-
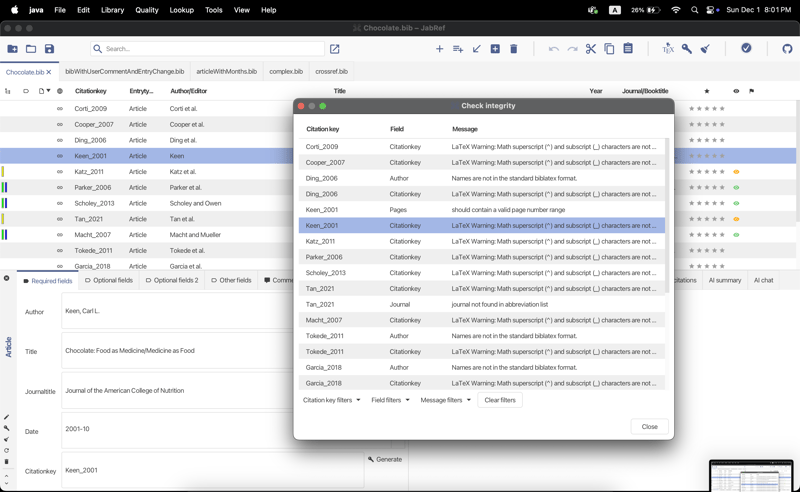
介绍在上一篇文章中,我说过我将致力于解决JabRef的问题,这是事实,但有一件事我必须提及。因此,我已将该问题计入我的0.2版提交中,但我无法在0.4版中使用它,因此我必须找到另一个问题来解决。然而,维护者拒绝将我分配给另一个问题,除非我没有完成前一个问题,所以我无论如何都必须完成它,然后才能分配给其他问题。因此,我要谈谈我上周做了什么。旧刊我很长时间没能完成这个问题,我无法确定是什么原因导致了这个问题,让我快速刷新一下你的想法并描述一下发生了什么。本期内容是关于什么的条目编辑器中某些字段的焦点问题,如下
-

Eclipse代码查重插件Eclipse中没有与IDEA相同的代码查重插件,但你可以使用以下方法进行代码查重:使用IDEA...
-

使用尾递归优化Java代码性能:尾递归将递归调用置于函数尾部,节省内存空间,避免栈溢出。实例:计算阶乘的尾递归函数tailRecursive(n,x->x==0?1:x*factorialTailRecursive(x-1))。优化效果:栈帧占用固定空间,避免递归调用导致的内存消耗,提高深度递归问题的性能。注意事项:避免无限递归、检测递归深度、避免修改输入参数。
-

Java中Lambda表达式与流API结合使用Lambda表达式和流API结合简化代码并提高可读性:流API提供处理数据集合的操作。Lambda表达式用于表示简洁的操作或函数。使用Lambda表达式对流元素执行操作的语法:stream.operation(element->code)。实战案例:筛选集合中的偶数将字符串列表映射为大写形式计算字符串列表的总长度
-

Java函数式编程在数据安全与保密处理中的应用函数式编程作为一种现代编程范式,其不可变性、纯净性和高阶函数特性,为数据安全和保密处理领域提供了强有力的支持。下面我们通过实战案例,阐述Java函数式编程如何应用于这些场景。1.哈希函数实现哈希函数是数据安全中广泛使用的技术,它将任意长度的数据映射为固定长度的哈希值。在Java中,我们可以使用MessageDigest类实现定制的哈希函数:importjava.security.MessageDigest;publicclassCus
-

Java中函数式编程异常处理:使用try-catch语句:代码中包含可能引发异常的代码块,然后使用catch子句处理异常。使用函数式编程表示法:使用try语句返回结果,在catch语句中捕获异常并调用异常处理函数。实战案例:函数calculate()可能抛出ArithmeticException,使用函数式编程的calculateSafely()返回默认值以处理异常,确保代码不会崩溃。
-

