-
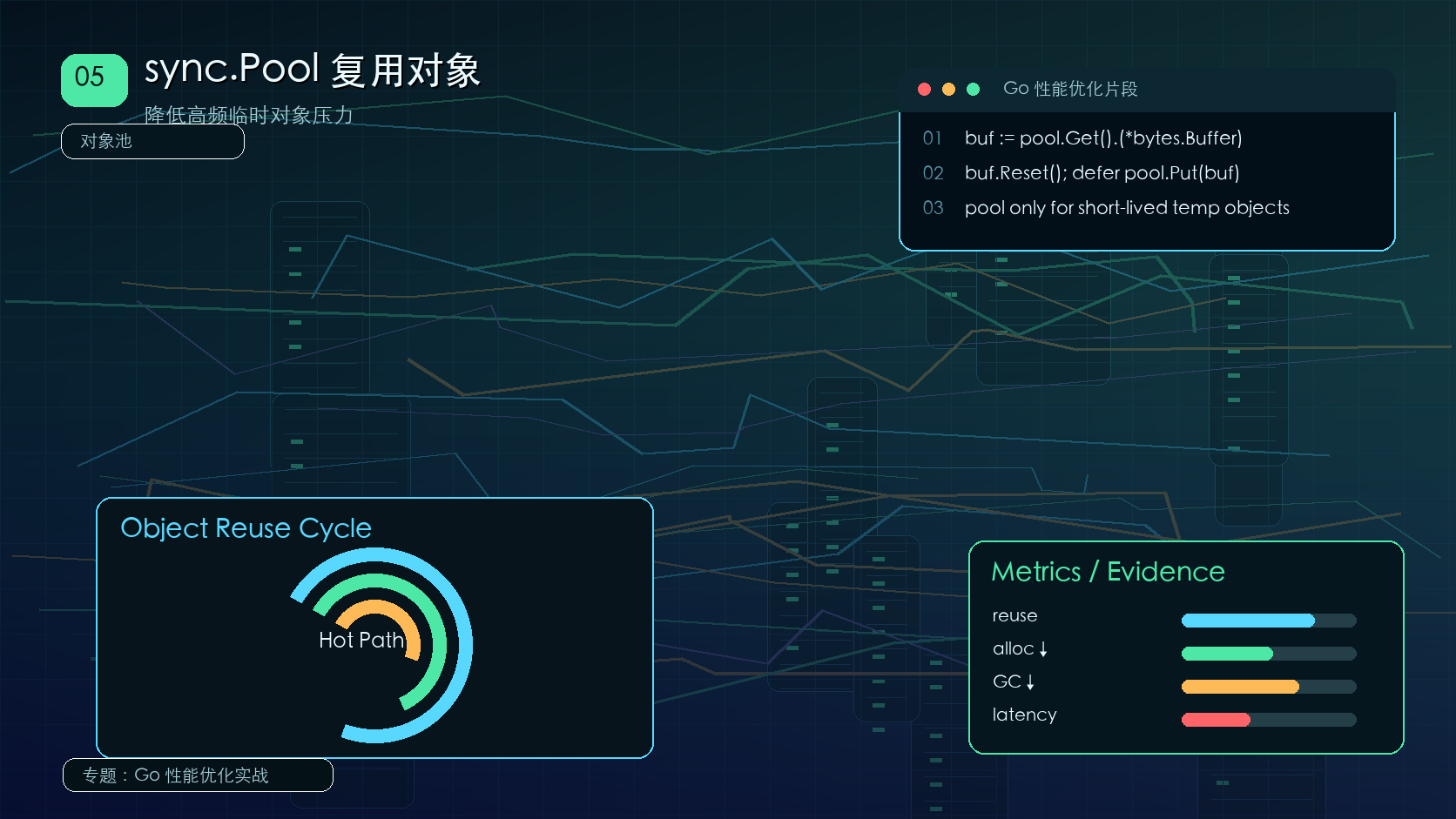
梳理 sync.Pool 的适用边界和误用风险,用对象复用降低高频临时分配。
-

