Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
来源:17golang原创
时间:2026-06-16 13:01:43 236浏览 收藏
在 Java 项目里,我们经常会写这种代码:先从 Map 里取值,取不到就查数据库或远程接口,然后再 put 回缓存。代码不难,但写多了会出现两个问题:判断重复、边界不清楚。尤其当加载结果可能为空,或者多个线程同时请求同一个 key 时,问题会被放大。
这篇文章不把 computeIfAbsent 当成语法糖来讲,而是按一次缓存初始化流程来拆:什么时候适合用、怎么替换老写法、空值怎么处理、并发环境该选什么 Map,最后给一份上线前检查清单。
摘要
computeIfAbsent 适合“key 不存在时才加载并写入”的场景。它能减少 get、判空、put 的重复代码,但它不是万能缓存框架:加载函数返回 null 时不会写入缓存;普通 HashMap 不能解决并发安全;加载逻辑也要避免副作用过重。
适合人群
- 已经会使用
Map,但想把缓存初始化代码写得更稳的 Java 开发者。 - 遇到过缓存击穿、重复加载、空值反复查询等问题的后端开发者。
- 想分清
HashMap、ConcurrentHashMap和Optional在缓存场景里各自边界的读者。
- 目标和边界
- 全流程总览
- 阶段一:先确认 key 和 value 生命周期
- 阶段二:用 computeIfAbsent 替换手写判断
- 阶段三:处理返回 null 的加载结果
- 阶段四:并发场景选择 ConcurrentHashMap
- 我的推荐流程
- 常见误区
- 落地清单
目标和边界
本文的目标很明确:完成一个“用户资料缓存”的初始化流程。请求里拿到 userId,先查本地 Map;如果没有,再调用加载函数;加载成功后写回 Map 并返回。
这个边界也要先说清楚:computeIfAbsent 只解决“缺失时计算并放入 Map”的这一步,它不负责分布式缓存、不负责自动过期、不负责跨进程一致性。如果你需要 TTL、淘汰策略、统计命中率,应该继续引入 Caffeine、Redis 或业务侧缓存组件。
全流程总览
我们先看一张流程图。核心链路其实很短:请求带着 id 进入,Map 先判断是否命中;未命中时才加载数据;加载成功后写回并返回给调用方。
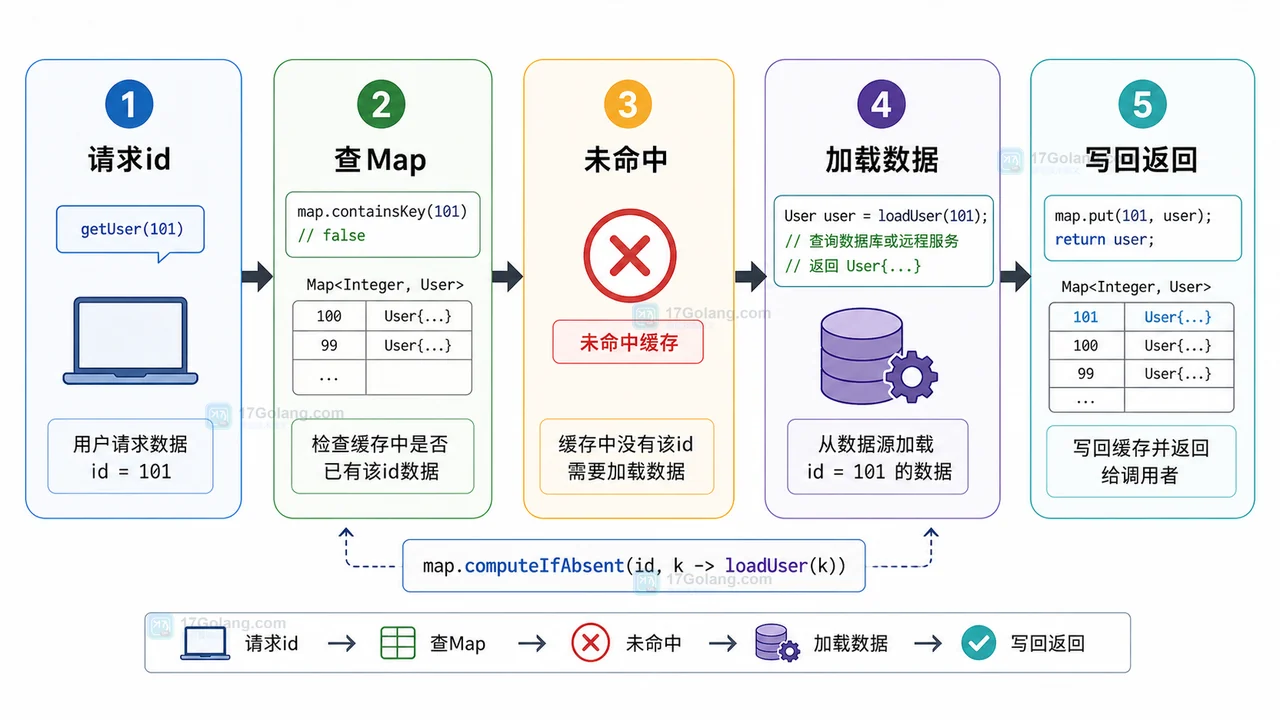
| 阶段 | 目标 | 关键动作 | 检查点 |
|---|---|---|---|
| 确认缓存对象 | 知道 key 和 value 表示什么 | 定义 key 类型、value 类型、生命周期 | 同一个 key 是否稳定命中同一份数据 |
| 缺失加载 | 减少重复判断 | 使用 computeIfAbsent |
加载函数只在缺失时触发 |
| 空值策略 | 避免反复查询不存在数据 | 使用 Optional 或负缓存对象 |
不存在的数据是否也有明确缓存策略 |
| 并发保护 | 避免多线程下状态混乱 | 选择 ConcurrentHashMap |
同一个 key 下是否只产生可预期的加载行为 |
阶段一:先确认 key 和 value 生命周期
写缓存前先问三个问题,比直接上代码更重要。
- key 是否稳定:例如用户资料可以用
Long userId,不要混入时间戳、随机数或临时上下文。 - value 是否可复用:如果每次请求都需要重新计算权限、地区、语言包,就不要把完整响应对象盲目缓存。