为了为Java项目选择合适的框架,需考虑项目需求、团队技能和长期维护因素。常见的框架包括:SpringBoot:全栈框架,提供依赖注入、Web服务器和数据库集成。Hibernate:ORM框架,用于对象与关系数据库之间的映射。JUnit:单元测试框架,用于编写和运行单元测试。Mockito:桩架和模拟库,用于编写测试用例。SpringSecurity:安全框架,用于身份验证、授权和访问控制。实战中,需要考虑项目特性、团队技能和长期维护情况。
-

Java框架中并发编程的未来发展趋势将集中在以下几个方面:异步非阻塞编程,使用回调和事件循环处理I/O事件,提高性能。并行流处理,利用多核处理器,将流数据分解成较小的块并行处理,提升性能。锁优化,专注于优化锁机制的使用,例如采用读写锁或无锁数据结构,减少锁对性能的影响。reactive编程,一种处理异步事件流的范例,通过强调可观察性和错误处理简化并发编程。
-

Java框架中的异常处理安全性影响包括:DoS攻击:未处理的异常可导致服务崩溃。信息泄露:异常消息和堆栈跟踪包含敏感信息。代码注入:异常处理机制中的漏洞可导致恶意代码执行。正确处理异常可防止上述安全风险,例如:使用受检异常避免DoS攻击。使用自定义异常消息减少信息泄露。使用安全的异常类型避免代码注入。
-

在评估Java框架时,应考虑以下标准:功能、性能、社区支持、易用性和可扩展性。对于需要用户认证、数据验证和RESTfulAPI的Web应用程序,评估SpringBoot和Dropwizard框架后发现:SpringBoot提供所有必需功能、性能良好、社区支持广泛且易于使用,因此对于该项目更合适。
-

Java框架对学术研究的影响评估Java框架已成为学术研究中不可或缺的工具,通过提供预先构建的组件和模块,它们简化了研究应用程序和系统的开发。本文量化了Java框架对学术研究的影响,并提供了一个实战案例来说明它们的益处。研究方法为了评估Java框架对学术研究的影响,我们收集了100篇学术论文,其中使用了Java框架。我们分析了这些论文,以确定Java框架的使用方式、益处和挑战。研究结果我们的分析表明,Java框架已广泛用于学术研究,涉及从自然语言处理到计算机视觉等各种领域。Java框架被用于:构建API和
-

Java序列化提供如下类型的序列化:1.基本数据类型序列化;2.对象序列化,要求类实现java.io.Serializable接口;3.外部化和反序列化,要求对象实现java.io.Externalizable接口。实战中,可直接存储和读取对象信息。
-

Java是一种广泛使用的计算机编程语言,由SunMicrosystems公司于1995年推出。它是一种高级的、面向对象的、可移植的编程语言,被设计用于开发跨平台的应用程序。Java编程语言具有许多优点,使其在软件开发领域中广泛受欢迎。首先,Java是一种面向对象的编程语言。面向对象编程是一种计算机编程的范式,它将程序中的数据和操作封装在对象中,通过对象之间
-

提升中文改写效果的Java软件优化策略引言:随着人工智能的快速发展,自然语言处理成为了研究和应用的重要领域之一。中文改写作为自然语言处理中的一个重要任务,旨在将一个句子或短语改写为与原文含义相同但表达方式不同的句子或短语,对于提升文本的可读性和理解度至关重要。在本文中,我们将探讨如何利用Java编程语言对中文改写进行优化,提高改写的效果。一、问题描述中文改写
-

如何选择合适的Eclipse反编译插件引言:在开发过程中,我们常常会遇到需要查看某个Java类文件的源码的情况,有时候我们只有一个编译后的class文件,没有源码。这时,反编译工具就非常有用了。而Eclipse是广泛使用的Java集成开发环境(IntegratedDevelopmentEnvironment,简称IDE),它提供了许多插件来满足Java开