-

Java开发在线考试系统的试卷阅卷与评分模块随着互联网的普及和发展,越来越多的教育机构和企业开始采用在线考试系统,方便进行远程考试和评估学员的学习情况。在这样的系统中,试卷阅卷与评分是非常重要的功能模块之一。本文将介绍如何使用Java开发在线考试系统的试卷阅卷与评分模块,并提供具体的代码示例。首先,我们需要定义试题的数据结构。试题包括题目、选项、答案等信息,
-
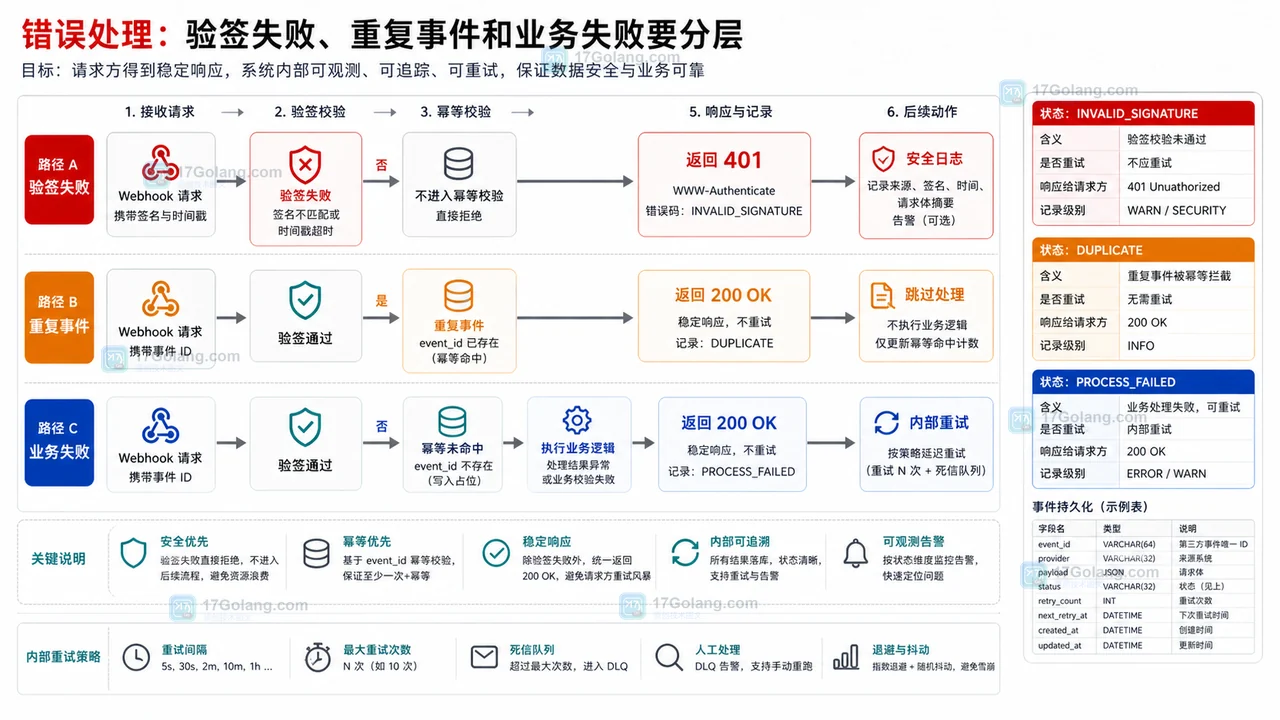
本文从 Java 服务接收第三方 Webhook 的接口设计出发,说明如何定义回调目标、验签参数、幂等键、错误响应、状态流转和兼容策略,避免重复通知和伪造请求。
-

Java布尔类型仅取true/false,不与数字互转,不可算术运算,用于逻辑判断、状态标识和方法返回值,提升安全性与可读性。
-

thenCompose()用于扁平化嵌套CompletableFuture,要求函数直接返回CompletableFuture以避免类型嵌套;而thenApply()会生成CompletableFuture<CompletableFuture<T>>,导致类型错误和运行时异常。
-

transient仅在Java原生序列化(ObjectOutputStream/ObjectInputStream)中生效,要求类实现Serializable且字段为非static、非final的实例变量;在JSON、日志、数据库、HTTP等场景中完全无效。
-

JAVA_HOME指向哪个目录才真正有效必须指向JDK的根目录,不是JRE目录,也不是bin子目录。常见错误是把JAVA_HOME设成C:\ProgramFiles\Java\jdk-17.0.1\bin——这会导致几乎所有依赖它的工具(如Maven、Gradle、IDE)报“找不到Java”或“java.lang.NoClassDefFoundError”。JDK根目录下得有lib、jre(或conf)、bin三个关键子目录。✅正确示例:C:\Program
-

抽象类构造方法是子类对象创建时强制执行父类初始化逻辑的唯一时机,通过super()调用完成final字段校验赋值、共享资源注入,并禁止调用抽象方法,且子类必须显式调用super()。
-

Java字符串转义最易出错的是反斜杠(\\)和双引号(\"),因编译期解析导致路径、正则、JSON等场景需双重转义;Unicode转义\uXXXX须4位且UTF-8编码;应优先使用专用序列化库而非手动拼接。
-

InetAddress.getLocalHost()返回127.0.0.1是因主机名被解析为localhost,应遍历网卡获取真实局域网IP;getByName()失败多因DNS缓存、IPv6优先或防火墙;isReachable()在Windows下不可靠;getCanonicalHostName()强制正反向DNS解析确保FQDN。
-

包可见性是Java中一种恰到好处的封装手段,使成员仅对同包类可见,兼顾内聚协作与边界控制,需配合功能导向包结构和同包测试实践。
-

老年代担保失败是JVM在MinorGC前预判风险后主动触发FullGC的结果,关键在于检查时机(GC前)、判断依据(连续空闲空间≥晋升量或历史均值)和退路选择(直接FullGC而非补救)。
-

答案是:用jstack查RUNNABLE线程中是否反复出现getEntry或transfer栈帧,结合MAT分析heap.hprof确认next互指环。死循环表现为CPU100%、无异常、多线程卡在e=e.next且地址交替,根源是JDK7扩容时头插法与竞态导致A↔B环。
-

POSITIVE_INFINITY是边界标记值,用于表示无上限或跳过约束,不可直接赋给速度参与物理计算;需配合isfinite()检查,在速度钳制、CCD开关等场景中作为配置语义值使用。
-

Reference.reachabilityFence并非修复NPE的万能药,而是防止JVM过早判定对象不可达的编译器屏障;它仅在对象本应可达但因激进优化(如逃逸分析)被误回收时生效,且必须紧邻最后一次使用、在同一栈帧内调用,配合Cleaner或PhantomReference使用才有效。
-

在Java中使用HttpURLConnection设置User-Agent需在connect()前调用setRequestProperty("User-Agent",uaString),推荐使用主流浏览器真实UA字符串,但仅设UA不足以完全模拟浏览器,还需配合其他头部及请求策略。