Golang中map的深入探究
来源:脚本之家
时间:2022-12-23 17:39:51 369浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《Golang中map的深入探究》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
简介
本文主要通过探究在golang 中map的数据结构及源码实现来学习和了解map的特性,共包含map的模型探究、存取、扩容等内容。欢迎大家共同讨论。
Map 的底层内存模型
在 golang 的源码中表示 map 的底层 struct 是 hmap,其是 hashmap 的缩写
type hmap struct {
// map中存入元素的个数, golang中调用len(map)的时候直接返回该字段
count int
// 状态标记位,通过与定义的枚举值进行&操作可以判断当前是否处于这种状态
flags uint8
B uint8 // 2^B 表示bucket的数量, B 表示取hash后多少位来做bucket的分组
noverflow uint16 // overflow bucket 的数量的近似数
hash0 uint32 // hash seed (hash 种子) 一般是一个素数
buckets unsafe.Pointer // 共有2^B个 bucket ,但是如果没有元素存入,这个字段可能为nil
oldbuckets unsafe.Pointer // 在扩容期间,将旧的bucket数组放在这里, 新buckets会是这个的两倍大
nevacuate uintptr // 表示已经完成扩容迁移的bucket的指针, 地址小于当前指针的bucket已经迁移完成
extra *mapextra // optional fields
}
B 是 buckets 数组的长度的对数, 即 bucket 数组的长度是 2^B。bucket 的本质上是一个指针,指向了一片内存空间,其指向的 struct 如下所示:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}
但这只是表面(src/runtime/hashmap.go)的结构,编译期间会给它加料,动态地创建一个新的结构:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr // 内存对齐使用,可能不需要
overflow uintptr // 当bucket 的8个key 存满了之后
}
bmap 就是我们常说的“桶”的底层数据结构, 一个桶中可以存放最多 8 个 key/value, map 使用 hash 函数 得到 hash 值决定分配到哪个桶, 然后又会根据 hash 值的高 8 位来寻找放在桶的哪个位置 具体的 map 的组成结构如下图所示:
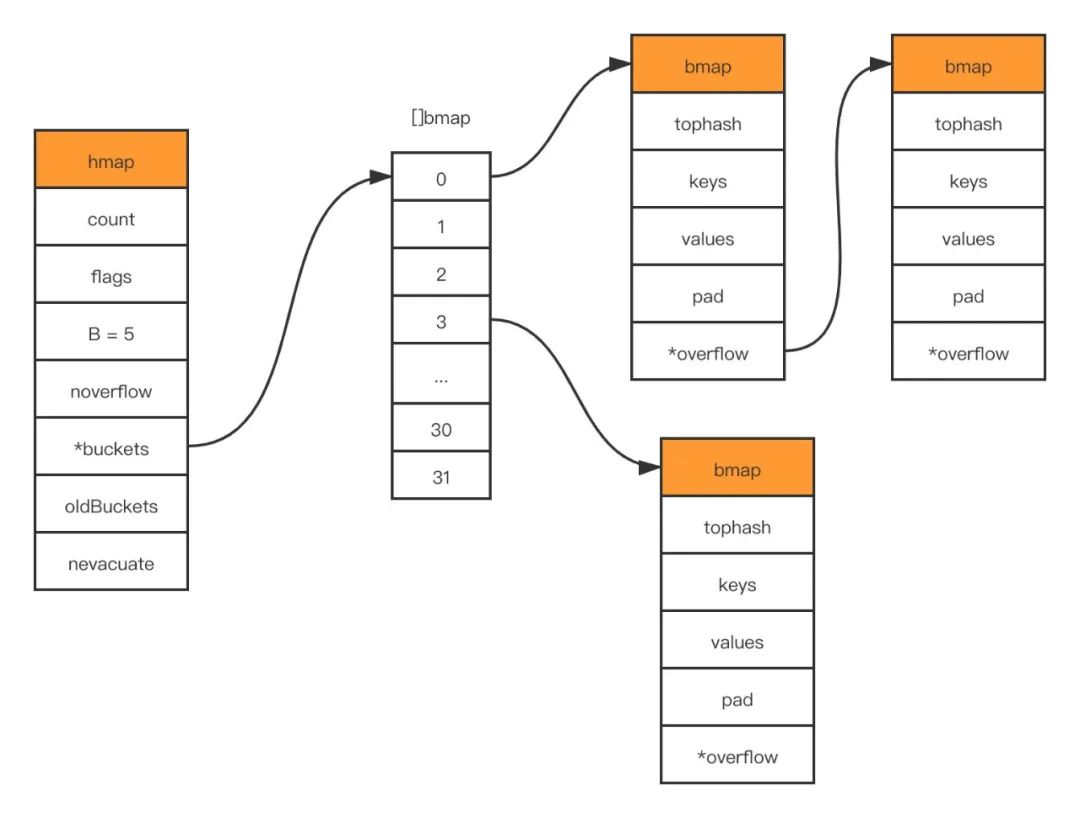
Map 的存与取
