Java Stream 订单列表处理流程:从过滤、分组到金额汇总
来源:17golang原创
时间:2026-06-18 14:01:03 455浏览 收藏
在后台接口里,订单列表统计很常见:先按时间和状态筛选,再按渠道分组,最后算出订单数和金额汇总。很多同学一开始会把所有逻辑堆在一条 Stream 链上,代码看起来很短,但字段口径、空值、金额精度和结果校验都容易被藏起来。
这篇文章按一个可复用的工作流来写:先把目标边界说清楚,再拆成数据入口、过滤映射、分组汇总、结果校验几个阶段。读完后,你可以把类似的列表统计代码写得更稳,也更方便后续维护。
- 目标和边界:先确定统计口径
- 全流程总览:订单列表到渠道汇总
- 阶段一:准备输入模型和返回模型
- 阶段二:过滤无效订单并统一字段
- 阶段三:按渠道分组并汇总金额
- 阶段四:校验结果和处理边界场景
- 我的推荐流程
- 常见误区
- 速查表
目标和边界:先确定统计口径
本文的目标不是讲 Stream 的所有语法,而是完成一个典型后端统计任务:给定一批订单,筛出指定日期内已支付的订单,按渠道汇总订单数和金额。
先把边界定清楚,代码会简单很多:
- 只统计
PAID状态的订单。 - 金额使用
BigDecimal,避免浮点误差。 - 渠道为空时统一归到
UNKNOWN。 - 日期区间采用左闭右开,避免跨天边界重复统计。
- 返回结果按金额从高到低排序,方便前端展示。
这里最重要的是“先定口径,再写链式调用”。如果过滤条件和字段修正散落在不同位置,后面排查统计差异会很费劲。
全流程总览:订单列表到渠道汇总
整体流程可以拆成四步:输入列表、过滤订单、分组汇总、输出结果。每一步都有自己的检查点,不建议把所有判断都压进一个难读的表达式里。
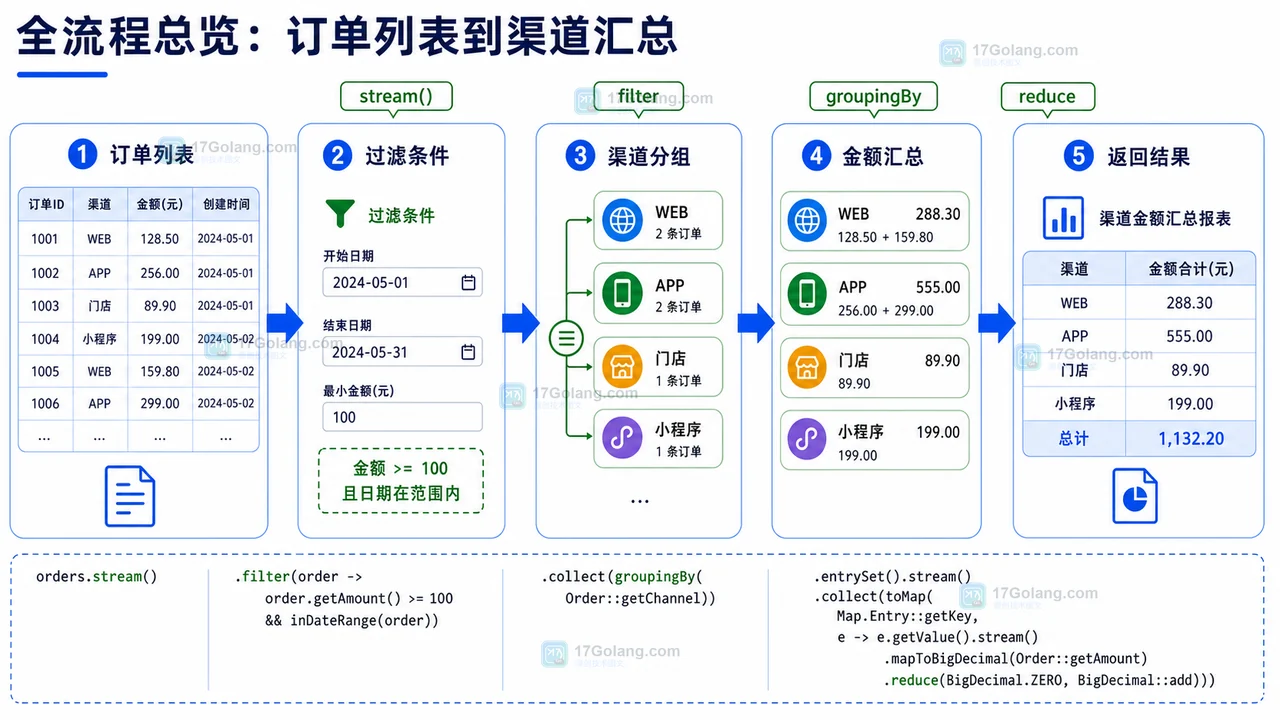
| 阶段 | 目标 | 关键动作 | 检查点 |
|---|---|---|---|
| 输入模型 | 让字段含义明确 | 定义订单字段和汇总字段 | 状态、金额、渠道、日期都能表达业务口径 |
| 过滤映射 | 只留下要统计的数据 | 过滤状态、日期,修正渠道 | 无效数据不会进入汇总 |
| 分组汇总 | 按渠道算订单数和金额 | 使用 groupingBy 加自定义汇总 |
金额精度正确,空组处理清楚 |
| 结果校验 | 保证返回稳定 | 排序、补默认值、检查合计 | 前端拿到的结构稳定可展示 |
阶段一:准备输入模型和返回模型
先准备两个模型:一个表示原始订单,一个表示渠道汇总。示例用 record 写法,项目里也可以换成普通类。
import java.math.BigDecimal;
import java.time.LocalDate;
record Order(
String id,
String channel,
String status,
BigDecimal amount,
LocalDate createdAt
) {}
record ChannelSummary(
String channel,
long orderCount,
BigDecimal totalAmount
) {}
这个阶段的检查点很简单:统计所需字段必须在模型中清晰表达。不要等到写 Stream 时才临时拼字段,否则链路会变得难读。
阶段二:过滤无效订单并统一字段
过滤阶段建议单独写成方法。这样做的好处是口径集中,后面改状态、日期边界或渠道兜底时,不需要在长链式调用里来回找。
import java.time.LocalDate;
static boolean shouldCount(Order order, LocalDate start, LocalDate end) {
if (order == null || order.amount() == null || order.createdAt() == null) {
return false;
}
boolean paid = "PAID".equals(order.status());
boolean inRange = !order.createdAt().isBefore(start)
&& order.createdAt().isBefore(end);
return paid && inRange;
}
static String safeChannel(String channel) {
if (channel == null || channel.isBlank()) {
return "UNKNOWN";
}
return channel.trim();
}
这里不要急着分组。先确认过滤条件独立可读,后面的聚合才不会混入不该统计的数据。
阶段三:按渠道分组并汇总金额
真正汇总时,可以先分组,再把每组转换成 ChannelSummary。这样代码比嵌套收集器更直观,适合业务代码阅读。
