Go goroutine 泄漏怎么查:pprof、context 和通道关闭检查清单
来源:17golang原创
时间:2026-06-27 18:42:53 392浏览 收藏
Go 服务运行一段时间后,内存没有明显暴涨,但请求越来越慢,发布前压测正常,线上监控里 goroutine 数量却持续上涨。这类问题通常不是“GC 不工作”,而是某些 goroutine 卡在通道收发、网络读取、定时器等待或没有收到取消信号。
本文按调试检查清单的结构排查:先确认现象,再分层检查 runtime 指标、pprof 栈、通道和 context,最后给出修复动作与反向验证方法。
- 现象:goroutine 数量只涨不降
- 分层检查:先看趋势,再看阻塞位置
- 证据判断:哪些栈是真泄漏
- 修复动作:取消、关闭和超时必须成对出现
- 反向验证:修复后怎么确认真的下降
- 排查清单:上线前逐项过一遍
现象:goroutine 数量只涨不降
正常服务的 goroutine 数量会随流量波动,但不应该在流量下降后仍持续上升。一个典型症状是:压测开始后数量快速上涨,压测停止十几分钟后仍然维持高位,甚至下一轮压测继续叠加。
package main
import (
"fmt"
"runtime"
"time"
)
func printGoroutines() {
ticker := time.NewTicker(10 * time.Second)
defer ticker.Stop()
for range ticker.C {
fmt.Println("goroutines:", runtime.NumGoroutine())
}
}
这个数字只能说明趋势,不能直接说明原因。真正定位要看 goroutine profile:它会告诉我们大量 goroutine 卡在哪个函数、哪一行、哪类等待状态。
分层检查:先看趋势,再看阻塞位置
排查顺序建议从轻到重:先看数量趋势,再采样 pprof,最后回到代码链路检查取消和关闭边界。不要一上来盲改代码,否则容易把真正的阻塞点藏起来。
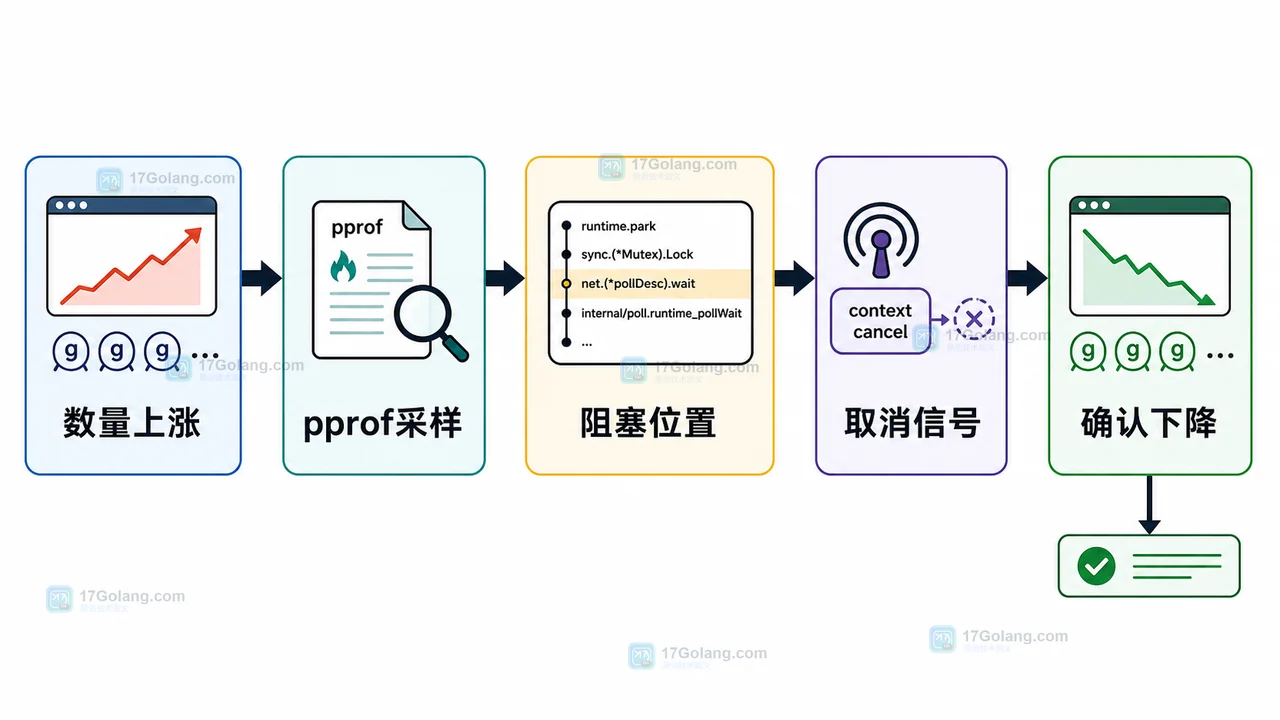
第一层:runtime 指标
先确认数量是不是持续上涨,以及上涨是否和某类请求、定时任务、消息消费有关。可以在日志或指标系统中记录 runtime.NumGoroutine(),也可以接入已有监控。
第二层:pprof 栈
服务已开启 pprof 时,可以拉取 goroutine 栈:
curl "http://127.0.0.1:6060/debug/pprof/goroutine?debug=2" > goroutine.txt
