-

在Java框架中集成AI技术可赋能应用程序,实现以下功能:使用预训练好的模型,例如识别恶意软件。训练并部署自定义模型,例如预测客户流失。利用AI服务,例如使用CloudVisionAPI进行图像分类。
-

Java框架应对可扩展性挑战:容器化,提高吞吐量和响应时间;微服务架构,增强整体可扩展性;负载均衡,避免单点故障,提高可用性。维护性挑战:依赖管理,避免冲突,确保稳定性;单元测试,确保代码正确性;集成测试,确保与外部系统交互正常。
-

在springsecurity6中,requestmatchers方法取代了已弃用的antmatchers、mvcmatchers和regexmatchers方法,用于配置基于路径的访问控制。以下是关于新requestmatchers的要点:在authorizehttprequests中使用requestmatchershttpsecurity配置中的authorizehttprequests方法允许您配置细粒度的请求匹配以进行访问控制。您可以使用requestmatchers方法来指定应允许或验证哪些请
-

答案:通过抽象化,Java框架减少了代码耦合性。详细描述:抽象类提供抽象接口,强制基于接口的编程,隔离开子类与具体实现。接口声明抽象方法,仅由类实现,确保模块之间的松散耦合。数据访问对象(DAO)模式提供抽象层,分离应用程序代码与数据库交互的细节,降低耦合性。
-

最适合Java框架的设计模式是:工厂模式:创建对象的标准化方式,由SpringFramework中的SpringIoC容器使用。单例模式:限制类的实例化数量,确保仅存在一个实例。策略模式:允许在运行时更改算法或行为。代理模式:提供一个替代对象,可以控制或增强另一个对象的访问。装饰器模式:动态地添加额外功能,而无需更改目标对象的结构。
-

通过以下步骤基于性能指标选择Java框架:确定性能需求:例如吞吐量、响应时间和资源利用率。研究框架:比较线程处理、缓存支持和数据绑定的性能特征。运行基准测试:评估不同框架在现实场景中的实际性能。分析结果:确定符合性能需求的框架,并考虑系统资源影响。例如,对于高吞吐量和低延迟的API,基准测试表明JAX-RS优于SpringMVC,响应时间更短,在高负载下也能保持稳定吞吐量。
-

Java框架常见故障排除指南和解决方案处理Java框架中的故障和异常非常重要,因为它有助于确保应用程序的稳定性和可靠性。以下是常见的故障排除指南和解决方案:1.HTTP状态代码404错误(找不到):确保请求的URL正确,并且文件或资源确实存在。500错误(服务器内部错误):查看日志文件以查看更详细的异常消息。检查服务器配置和代码中的错误。401错误(未经授权):验证用户凭据并确保他们有权访问该资源。2.Java异常NullPointerException:检查变量或引用是否为nu
-
SpringBoot启动并初始化执行sql脚本如果我们想在项目启动的时候去执行一些sql脚本该怎么办呢,SpringBoot给我们提供了这个功能,可以在启动SpringBoot的项目时,执行脚本,下面我们来看一下。我们先看一下源码booleancreateSchema(){//会从application.properties或application.yml中获取sql脚本列表Listscripts=this.getScripts("spring.datasource.schema",this.proper
-

Java异常处理最佳实践包括:使用特定的异常类型,以精确处理错误。仅捕获所需异常,避免代码混乱。提供有意义的错误消息,方便理解。适当使用finally块,确保资源释放。
-

关于节点数据添加:尾添加最核心的是定义一个头指针和一个尾指针(尾指针可以不定义但是会增加代码的重复性,增加程序运行时间);关于尾添加:(注意区分有节点和无节点的情况)#include#include#includestructMystruct{intdata;structMystruct*pnext;};voidendadd(structMystruct**phead,structMystruct**pend,intadddata);intmain(void){structMystruct*phead=N
-

答案:Java多线程开发的高性能技巧包括优化线程池、选择合适的同步机制、避免死锁、使用非阻塞I/O和利用并发集合。优化线程池:基于任务类型选择固定或可变大小的线程池。同步机制:根据并发性、性能和场景选择锁、原子类或阻塞队列。避免死锁:使用死锁检测算法,谨慎获取和释放锁,并设置超时机制。非阻塞I/O:使用JavaNIO处理I/O操作时,线程不需等待完成即可执行其他任务。并发集合:利用ConcurrentHashMap和BlockingQueue等并发集合实现高效的并发访问。
-

