java教程技术文章
-
 Thread.setPriority()仅提供跨平台不一致的调度建议,不保证OS级权重,Linux/macOS基本无效,Windows略有效;应改用线程池、信号量等可控机制。478 收藏
Thread.setPriority()仅提供跨平台不一致的调度建议,不保证OS级权重,Linux/macOS基本无效,Windows略有效;应改用线程池、信号量等可控机制。478 收藏 -
 LocalDate.plusDays()语义上只支持加正数天数,负数虽可运行但属隐式兼容而非官方承诺;应改用minusDays()实现减法,以保证语义清晰、可读性强且避免静态分析警告。478 收藏
LocalDate.plusDays()语义上只支持加正数天数,负数虽可运行但属隐式兼容而非官方承诺;应改用minusDays()实现减法,以保证语义清晰、可读性强且避免静态分析警告。478 收藏 -
文章 · java教程 | 3星期前 | Java · Stream · 集合统计 · 分组聚合 · Collectors · java Stream Collectors groupingBy counting summarizingInt
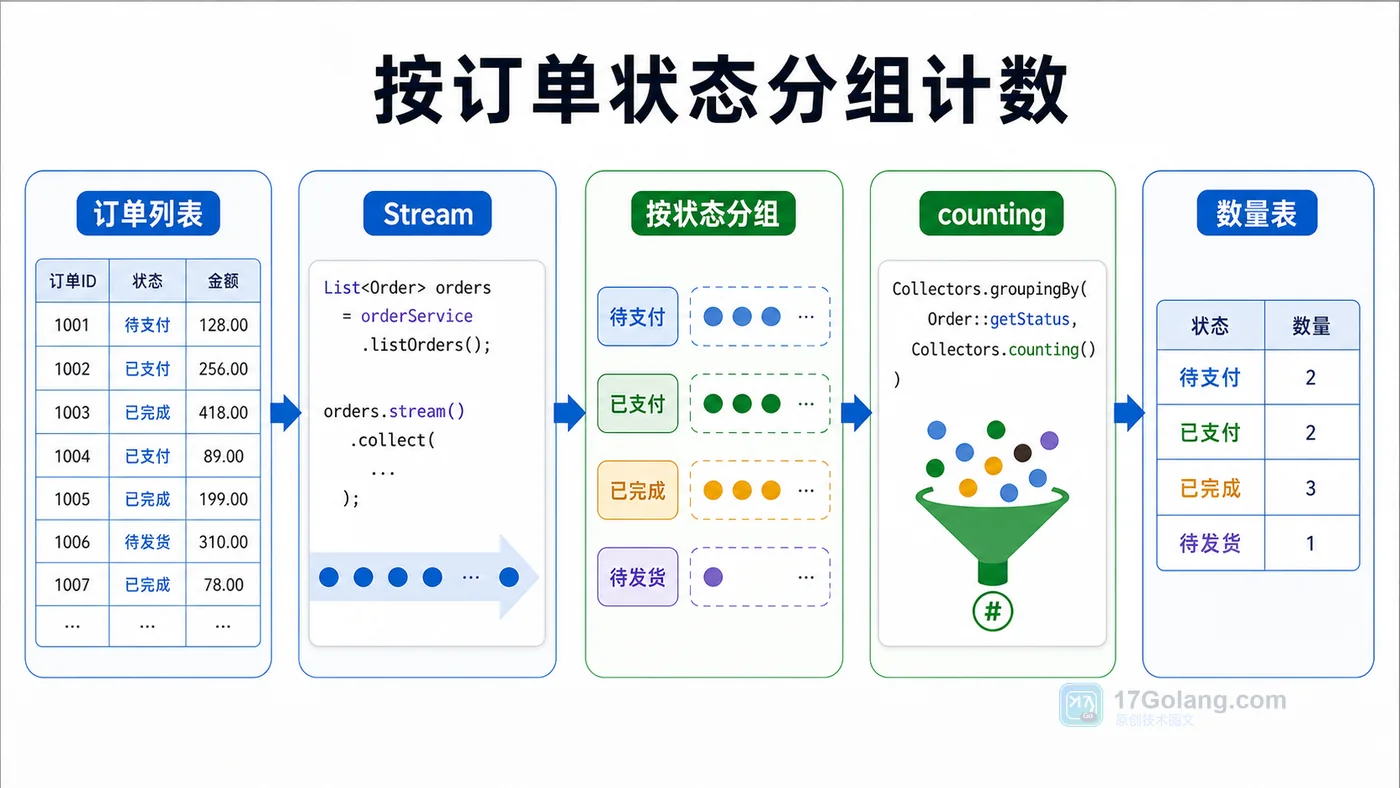 本文用订单列表示例讲清 Java Stream 分组统计:按状态分组计数、按用户汇总金额、用 summarizingInt 一次拿到数量、总和、最大值和平均值。478 收藏
本文用订单列表示例讲清 Java Stream 分组统计:按状态分组计数、按用户汇总金额、用 summarizingInt 一次拿到数量、总和、最大值和平均值。478 收藏 -
 合理使用三元运算符、逻辑运算符、Optional和switch表达式可简化Java条件判断。例如,用?:替代简单if-else赋值,如Stringresult=(num>0)?"正数":"非正数";;通过&&、||合并条件并利用短路特性避免空指针,如if(user!=null&&user.isActive()&&!user.isLocked());将复杂条件提取为布尔变量提升可读性;使用Optional.ofNu477 收藏
合理使用三元运算符、逻辑运算符、Optional和switch表达式可简化Java条件判断。例如,用?:替代简单if-else赋值,如Stringresult=(num>0)?"正数":"非正数";;通过&&、||合并条件并利用短路特性避免空指针,如if(user!=null&&user.isActive()&&!user.isLocked());将复杂条件提取为布尔变量提升可读性;使用Optional.ofNu477 收藏 -
