果,使用前缀会更好。具体使用场景一定是结合具体的业务场景选择。
今天关于《MySQL字符串前缀索引使用》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于mysql的内容请关注golang学习网公众号!
-
234 收藏
-
379 收藏
-
151 收藏
-
109 收藏
-
473 收藏
-
数据库 · MySQL | 2天前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限413 收藏
-
278 收藏
-
数据库 · MySQL | 3天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引351 收藏
-
数据库 · MySQL | 4天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移236 收藏
-
471 收藏
-
数据库 · MySQL | 6天前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT117 收藏
-
数据库 · MySQL | 6天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort279 收藏
-
数据库 · MySQL | 1星期前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows470 收藏
-
421 收藏
-
189 收藏
-
412 收藏
-
378 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 自然的灯泡
- 这篇技术文章出现的刚刚好,太详细了,太给力了,码起来,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-03-12 19:26:30
-
- 受伤的棒棒糖
- 这篇技术贴出现的刚刚好,很详细,受益颇多,收藏了,关注老哥了!希望老哥能多写数据库相关的文章。
- 2023-03-07 04:53:26
-
- 正直的帆布鞋
- 细节满满,已加入收藏夹了,感谢楼主的这篇博文,我会继续支持!
- 2023-03-05 06:06:12
-
- 鲤鱼花生
- 很有用,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者大大分享文章内容!
- 2023-03-02 12:21:42
-
- 开心的板栗
- 这篇技术贴太及时了,up主加油!
- 2023-02-28 15:16:47