AI 聊天流式输出前端配方:用 Fetch Stream 实现逐字渲染和中断控制
来源:17golang原创
时间:2026-06-28 11:50:24 448浏览 收藏
AI 聊天界面如果等服务端一次性返回完整答案,用户会明显感觉“卡住了”。更自然的体验是服务端边生成边返回,前端边收到边渲染:第一个字尽快出现,后续内容持续追加,并且用户可以随时停止。
这篇文章给一个前端配方:用 fetch 读取响应体的 ReadableStream,用 TextDecoder 把字节块转成文本,再把文本追加到聊天气泡里。它不绑定具体模型厂商,适合接入任何能按块返回文本的 AI 聊天接口。
- 问题:AI 回复为什么要流式显示
- 最小配方:Fetch Stream 逐段读取
- 关键 JS:解码、追加和停止
- 变体:什么时候改用 SSE
- 兼容坑:代理缓冲、编码和错误状态
- 完整片段:一个可粘贴的聊天面板
问题:AI 回复为什么要流式显示
普通接口通常是“请求 -> 等待 -> 完整响应”。AI 聊天则不同:答案可能很长,生成过程也可能持续几秒到几十秒。如果只在最后更新界面,用户不知道系统是否还在工作,也不能及时停止。
流式输出要解决三个体验问题:
- 首字延迟:尽快显示第一段内容,让用户知道请求已开始产生结果。
- 连续反馈:每收到一小段就追加,减少等待焦虑。
- 可中断:用户发现问题问错了,可以立刻停止当前生成。
前端链路可以理解成下图:请求发出后,响应体不是一次性字符串,而是一串逐步到达的数据块。
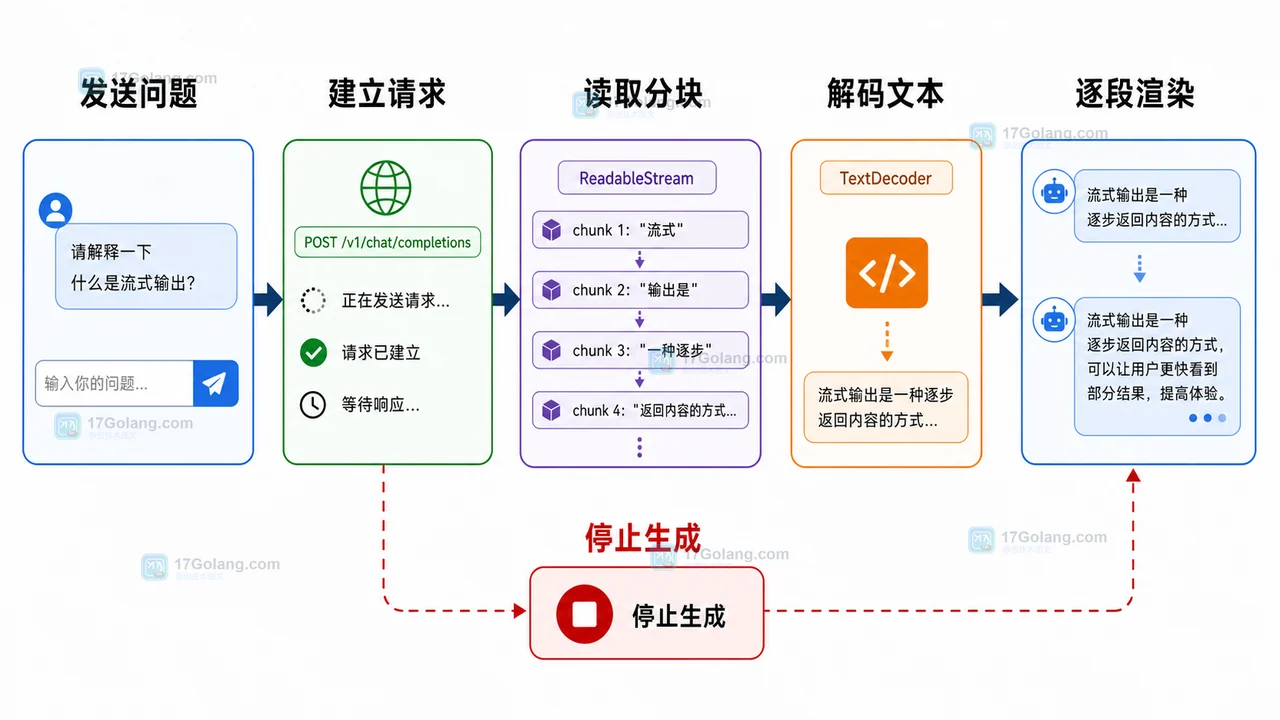
最小配方:Fetch Stream 逐段读取
浏览器里的 Response.body 可以暴露为可读流。最小实现步骤是:拿到响应体,创建 reader,不断读取 chunk,用解码器转成文本,然后追加到页面。
async function streamChat(prompt, outputEl) {
const response = await fetch("/api/ai/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ prompt })
});
if (!response.ok || !response.body) {
throw new Error("stream response failed");
}
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
while (true) {
const { value, done } = await reader.read();
if (done) break;
outputEl.textContent += decoder.decode(value, { stream: true });
}
outputEl.textContent += decoder.decode();
}
这段代码的重点不是“逐字”,而是“逐块”。服务端每次推多少,前端就收到多少。真实产品里可以在服务端控制 chunk 粒度,前端负责稳定追加和状态管理。
关键 JS:解码、追加和停止
最小配方能跑,但产品界面还需要停止按钮。这里用 AbortController 控制当前请求,停止时取消 fetch,避免旧回答继续写入界面。
let currentController = null;
async function startChat(prompt, outputEl, statusEl) {
currentController = new AbortController();
outputEl.textContent = "";
statusEl.textContent = "生成中";
try {