在 map 中存与取本质上都是在进行一个工作, 那就是:
- 查询当前 k/v 应该存储的位置。
- 赋值/取值, 所以我们理解了 map 中 key 的定位我们就理解了存取。
底层代码
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// map 为空,或者元素数为 0,直接返回未找到
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0]), false
}
// 不支持并发读写
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 根据hash 函数算出hash值,注意key的类型不同可能使用的hash函数也不同
hash := t.hasher(key, uintptr(h.hash0))
// 如果 B = 5,那么结果用二进制表示就是 11111 , 返回的是B位全1的值
m := bucketMask(h.B)
// 根据hash的后B位,定位在bucket数组中的位置
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
// 当 h.oldbuckets 非空时,说明 map 发生了扩容
// 这时候,新的 buckets 里可能还没有老的内容
// 所以一定要在老的里面找,否则有可能发生“消失”的诡异现象
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 说明之前只有一半的 bucket,需要除 2
m >>= 1
}
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// tophash 取其高 8bit 的值
top := tophash(hash)
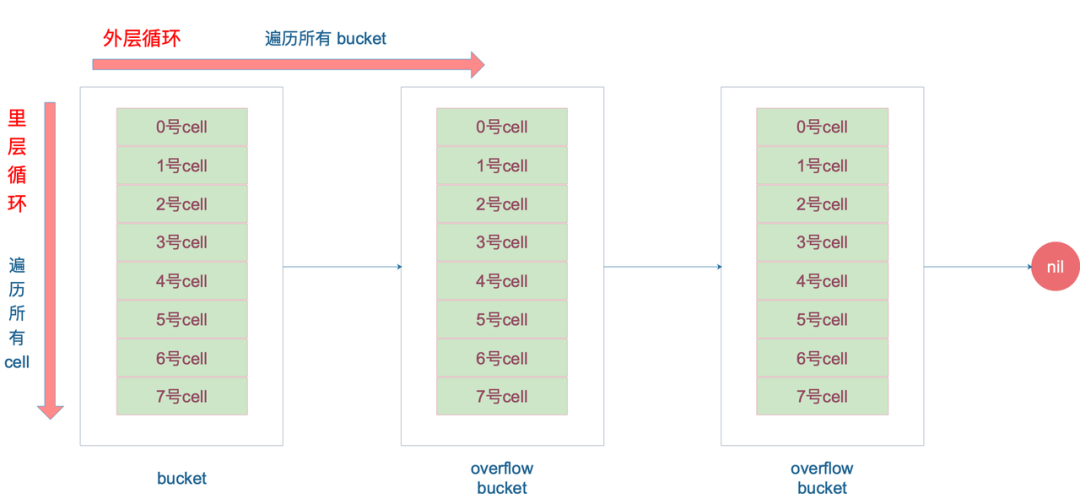
// 一个 bucket 在存储满 8 个元素后,就再也放不下了,这时候会创建新的 bucket,挂在原来的 bucket 的 overflow 指针成员上
// 遍历当前bucket的所有链式bucket
for ; b != nil; b = b.overflow(t) {
// 在bucket的8个位置上查询
for i := uintptr(0); i
寻址过程

Map 的扩容
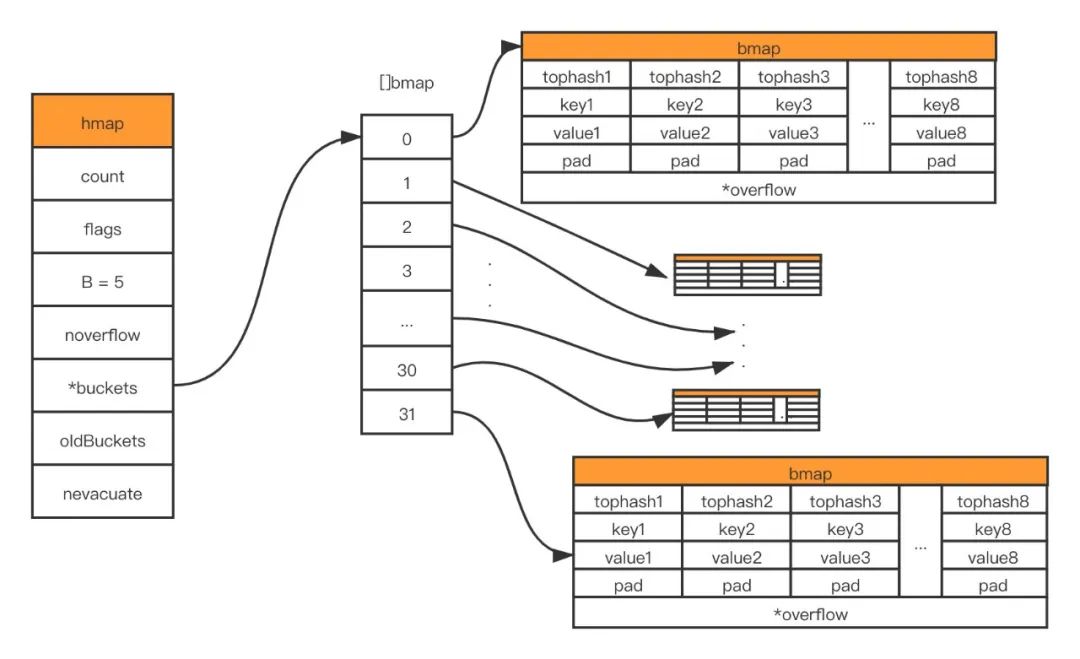
在 golang 中 map 和 slice 一样都是在初始化时首先申请较小的内存空间,在 map 的不断存入的过程中,动态的进行扩容。扩容共有两种,增量扩容与等量扩容(重新排列并分配内存)。下面我们来了解一下扩容的触发方式:
- 负载因子超过阈值,源码里定义的阈值是 6.5。(触发增量扩容)
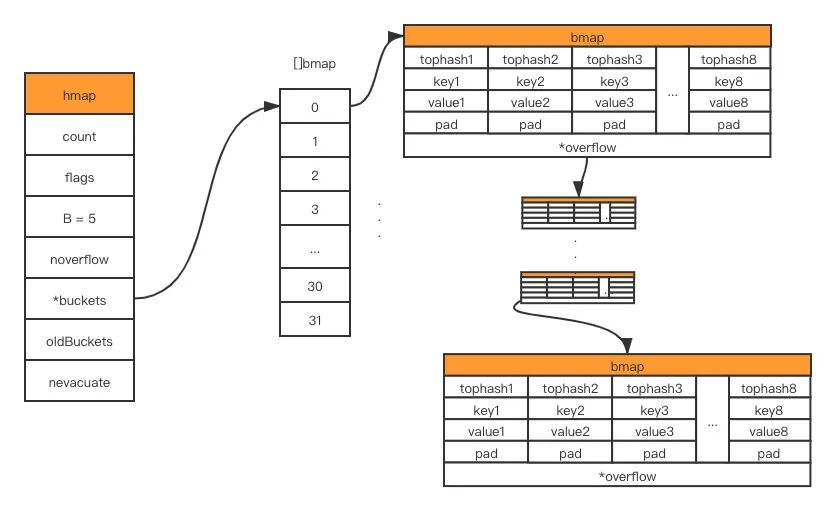