import java.math.BigDecimal; import java.time.LocalDate; import java.util.Comparator; import java.util.List; import java.util.Map; import java.util.stream.Collectors; static ListsummarizeByChannel( List orders, LocalDate start, LocalDate end ) { Map > grouped = orders.stream() .filter(order -> shouldCount(order, start, end)) .collect(Collectors.groupingBy(order -> safeChannel(order.channel()))); return grouped.entrySet().stream() .map(entry -> { BigDecimal total = entry.getValue().stream() .map(Order::amount) .reduce(BigDecimal.ZERO, BigDecimal::add); return new ChannelSummary(entry.getKey(), entry.getValue().size(), total); }) .sorted(Comparator.comparing(ChannelSummary::totalAmount).reversed()) .toList(); }
这段写法把“按什么分组”和“怎么算汇总”拆开了。业务变复杂时,比如要同时统计退款金额、客单价或渠道占比,也可以在 map 阶段继续扩展。

阶段四:校验结果和处理边界场景
统计代码上线后,最容易出问题的不是语法,而是边界。建议至少补三类检查:
- 空列表:返回空结果,而不是抛出空指针。
- 空渠道:统一进入
UNKNOWN,不要让前端收到多个空值形态。 - 金额合计:分组后的总金额应等于过滤后订单金额合计。
static BigDecimal sumAmount(Listorders, LocalDate start, LocalDate end) { return orders.stream() .filter(order -> shouldCount(order, start, end)) .map(Order::amount) .reduce(BigDecimal.ZERO, BigDecimal::add); } static BigDecimal sumSummary(List summaries) { return summaries.stream() .map(ChannelSummary::totalAmount) .reduce(BigDecimal.ZERO, BigDecimal::add); }
如果两个合计对不上,优先检查日期边界、订单状态和渠道归并。很多统计差异都来自这些不起眼的口径细节。
我的推荐流程
- 先写清楚统计目标:按什么过滤、按什么分组、返回什么字段。
- 用模型承载口径,不要把业务含义藏在字符串和临时变量里。
- 把过滤条件拆成方法,保证每个条件都能单独阅读和测试。
- 先分组,再汇总,复杂场景下比一条超长收集器更容易维护。
- 最后做合计检查和空值检查,确保返回结构稳定。
常见误区
误区一:为了短而写成一条长链
Stream 的优势不是“越短越好”,而是把数据流向表达清楚。如果一条链里同时有过滤、分组、金额修正、排序和默认值处理,后面排查口径时会很痛苦。
误区二:金额用 double 汇总
订单金额建议使用 BigDecimal。哪怕示例数据很小,也不要在金额统计里使用浮点数凑合。
误区三:忽略日期区间边界
日期区间最好统一成左闭右开,比如 2026-06-01 到 2026-07-01。这样月度、周度和日度统计更容易拼接,不容易重复计算边界日。
速查表
| 问题 | 推荐做法 | 检查点 |
|---|---|---|
| 过滤条件变多 | 拆成独立方法 | 每个条件都能被单独验证 |
| 渠道为空 | 统一归到 UNKNOWN |
前端展示不会出现多个空值形态 |
| 金额汇总 | 使用 BigDecimal |
分组总额和过滤后总额一致 |
| 结果顺序 | 返回前排序 | 接口结果稳定,便于页面展示 |
总结一下,Java Stream 写订单统计时,真正关键的是把数据处理流程拆清楚:输入模型、过滤口径、分组汇总、结果校验。只要这四步稳定,代码既能保持简洁,也能在业务变化时稳稳接住。
-
479 收藏
-
337 收藏
-
128 收藏
-
149 收藏
-
202 收藏
-
136 收藏
-
304 收藏
-
182 收藏
-
文章 · java教程 | 1星期前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95255 收藏
-
文章 · java教程 | 1星期前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签488 收藏
-
文章 · java教程 | 2星期前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰394 收藏
-
355 收藏
-
495 收藏
-
365 收藏
-
文章 · java教程 | 3星期前 | hashmap · 集合 · Java教程 · hashCode · equals · java HashMap map equals hashCode 可变key474 收藏
-
178 收藏
-
文章 · java教程 | 3星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存236 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习