MySQL 8.4 字符集排序规则实战:同样的查询为什么索引突然失效
来源:17golang MySQL频道原创
时间:2026-06-04 14:21:37 294浏览 收藏
先说结论:字符集和排序规则不是“显示问题”,它会影响比较、唯一性和索引
MySQL 8.x 里很多新库默认会用 utf8mb4_0900_ai_ci。这本身没问题,问题是老表、迁移表、临时表、导入脚本经常混着 utf8mb4_general_ci、utf8mb4_bin 或其他排序规则。等到账号唯一键、昵称搜索、跨表 JOIN 出问题时,大家才发现“字符集统一”不是一句口号。
我排这类问题时,会先问业务到底要什么比较语义:账号邮箱是否大小写敏感,昵称搜索是否忽略重音,订单号是否必须按字节完全一致。语义没定清楚,后面建什么索引都容易错。
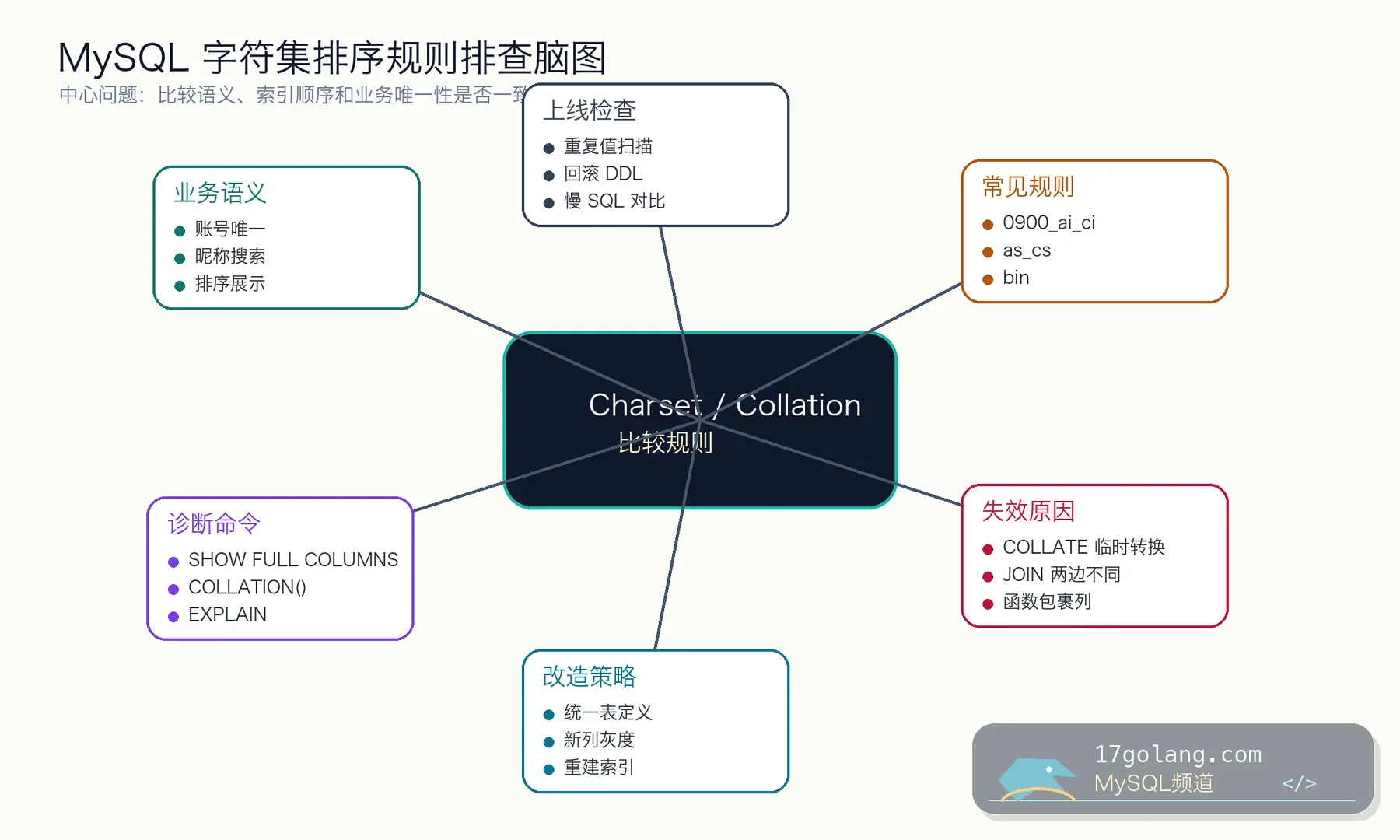
业务场景:同一个邮箱为什么有时算重复,有时又不算
假设用户表这么建:
CREATE TABLE users ( id BIGINT PRIMARY KEY, email VARCHAR(128) NOT NULL, nickname VARCHAR(64) NOT NULL, UNIQUE KEY uk_email (email) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
在 utf8mb4_0900_ai_ci 下,很多比较是大小写不敏感的。业务如果认为 Tom@example.com 和 tom@example.com 是同一个账号,这正合适;但如果业务要求按字节区分,这个唯一键语义就错了。
INSERT INTO users(id, email, nickname) VALUES (1, 'Tom@example.com', 'Tom'); -- 在大小写不敏感排序规则下,可能触发唯一键冲突 INSERT INTO users(id, email, nickname) VALUES (2, 'tom@example.com', 'tom');
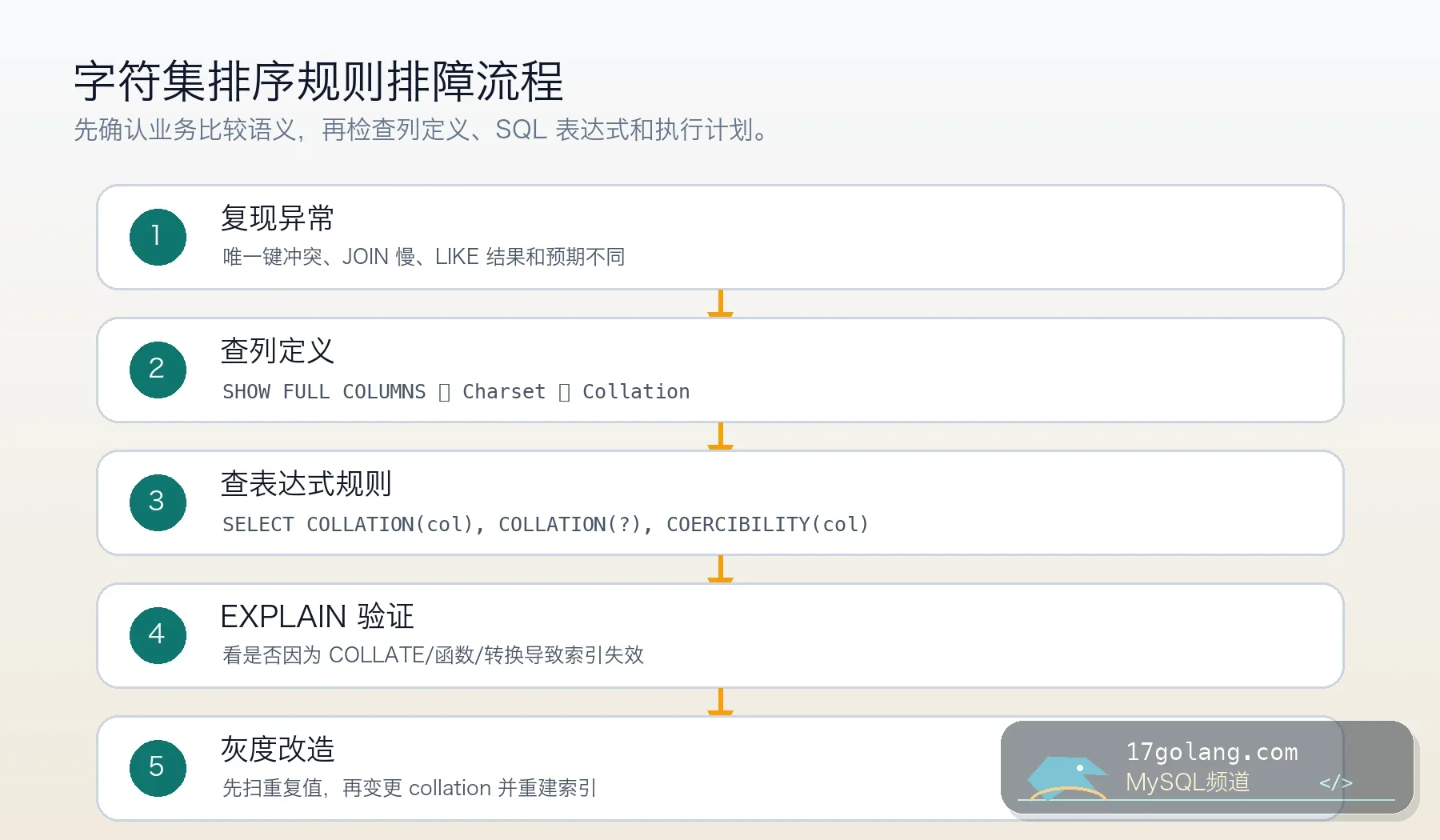
诊断第一步:先把列定义查出来
不要靠猜,直接查列级定义:
SHOW FULL COLUMNS FROM users; SELECT TABLE_NAME, COLUMN_NAME, CHARACTER_SET_NAME, COLLATION_NAME FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = DATABASE() AND TABLE_NAME = 'users';