- 数据多久会变:如果资料变更频繁,需要额外的失效策略;如果只是进程内短期缓存,可以先控制范围。
这里我们假设 UserProfile 是一个相对稳定的用户资料对象,适合在当前进程内缓存一段时间。
阶段二:用 computeIfAbsent 替换手写判断
很多老代码会写成这样:
Mapcache = new HashMap(); UserProfile profile = cache.get(userId); if (profile == null) { profile = loadUserProfile(userId); cache.put(userId, profile); }
这段代码的行为很直观,但重复出现以后会拖慢阅读速度。更紧凑的写法是:
Mapcache = new HashMap(); UserProfile profile = cache.computeIfAbsent( userId, id -> loadUserProfile(id) );
这段代码表达了一个完整语义:如果 userId 对应的值不存在,就调用加载函数,并把结果作为缓存值。读代码的人不需要再在 get、判空、put 之间来回确认意图。
检查点很简单:加载函数不要偷偷修改同一个 Map,也不要混入和缓存无关的副作用。它最好只做一件事:根据 key 返回 value。
阶段三:处理返回 null 的加载结果
这里是 computeIfAbsent 最容易被误解的地方:如果加载函数返回 null,Map 不会写入这个 key。下一次请求同一个 key 时,它仍然会被视为未命中,然后再次调用加载函数。
Mapcache = new HashMap(); String value = cache.computeIfAbsent("k1", key -> loadMaybeNull(key)); // 如果 loadMaybeNull 返回 null,cache 里仍然没有 k1。
如果“查不到数据”是正常业务结果,就要把“没有值”也表达成一个可缓存的值。常见做法是使用 Optional:
Map> cache = new HashMap(); Optional profile = cache.computeIfAbsent( userId, id -> Optional.ofNullable(loadUserProfile(id)) );
这样就把两种状态分开了:key 没有出现,表示还没加载;key 出现但值是 Optional.empty(),表示加载过但没有用户资料。这个区别在减少重复查询时很有用。
阶段四:并发场景选择 ConcurrentHashMap
如果这个缓存只在单线程脚本里用,HashMap 可以满足基本演示。但在 Web 服务里,同一个缓存通常会被多个请求线程访问,此时应该换成 ConcurrentHashMap。
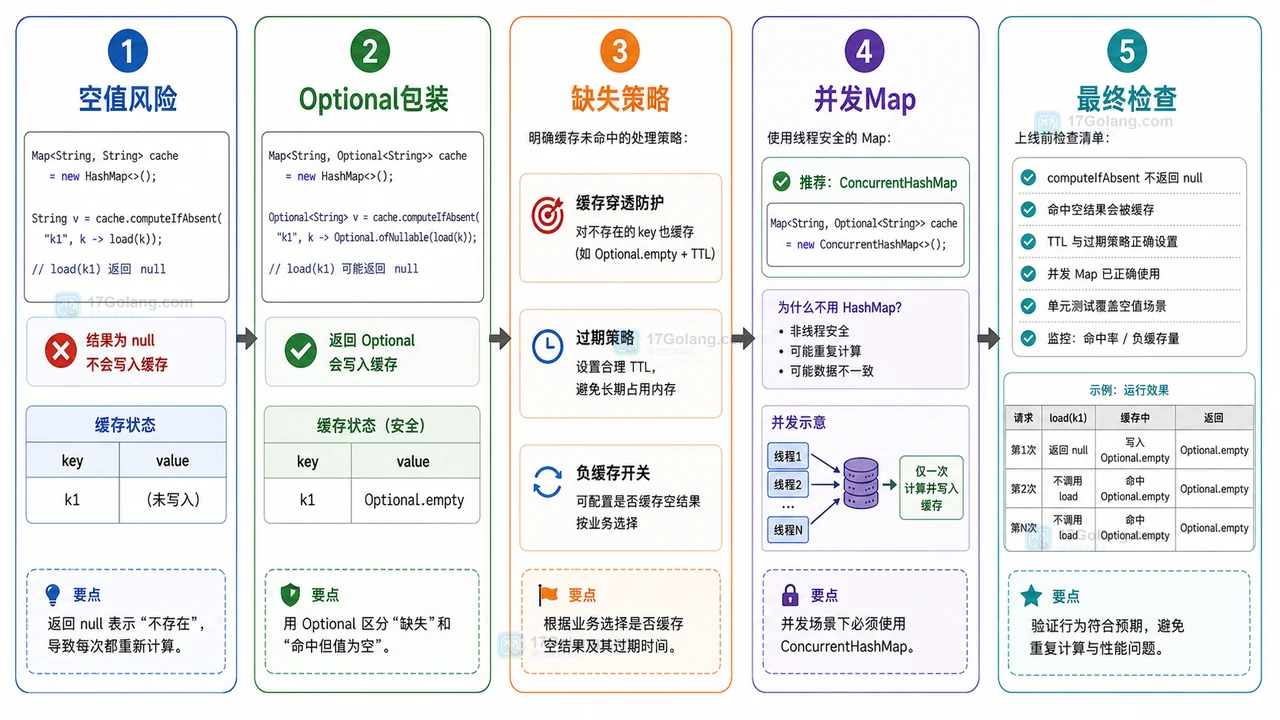
Map> cache = new ConcurrentHashMap(); Optional profile = cache.computeIfAbsent( userId, id -> Optional.ofNullable(loadUserProfile(id)) );
这里的检查点有两个:
- 加载函数要尽量短,不要在里面再改同一个 Map。
- 如果加载过程很慢,要结合业务限流、超时和降级策略,不能只指望 Map 帮你兜底。
我的推荐流程
把上面的内容整理成一个可复用流程,就是下面这几步。