重点看重复出现最多的栈。如果几千个 goroutine 都停在同一处 chan receive、select、HTTP 读取或数据库等待,就要沿着这条调用链回查。
第三层:业务边界
找到阻塞位置后,检查三个边界:上游是否会取消、下游是否有超时、通道是否有关闭规则。goroutine 泄漏通常不是单行代码造成的,而是启动和退出没有成对设计。
证据判断:哪些栈是真泄漏
并不是所有等待中的 goroutine 都有问题。HTTP 服务的 worker、连接池维护任务、指标采集任务都可能长期存在。判断是否泄漏,要看“数量是否随请求累积”和“请求结束后是否没有退出路径”。
goroutine 8123 [chan receive]:
main.watchOrder(...)
/app/order_watch.go:42
main.handleOrder.func1()
/app/order_handler.go:88
上面这种栈值得重点检查:如果每个请求都启动一个 watchOrder,但请求结束后没有取消信号,也没有关闭输入通道,那么请求越多,残留 goroutine 越多。
常见判断规则:
- 同一业务函数重复成百上千次,优先怀疑泄漏。
- 栈顶是
chan receive或chan send,检查通道另一端是否一定存在。 - 栈顶是网络或数据库读取,检查是否设置超时和上下文取消。
- 栈里能看到请求处理函数,检查请求结束后子 goroutine 是否退出。
修复动作:取消、关闭和超时必须成对出现
修复方向通常有三个:用 context 传递取消信号;由生产者关闭通道;给外部调用设置超时。下面是一个容易泄漏的写法:
func handle(reqID string, jobs
如果 jobs 永远不关闭,或者请求结束后仍没有退出条件,内部 goroutine 会一直等。更稳的写法是把请求上下文传进去,并在 select 里监听取消:
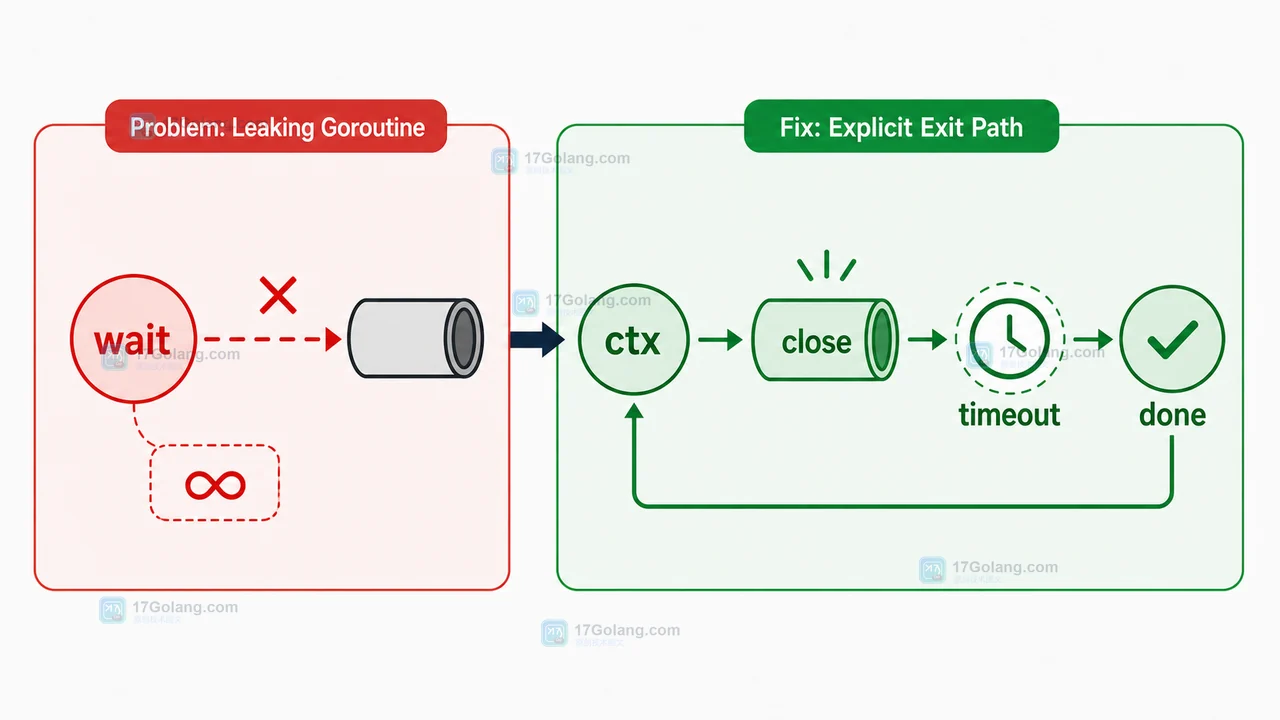
func handle(ctx context.Context, reqID string, jobs
如果需要等待一组 goroutine 退出,可以配合 sync.WaitGroup。注意不要只加 WaitGroup,却不给 goroutine 退出条件;那只是把泄漏换成等待卡住。
反向验证:修复后怎么确认真的下降
修复不是看到代码里有 ctx.Done() 就结束。还要反向验证:制造请求、停止请求、等待一段时间,再看 goroutine 数量和 profile 是否回落。
