java教程技术文章
-
 应先校验扩展名和MIME类型,再用ImageIO.read()并检查null;保存时用UUID重命名、防路径遍历;缩略图用setSourceSubsampling降采样并flush;元数据需显式读取和写入。332 收藏
应先校验扩展名和MIME类型,再用ImageIO.read()并检查null;保存时用UUID重命名、防路径遍历;缩略图用setSourceSubsampling降采样并flush;元数据需显式读取和写入。332 收藏 -
 Optional不是null替代品,而是为明确表达“可能无值”的计算链设计;禁用其作参数、字段、DTO及序列化场景,优先使用函数式操作而非isPresent()。332 收藏
Optional不是null替代品,而是为明确表达“可能无值”的计算链设计;禁用其作参数、字段、DTO及序列化场景,优先使用函数式操作而非isPresent()。332 收藏 -
 String.regionMatches()方法用于安全高效地比较两字符串指定区域是否相等,支持忽略大小写;调用带booleanignoreCase参数的重载版本,需正确指定起始索引和长度,并建议预先校验边界以确保可靠性。332 收藏
String.regionMatches()方法用于安全高效地比较两字符串指定区域是否相等,支持忽略大小写;调用带booleanignoreCase参数的重载版本,需正确指定起始索引和长度,并建议预先校验边界以确保可靠性。332 收藏 -
 Iterator.remove()是唯一安全的遍历中删除方式,因fail-fast机制下直接调用list.remove()会抛ConcurrentModificationException;removeIf()适合批量条件删除但不支持副作用操作。332 收藏
Iterator.remove()是唯一安全的遍历中删除方式,因fail-fast机制下直接调用list.remove()会抛ConcurrentModificationException;removeIf()适合批量条件删除但不支持副作用操作。332 收藏 -
 MyBatis拦截Executor监控SQL耗时最直接有效,需通过@Intercepts声明拦截Executor的query/update方法,注意type、method名和args类型顺序;应使用System.nanoTime()对非缓存SELECT计时,并排查多数据源、代理包装及分库分表中间件导致的拦截失效。332 收藏
MyBatis拦截Executor监控SQL耗时最直接有效,需通过@Intercepts声明拦截Executor的query/update方法,注意type、method名和args类型顺序;应使用System.nanoTime()对非缓存SELECT计时,并排查多数据源、代理包装及分库分表中间件导致的拦截失效。332 收藏 -
 SpringBoot本身不提供原生的命令行远程调用机制,但可通过Actuator+HTTP端点、JMX、SpringIntegration或自定义WebSocket/REST接口等方式安全实现运行时方法触发。332 收藏
SpringBoot本身不提供原生的命令行远程调用机制,但可通过Actuator+HTTP端点、JMX、SpringIntegration或自定义WebSocket/REST接口等方式安全实现运行时方法触发。332 收藏 -
 Connection复用的是JDBCConnection对象而非物理TCP连接,节省三次握手等开销;其本质是池化管理带状态的连接实例,需同线程借还,避免跨线程共享、错误关闭或绕过池直连。332 收藏
Connection复用的是JDBCConnection对象而非物理TCP连接,节省三次握手等开销;其本质是池化管理带状态的连接实例,需同线程借还,避免跨线程共享、错误关闭或绕过池直连。332 收藏 -
 对象必须8字节对齐,是因为64位CPU以8字节为单位读取数据,未对齐会导致跨缓存行访问,降低性能甚至引发硬件异常;同时保障long、double、volatile字段的原子性及指针压缩(CompressedOops)正确工作。332 收藏
