-

锁降级需显式调用tryConvertToReadLock且必须用原写锁stamp,失败时须先unlockWrite再readLock并重读字段;其价值在于写锁修正状态后转读锁支持并发只读计算,避免全程持写锁阻塞读请求。
-

不一定。Java对象排序仅在使用Collections.sort()或Arrays.sort()且不传Comparator,或放入TreeSet/TreeMap时才需实现Comparable;否则可用Comparator,尤其适合临时、多维或第三方类排序。
-

CMS低延迟核心在于分阶段并发标记与写屏障协同:初始标记仅STW标记GCRoots直连对象(10–100ms);并发标记靠写屏障记录引用变更,保障准确性;重新标记STW修补变动,耗时取决于并发期引用修改频率;浮动垃圾可容忍,但并发模式失败将触发FullGC,需保守设置启动阈值并监控。
-

Java中用for循环校验多层括号配对需模拟栈:单类型用depth计数器,遇'('加1、')'减1并检查越界;多类型用char数组栈,遇左括号入栈、右括号匹配弹出,最后栈空则合法。
-

不推荐在toString中输出JSON,因会导致隐式依赖、性能开销、线程安全风险及循环引用异常;应交由日志框架(如Logback的logstash-logback-encoder或Log4j2的JsonLayout)处理,或提供专用toLogJson()方法。
-

答案:通过定义Course类并利用LocalTime判断时间重叠,实现选课冲突检测。具体为创建包含课程信息的实体类,重写equals和hashCode方法,使用List存储已选课程,在添加新课时遍历列表调用isConflict方法判断是否同一天且时间区间重叠(startTime.isBefore(other.endTime)&&endTime.isAfter(other.startTime)),若冲突则提示用户无法添加,否则加入列表完成选课;可扩展支持单双周、课程编号及Web接口等功能。
-

ForkJoinTask是Java中用于高效并行计算的核心类,适合分治算法场景。通过继承RecursiveTask(有返回值)或RecursiveAction(无返回值),重写compute()方法实现任务拆分与执行,结合fork()异步提交、join()等待结果,利用ForkJoinPool的工作窃取机制提升多核性能,关键在于合理设置任务粒度以平衡拆分开销与并行效率。
-

抽象类该有构造函数,且通常必须有;它不能是private,推荐用protected修饰,子类构造器需显式调用super(...)。
-

应使用枚举配合switch实现状态分流,显式覆盖所有枚举值、禁用default兜底,Java14+推荐switch表达式,旧版default抛AssertionError;case仅调度不实现业务;状态变量须强类型绑定枚举;优先考虑在枚举内定义抽象方法实现行为穷尽。
-
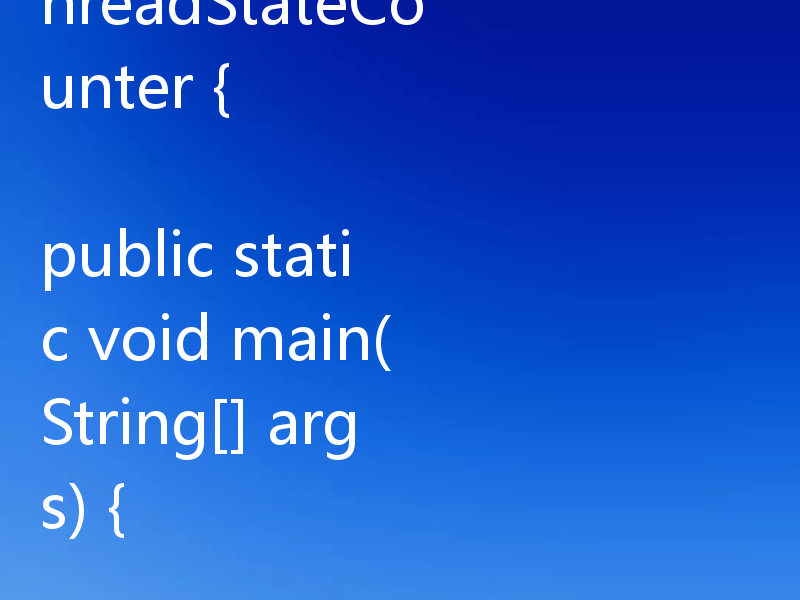
Thread.enumerate()仅返回当前线程组活跃线程快照数组,需配合getState()逐个判断状态;统计时应先用activeCount()预估并扩容数组,再enumerate填充,遍历非null线程计数各State频次。
-

安全获取Stream首个元素应始终基于Optional的存在性做显式分支处理:用ifPresent()执行无返回操作,orElse()/orElseGet()提供默认值,map()+orElse()链式转换,orElseThrow()仅用于业务强制非空场景。
-

Optional.or()提供惰性、可组合的备选值获取机制,接收Supplier<Optional<T>>,仅在为空时调用并返回Optional,支持链式操作与多级fallback。
-

基本类型必须通过包装类才能存入Java集合,因集合只支持引用类型;自动装箱/拆箱简化操作,但需注意==比较陷阱、null值检查及字符串转换异常处理。
-

逃逸分析本身不直接实现栈上分配,而是JVM或Go编译器在运行时或编译期识别出变量不会逃逸后,自动触发栈上分配;真正起作用的是编译器优化,不是开发者手动写“分配到栈上”的代码。
-

DataInputStream读不到int或double是因它只按Java二进制格式(大端、定长)解析,必须由DataOutputStream配套写入;否则字节布局错位,导致EOFException或异常数值。