说明1、while关键词的中文含义是当……时,即条件成立时循环执行对应的代码。while语句是循环语句中的基本结构,语法格式比较简单。执行过程2、执行while语句时,首先判断循环条件,循环条件为false时,直接执行while语句的后续代码,循环条件为true时,执行循环体代码,判断循环条件,直到循环条件不成立为止。实例inti=1;intsum=0;while(i
-
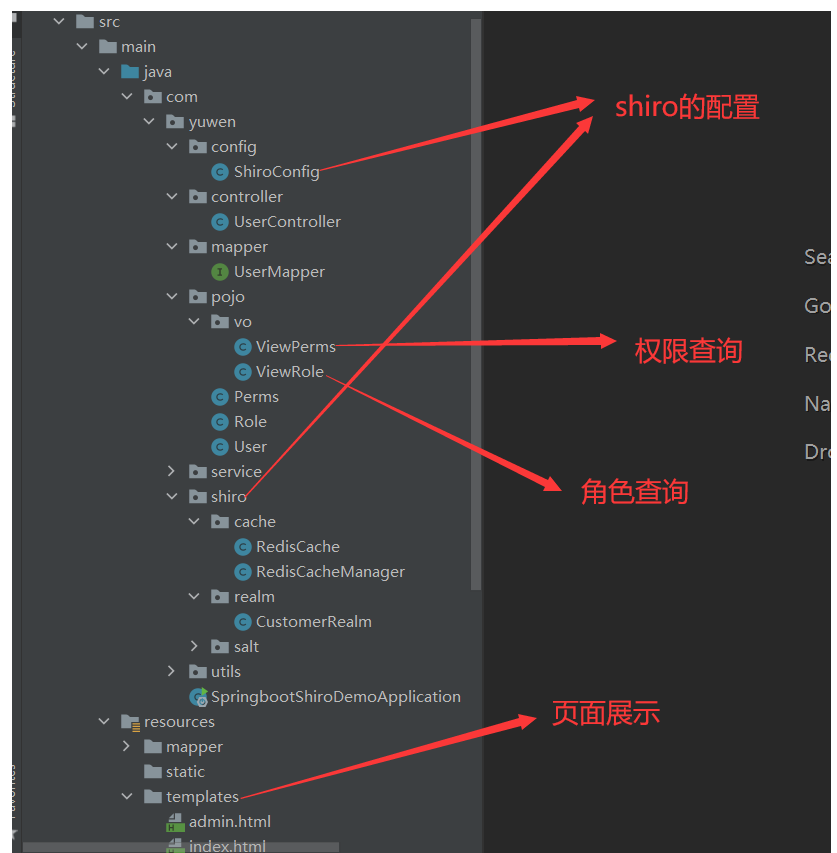
1、SpringBoot整合ShiroApacheShiro是一个强大且易用的Java安全框架,执行身份验证、授权、密码和会话管理。1.1、shiro简介shiro有个核心组件,分别为Subject、SecurityManager和RealmsSubject:相当于当前操作的”用户“,这个用户不一定是一个具体的人,是一个抽象的概念,表明的是和当前程序进行交互的任何东西,例如爬虫、脚本、等等。所有的Subject都绑定到SecurityManager上,与Subject的所有交互都会委托给SecurityM
-

Java作为现代编程语言中最受欢迎的一种,广泛应用于企业级应用和大规模软件开发中。然而,尽管Java拥有良好的跨平台性、面向对象特性和丰富的类库,但是在实际开发中,我们经常会遇到各种各样的问题和错误。其中,JAXB错误是Java开发中常见的一种问题。本文将介绍什么是JAXB错误,如何处理和避免这类错误。什么是JAXB错误?JAXB(JavaArchitec
-

Java数组添加元素的技巧与注意事项在Java中,数组是一种非常常见和重要的数据结构。数组提供了一个用于存储多个相同类型元素的容器,并且可以通过索引来访问和修改其中的元素。有时候,我们需要在已有数组中添加新的元素,本文将介绍一些Java数组添加元素的技巧和注意事项,并通过具体的代码示例来说明。使用copyOf方法Java提供了Arrays类的copyOf方法