- overflow 的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。(触发等量扩容)
第一种情况
第二种情况
Map 的有序性
先说结论,在 golang 中 map 是无序的,准确的说是无法严格保证顺序的, 从上面的源码中我们可以知道,golang 中 map 在扩容后,可能会将部分 key 移至新内存,由于在扩容搬移数据过程中,并未记录原数据位置, 并且在 golang 的数据结构中也并未保存数据的顺序,所以那么这一部分在扩容后实际上就已经是无序的了。
遍历的过程,其实就是按顺序遍历内存地址,同时按顺序遍历内存地址中的 key。但这时已经是无序的了。但是如果我就一个 map,我保证不会对 map 进行修改删除等操作,那么按理说没有扩容就不会发生改变。但也是因为这样,GO 才在源码中 但是有一个有趣的现象,就算不对 map 进行插入删除等操作致使其扩容,其在遍历过程中仍是无序的。
objMap := make(map[string]int)
for i := 0; i
以上的运行结果是

不难看出,即使不对 map 进行扩容,在多次遍历时也是无序的,这是因为 golang 官方在设计时故意加上随机的元素,将遍历 map 的顺序随机化,用来防止使用者用来顺序遍历。
依赖 map 的顺序进行遍历,这是有风险的代码,在 GO 的严格语法规则下,是坚决不提倡的。所以我们在使用 map 时一定要记得其是无序的,不要依赖其顺序。
Map 的并发
首先我们大家都知道,在 golang 中 map 并不是一个并发安全的数据结构,当几个 goruotine 同时对一个 map 进行读写操作时,就会出现并发写问题:fatal error: concurrent map writes。但是为什么 map 是不支持并发安全的呢, 主要是因为成本与效益。
官方答复原因如下:
- 典型使用场景:map 的典型使用场景是不需要从多个 goroutine 中进行安全访问。
- 非典型场景(需要原子操作):map 可能是一些更大的数据结构或已经同步的计算的一部分。
性能场景考虑:若是只是为少数程序增加安全性,导致 map 所有的操作都要处理 mutex,将会降低大多数程序的性能。同时 golang 提供了并发安全的 sync map。
, // 不支持并发读写
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
但是我们又有疑问了,为什么 golang map 并发冲突了不抛一个 error 出来,或者 panic 掉,而是要让程序 panic,选择让程序 crash 崩溃掉。这里是 golang 官方出于权衡风险和 map 使用复杂度场景考虑的,首先 map 在官方中就明确表示不支持并发读写, 所以并发对 map 进行读写操作本身就是不正确的。
场景假设一:如果 map 选择在写入或者读取时增加 error 返回值,会导致程序在使用 map 时就无法像现在一样,需要额外的捕获并判断 err。