- 先确认 key 是否稳定,value 是否值得缓存。
- 如果只是单线程临时缓存,可以用
HashMap验证逻辑。 - 如果在服务端共享缓存,直接使用
ConcurrentHashMap。 - 如果加载结果可能为空,不要直接缓存原始 value,改用
Optional或业务定义的空对象。 - 把加载函数保持为纯粹的 key 到 value 转换,减少隐藏副作用。
- 上线前补一个命中、未命中、空结果和并发访问的测试。
常见误区
误区一:以为返回 null 也会缓存
不会。返回 null 时,这个 key 不会写入 Map。后续请求会再次触发加载逻辑。需要缓存“查不到”这个状态时,应该显式包装。
误区二:以为 computeIfAbsent 等于完整缓存方案
它只是 Map 的缺失初始化方法,不提供 TTL、容量控制、淘汰策略和跨节点同步。业务复杂后要引入专门缓存组件。
误区三:并发环境还使用普通 HashMap
普通 HashMap 不适合多线程共享写入。服务端缓存至少要使用 ConcurrentHashMap,并配合业务侧的加载保护。
落地清单
| 检查项 | 建议 |
|---|---|
| key 设计 | 使用稳定业务 id,避免临时上下文进入 key。 |
| value 设计 | 缓存稳定对象,不缓存每次请求都变化的临时响应。 |
| 空值处理 | 使用 Optional 或空对象表达“查过但没有”。 |
| 并发 Map | 服务端共享缓存优先使用 ConcurrentHashMap。 |
| 测试场景 | 覆盖命中、未命中、空结果和多线程访问。 |
总结
computeIfAbsent 最适合表达“缺失时加载并写入”这个意图。写得好,它可以让缓存初始化代码更短、更清楚;写得随意,它也会把空值、并发和副作用问题藏起来。
我的建议是:先定清楚 key 和 value,再用 computeIfAbsent 简化缺失加载;遇到空结果时显式包装;进入多线程服务端场景后使用 ConcurrentHashMap。这样写出来的缓存代码既不绕,也更容易被下一位维护者读懂。
-
182 收藏
-
文章 · java教程 | 6天前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95255 收藏
-
文章 · java教程 | 1星期前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签488 收藏
-
文章 · java教程 | 1星期前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰394 收藏
-
355 收藏
-
495 收藏
-
365 收藏
-
455 收藏
-
文章 · java教程 | 2星期前 | hashmap · 集合 · Java教程 · hashCode · equals · java HashMap map equals hashCode 可变key474 收藏
-
178 收藏
-
204 收藏
-
文章 · java教程 | 3星期前 | Java · 集合 · ArrayList · Iterator · removeIf · java iterator ArrayList ConcurrentModificationException removeIf410 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习