压测前:goroutines = 42 压测中:goroutines = 830 停止 30 秒后:goroutines = 58 停止 2 分钟后:goroutines = 45
同时重新拉取 goroutine profile,确认原来重复最多的业务栈已经消失。如果数量下降但栈还在,说明还有其他入口会触发同样问题;如果栈消失但数量不降,继续看下一批重复栈。
排查清单:上线前逐项过一遍
- 请求结束后,子 goroutine 是否能收到
context取消信号。 - 读取通道时,是否处理了通道关闭后的
ok == false。 - 写入通道时,是否存在无人读取导致永久阻塞的路径。
- HTTP、数据库、RPC 调用是否设置了超时。
- 定时器、ticker 是否在退出时停止。
- 后台任务是否有明确生命周期,而不是在每次请求里重复启动。
- 修复后是否做过“压测停止后数量回落”的反向验证。
总结一下,goroutine 泄漏排查不要只盯内存。先看数量趋势,再用 pprof 找重复栈,最后检查取消、关闭、超时三类退出边界。只要每个启动点都有对应的退出路径,Go 并发代码就会稳定很多。
-
100 收藏
-
101 收藏
-
101 收藏
-
101 收藏
-
101 收藏
-
418 收藏
-
Golang · Go教程 | 1星期前 | goroutine · Context · 超时控制 · Go教程 · 后端开发 · Go Goroutine context 超时控制 WithTimeout Done QueryContext166 收藏
-
Golang · Go教程 | 1星期前 | WaitGroup · channel · 并发编程 · 优雅关闭 · Go教程 · WaitGroup Channel关闭 Go channel 并发收尾 done信号165 收藏
-
332 收藏
-
115 收藏
-
Golang · Go教程 | 1星期前 | errgroup · go · Context · 并发编程 · SetLimit · Go 并发任务 errgroup SetLimit context取消301 收藏
-
Golang · Go教程 | 1星期前 | map · 并发安全 · RWMutex · sync.Map · Go教程 · 并发安全 RWMutex sync.Map Go map并发读写 go test race272 收藏
-
114 收藏
-
458 收藏
-
501 收藏
-
413 收藏
-
484 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习