场景假设二:如果 map 选择 panic(可被 recover),此时如果出现并发写入数据的场景,就会导致走进 recover 中,如果没有对这种场景进行特殊处理,就会导致 map 中存在脏数据,此时程序在使用 map 时就会引发不可预知的错误,此时排查起来也是很难找到问题的根因的。
所以 golang 在考虑了这些场景后,选择明确的抛出 crash 崩溃异常,使得风险被提前暴露。可以明确的定位到问题点。综上所述我们在使用 map 时,已经要严格保障其是在单线程内使用的,如果有多线程场景,建议使用 sync map 。
总结
今天带大家了解了map的相关知识,希望对你有所帮助;关于Golang的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
388 收藏
-
167 收藏
-
339 收藏
-
384 收藏
-
396 收藏
-
Golang · Go教程 | 22小时前 | go · net/url · url · HTTP客户端 · 路径转义 · Go教程 url.JoinPath PathEscape RawPath URL拼接354 收藏
-
261 收藏
-
334 收藏
-
469 收藏
-
395 收藏
-
270 收藏
-
Golang · Go教程 | 2天前 | JSON · 基准测试 · go · 性能优化 · 内存分配 encoding/json json.RawMessage json.Decoder Go JSON206 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 动听的唇彩
- 这篇技术文章真是及时雨啊,很详细,受益颇多,mark,关注老哥了!希望老哥能多写Golang相关的文章。
- 2023-01-27 02:44:50
-
- 难过的牛排
- 这篇技术文章出现的刚刚好,太全面了,很有用,mark,关注博主了!希望博主能多写Golang相关的文章。
- 2023-01-01 05:52:20
-
- 文艺的小土豆
- 很详细,码住,感谢作者大大的这篇文章,我会继续支持!
- 2022-12-29 20:44:27
-
- 谦让的月饼
- 这篇文章太及时了,师傅加油!
- 2022-12-26 01:15:57
-
- 疯狂的百褶裙
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢作者分享文章!
- 2022-12-25 01:49:40
-
- 忧虑的大象
- 很详细,mark,感谢作者的这篇博文,我会继续支持!
- 2022-12-24 22:48:18
-
- 如意的黑夜
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢老哥分享技术文章!
- 2022-12-24 07:43:40
-
- 粗暴的春天
- 这篇技术文章出现的刚刚好,太细致了,很有用,已加入收藏夹了,关注up主了!希望up主能多写Golang相关的文章。
- 2022-12-24 02:00:10