如果同一个业务链路里,用户表是 utf8mb4_0900_ai_ci,登录审计表是 utf8mb4_bin,临时导入表又是另一个 collation,JOIN 和比较就要特别小心。
踩坑一:在热点 SQL 里临时 COLLATE
有人为了临时解决大小写敏感,会在 SQL 里写:
SELECT id FROM users WHERE email COLLATE utf8mb4_bin = 'Tom@example.com';
这类写法语义上可能能跑,但在热点查询里很危险。因为你把列侧比较规则临时换掉了,原来按列 collation 建的索引顺序未必还能被直接利用。更稳的做法是按业务语义设计列本身的 collation,再让索引跟着列定义走。
ALTER TABLE users MODIFY email VARCHAR(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL;
这类 DDL 上线前要先扫重复值,否则改成更严格或更宽松的比较规则,都可能暴露历史脏数据。

踩坑二:JOIN 两边 collation 不一致
跨表 JOIN 最容易被忽略。比如订单表里的 buyer_email 和用户表里的 email collation 不一致:
SELECT o.id, u.id FROM orders o JOIN users u ON o.buyer_email = u.email WHERE o.created_at >= '2026-06-01';
如果优化器需要在比较时做隐式转换,执行计划可能和你预期不同。我的习惯是把关联字段的字符集、collation、长度、是否可空都统一掉。跨表关联字段不统一,是以后慢查询和数据异常的长期伏笔。
踩坑三:排序结果不是用户想的“字典序”
排序规则不只是等值比较,也影响 ORDER BY。比如昵称列表、商品名称、编码字段,如果业务希望按二进制、拼音、大小写敏感或不敏感排序,需要提前定规则。不要等产品说“排序不对”时才发现数据库规则和展示规则不是一回事。
SELECT nickname FROM users ORDER BY nickname COLLATE utf8mb4_0900_ai_ci LIMIT 50;
这类临时排序可以用于低频后台页面,但如果是核心列表页,最好评估是否需要专门的排序字段或固定列 collation,避免每次查询都额外计算。