K8s的sessionAffinity:ClientIP失效主因是流量路径中IP被SNAT或Ingress/云LB二次转发掩盖;实操需绕过Ingress直连ClusterIP、确认kube-proxy模式、合理设timeoutSeconds(推荐10800),并应用层用Cookie+Redis补足会话保持。
-

必须确保map已初始化且反射值可寻址:nilmap需先用reflect.MakeMap初始化,key/value类型须严格匹配并显式Convert,struct字段需FieldByName后检查CanAddr和CanSet。
-

不能用time.Ticker实现令牌桶,因其仅支持固定节奏发放令牌,无容量限制与预存能力;真正的令牌桶需支持突发流量缓冲、恒定填充速率及超限拒绝,故须自行维护带容量和时间戳的状态。
-

json.Marshal默认不处理私有字段、不支持循环引用、nilslice/map输出null、time.Time转RFC3339字符串——均为设计选择;字段需首字母大写才导出,tag格式须正确,nil指针需omitempty防panic。
-

最简可用GoCI流程需用actions/setup-go配置Go环境并显式启用GO111MODULE=on;必须先checkout再setup-go;含cgo需设CGO_ENABLED=1;避免冗余gomoddownload;交叉编译需指定GOOS/GOARCH;发布需permissions:contents:write及正确标签引用。
-

Go不支持传统函数嵌套,但可通过匿名函数赋值实现闭包;闭包捕获变量而非复制值,循环中易因共享变量引发陷阱。
-

channel不适合做HTTP负载均衡器,因其缺乏连接复用、超时控制、健康检查等核心能力;强行使用会导致contextdeadlineexceeded或connectionrefused,且无法按后端差异配置重试、TLS、Header等行为,也无自动剔除故障节点机制。
-

Go测试包的基准测试通过-benchmem可统计内存分配次数和字节数,输出allocs/op与B/op等指标,需在循环中用b.N多次调用被测函数并避免外部初始化。
-

通过合理配置HTTP连接池、启用Keep-Alive、设置超时与上下文控制、避免goroutine泄漏,并在必要时绕过内核协议栈,可稳定支撑10k+并发连接及数万QPS。
-

Go语言中typeswitch用于判断接口变量的实际类型,通过v:=i.(type)语法实现,适用于处理不确定类型的场景如JSON解析;普通switch比较值,而typeswitch针对interface{}的动态类型进行分支选择,支持int、string、指针等类型的匹配与处理;常用于通用打印函数等需类型区分的场景,必须作用于接口类型,不可用于具体类型,且推荐包含default分支以确保完整性。
-

Go程序启动报“Addressfamilynotsupportedbyprotocol”可锁定为IPv6绑定失败,主因是系统禁用IPv6(/proc/sys/net/ipv6/conf/all/disable_ipv6=1)而代码或依赖库仍尝试AF_INET6socket;修复方式是显式使用"0.0.0.0:端口"替代""或"[::]:端口",避免隐式IPv6回退。
-

动态规划核心是选对状态定义、控制子问题边界、避开零值陷阱;支持跳3步时状态转移方程为dp[i]=dp[i-1]+dp[i-2]+dp[i-3],基础case为dp[0]=1、dp[1]=1、dp[2]=2,数组长度至少n+3。
-

用switch和map替代多层if-else可提升Go代码的可读性、可维护性和执行效率:switch适合同一变量的离散值判断,map适合固定键的O(1)映射,二者可组合应对混合逻辑,并需规避闭包捕获、缺省处理、未判空及过度使用map等陷阱。
-

一致性哈希通过哈希环和虚拟节点将节点扩缩容时的重映射率从75%降至1%以内,核心是避免取模依赖节点总数,并用crc32.ChecksumIEEE保证跨语言一致性与分布均匀性。