const response = await fetch("/api/ai/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ prompt }),
signal: currentController.signal
});
if (!response.ok || !response.body) {
throw new Error("bad stream");
}
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { value, done } = await reader.read();
if (done) break;
outputEl.textContent += decoder.decode(value, { stream: true });
}
outputEl.textContent += decoder.decode();
statusEl.textContent = "完成";
} catch (err) {
statusEl.textContent = currentController.signal.aborted ? "已停止" : "失败";
} finally {
currentController = null;
}
}
function stopChat() {
if (currentController) {
currentController.abort();
}
}
这里有两个关键点:第一,decoder.decode(value, { stream: true }) 用于处理分块边界,避免多字节字符被拆开时显示异常;第二,停止按钮不要只改界面状态,必须真的中断请求。
变体:什么时候改用 SSE
如果服务端本来就是按事件推送,例如每条消息都有 event、data、id 这样的字段,可以考虑 SSE。它通过 EventSource 建立连接,服务端以 text/event-stream 格式持续推送。
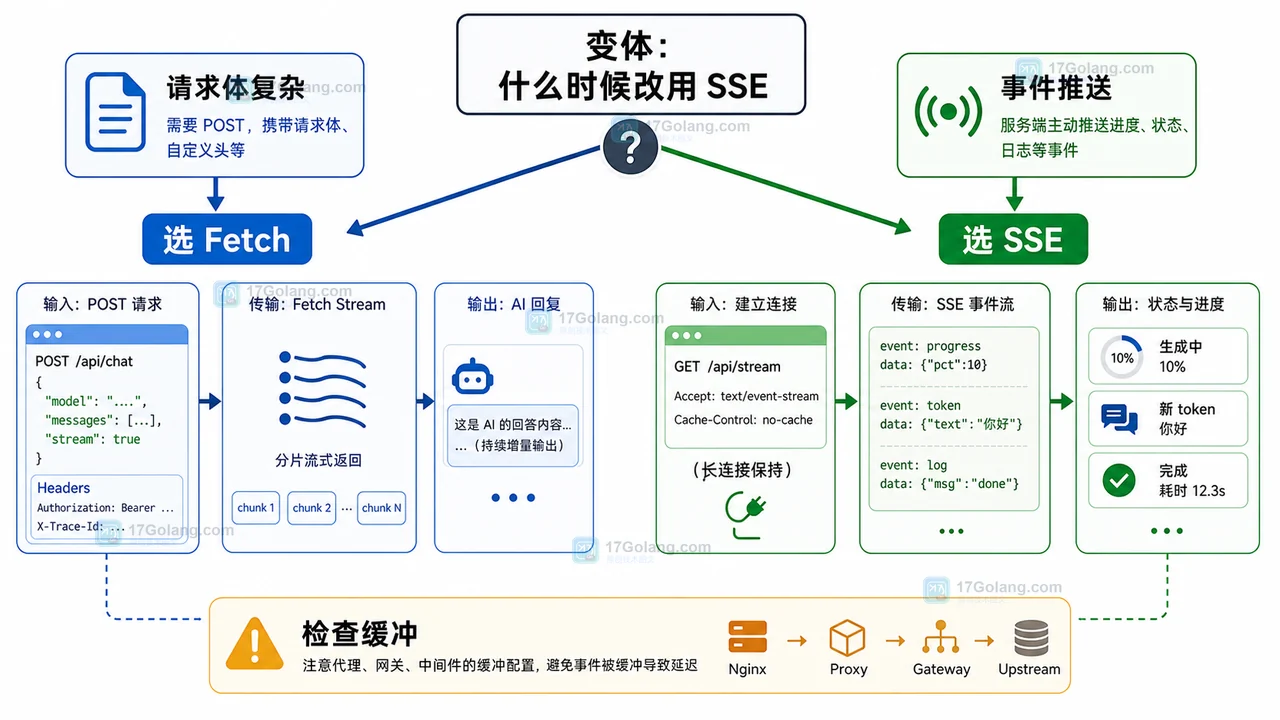
| 方案 | 适合场景 | 注意点 |
|---|---|---|
| Fetch Stream | POST 请求、需要自定义请求体、聊天生成 | 自己处理分块、解码和中断 |
| SSE | 服务端持续推事件、状态通知、日志流 | 常见用法偏 GET,需要按事件格式输出 |
AI 聊天如果需要携带复杂请求体和鉴权头,Fetch Stream 通常更直接;如果是任务状态、通知、排队进度这类单向推送,SSE 的事件模型更清晰。
兼容坑:代理缓冲、编码和错误状态
流式输出最常见的问题不是前端代码写错,而是链路中间某一层把响应缓冲了:
- 代理缓冲:Nginx、网关或平台代理可能把小块攒起来再发,导致前端看起来不是流式。
- 响应头:服务端应设置合适的文本类型,并避免一次性压缩导致浏览器迟迟拿不到块。
- 编码边界:用
TextDecoder的流式模式处理 UTF-8 分块。 - 错误状态:先检查
response.ok,不要把错误页当成 AI 内容追加。 - 旧请求串写:新问题发送后,要中断旧请求或给请求编号,避免旧答案写进新气泡。
完整片段:一个可粘贴的聊天面板
下面是一个最小页面片段,后端只要提供 /api/ai/chat 并按文本块返回,就能看到逐段追加效果。
空闲
这套配方的核心是把 AI 回复当作“连续到达的数据块”,而不是一次性字符串。前端做好读取、解码、追加、中断和错误状态,聊天体验就会从“等完整答案”变成“边生成边反馈”。
-
101 收藏
-
117 收藏
-
119 收藏
-
122 收藏
-
130 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 2星期前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习