上线检查:改 collation 前先扫重复和慢 SQL
改字符集排序规则不是小改动。我的上线清单一般包括:
- 扫描目标列在新规则下是否会出现重复值,尤其是唯一键列。
- 列、索引、关联表字段一起检查,不只改单表。
- 对 TOP SQL 跑
EXPLAIN,确认没有因为临时转换导致索引失效。 - 大表变更走在线 DDL 或灰度新列,准备回滚窗口。
- 应用层参数字符集固定为
utf8mb4,避免连接级设置漂移。
-- 检查表达式当前使用的排序规则 SELECT COLLATION(email), COERCIBILITY(email) FROM users LIMIT 1; -- 检查 SQL 是否仍然命中目标索引 EXPLAIN SELECT id FROM users WHERE email = 'Tom@example.com';
个人经验:账号类字段宁可规则严格一点
昵称、备注、搜索关键词可以根据用户体验选择更宽松的排序规则;但账号、外部单号、幂等键、签名字段,我通常倾向于更明确、更严格的比较规则。因为这些字段一旦比较语义含糊,后面会变成唯一键冲突、重复注册、对账失败。
最怕的是同一个字段在不同表里语义不一致:注册时大小写不敏感,登录审计大小写敏感,风控 JOIN 又发生隐式转换。等数据量上来后,这些问题会同时表现为慢查询和业务异常。
总结
MySQL 8.x 的字符集和排序规则会直接影响等值比较、唯一键、JOIN、ORDER BY 和索引命中。排查时不要只看 SQL 文本,要查列定义、表达式 collation、执行计划和历史数据重复风险。业务语义定清楚,列定义统一,索引才有稳定的基础。
-
数据库 · MySQL | 3星期前 | InnoDB · MySQL教程 · 数据库实战 · 死锁排查 · 锁等待 · mysql innodb 死锁 事务 锁等待 MySQL 8 data_locks105 收藏
-
108 收藏
-
数据库 · MySQL | 3星期前 | binlog · 主从复制 · 故障排查 · MySQL教程 · DBA实战 · mysql DBA binlog 主从复制 MySQL 8.4 复制延迟 relay log119 收藏
-
128 收藏
-
数据库 · MySQL | 3星期前 | MySQL教程 · 慢查询治理 · 索引优化 · 分区表 · DBA实战 · mysql 分区表 慢查询 索引优化 MySQL 8.4 partition pruning133 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习