对象必须8字节对齐,是因为64位CPU以8字节为单位读取数据,未对齐会导致跨缓存行访问,降低性能甚至引发硬件异常;同时保障long、double、volatile字段的原子性及指针压缩(CompressedOops)正确工作。332 收藏 -
 putAll直接覆盖重复键,不处理冲突;merge用BiFunction合并重复键值;Stream.toMap需显式指定冲突函数,否则抛异常。332 收藏
putAll直接覆盖重复键,不处理冲突;merge用BiFunction合并重复键值;Stream.toMap需显式指定冲突函数,否则抛异常。332 收藏 -
 allOf返回CompletableFuture<Void>,仅表示所有任务完成,不聚合结果;需保留原始CompletableFuture引用,逐一调用join()获取各值并处理异常。332 收藏
allOf返回CompletableFuture<Void>,仅表示所有任务完成,不聚合结果;需保留原始CompletableFuture引用,逐一调用join()获取各值并处理异常。332 收藏 -
 Metaspace泄露本质是类加载器未被回收导致元数据堆积;需通过JVM参数监控、jcmd/MAT定位异常类加载器,并修复ThreadLocal、静态缓存、监听器注册等常见泄露点。332 收藏
Metaspace泄露本质是类加载器未被回收导致元数据堆积;需通过JVM参数监控、jcmd/MAT定位异常类加载器,并修复ThreadLocal、静态缓存、监听器注册等常见泄露点。332 收藏 -
 DocumentBuilder不是线程安全的,多线程共享会导致状态错乱、解析失败甚至JVM崩溃;应使用ThreadLocal隔离实例,或改用JAXB、StAX等线程安全替代方案。332 收藏
DocumentBuilder不是线程安全的,多线程共享会导致状态错乱、解析失败甚至JVM崩溃;应使用ThreadLocal隔离实例,或改用JAXB、StAX等线程安全替代方案。332 收藏 -
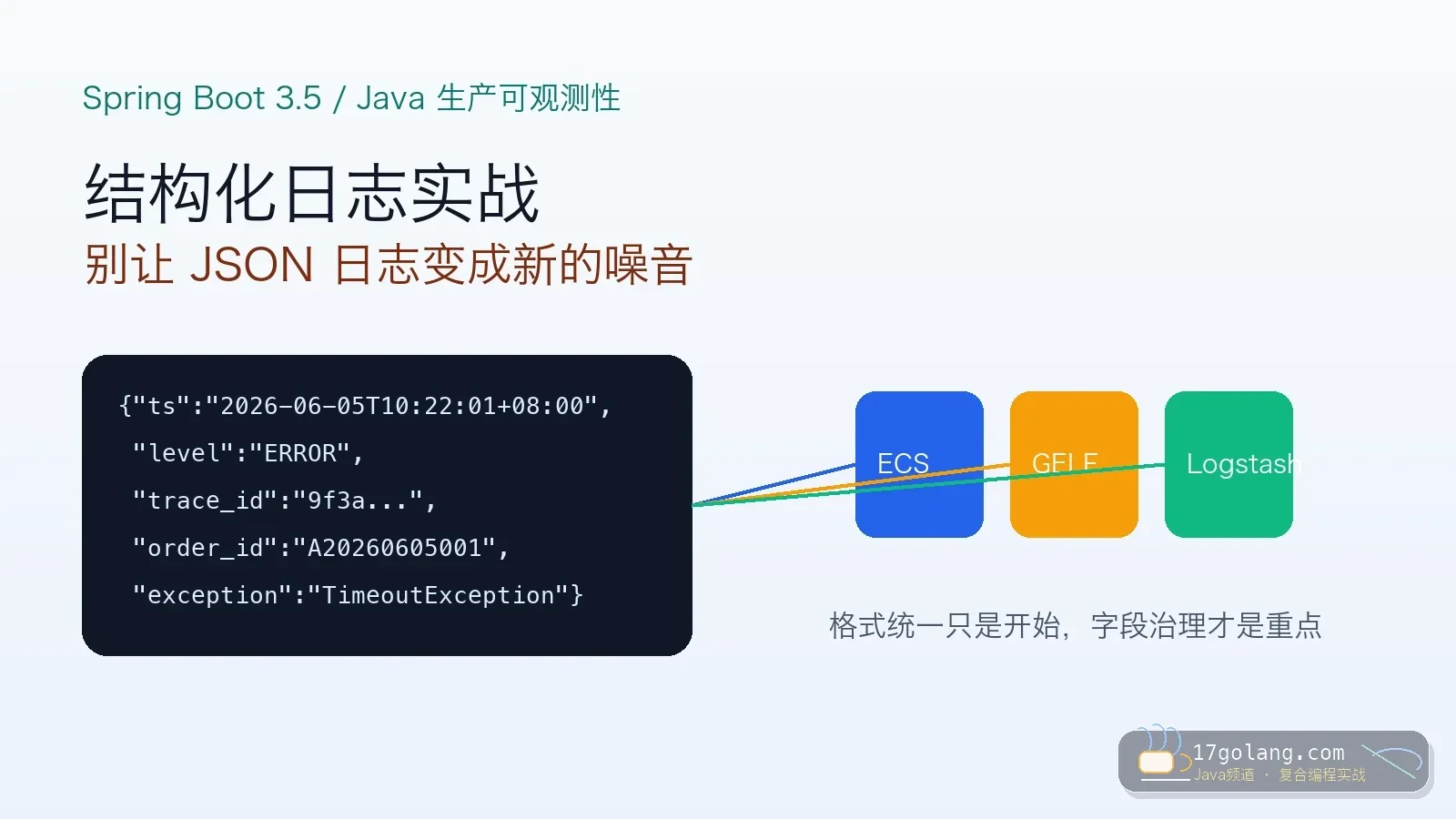 从一次 Spring Boot 结构化日志改造复盘讲起,拆解字段契约、MDC 生命周期、日志成本、告警迁移和上线检查。332 收藏
从一次 Spring Boot 结构化日志改造复盘讲起,拆解字段契约、MDC 生命周期、日志成本、告警迁移和上线检查。332 收藏 -
 SonarQube报告“未在finally中关闭ObjectInputStream”并非误报:当外层流(如FileInputStream)关闭时抛出异常,内层流(ObjectInputStream)将被跳过关闭,导致资源泄漏。本文详解兼容旧Java版本的安全关闭模式。331 收藏
SonarQube报告“未在finally中关闭ObjectInputStream”并非误报:当外层流(如FileInputStream)关闭时抛出异常,内层流(ObjectInputStream)将被跳过关闭,导致资源泄漏。本文详解兼容旧Java版本的安全关闭模式。331 收藏 -
 Springfox3.x在SpringBoot2.6+需配置spring.mvc.throw-exception-if-no-handler-found:false且spring.resources.add-mappings:true,访问路径为/swagger-ui/;SpringBoot3.x不兼容Springfox,须迁移到springdoc-openapi。331 收藏
Springfox3.x在SpringBoot2.6+需配置spring.mvc.throw-exception-if-no-handler-found:false且spring.resources.add-mappings:true,访问路径为/swagger-ui/;SpringBoot3.x不兼容Springfox,须迁移到springdoc-openapi。331 收藏