 静态方法不能直接访问非静态成员变量,因其属于类而非对象实例,且静态方法在类加载时即可调用,而实例变量需对象创建后才存在;静态方法无this引用,无法定位具体实例。477 收藏
静态方法不能直接访问非静态成员变量,因其属于类而非对象实例,且静态方法在类加载时即可调用,而实例变量需对象创建后才存在;静态方法无this引用,无法定位具体实例。477 收藏 -
 首先设计Transaction类封装金额、类型、分类和日期,再通过FinanceManager管理交易记录并实现增删查及统计功能,接着用文件持久化保存数据,最后用Scanner实现控制台交互,逐步构建出结构清晰的小型个人财务工具。477 收藏
首先设计Transaction类封装金额、类型、分类和日期,再通过FinanceManager管理交易记录并实现增删查及统计功能,接着用文件持久化保存数据,最后用Scanner实现控制台交互,逐步构建出结构清晰的小型个人财务工具。477 收藏 -
 Java中加号(+)用于字符串拼接时,只要任一操作数为String,其余操作数自动调用toString()转为字符串并左结合拼接;null转为"null";自定义类需重写toString();频繁拼接应使用StringBuilder。477 收藏
Java中加号(+)用于字符串拼接时,只要任一操作数为String,其余操作数自动调用toString()转为字符串并左结合拼接;null转为"null";自定义类需重写toString();频繁拼接应使用StringBuilder。477 收藏 -
 containsKey比get()+null判断更合适,因其能准确区分“键不存在”和“键存在但值为null”,避免误判缓存未命中;且不触发值构造或反序列化,线程安全,语义清晰。477 收藏
containsKey比get()+null判断更合适,因其能准确区分“键不存在”和“键存在但值为null”,避免误判缓存未命中;且不触发值构造或反序列化,线程安全,语义清晰。477 收藏 -
 最常见的原因是未指定-XX:HeapDumpPath,JVM默认写入当前工作目录,而生产环境常因权限不足、路径只读或磁盘满导致静默失败;必须显式指定可写且有足够空间的绝对路径。477 收藏
最常见的原因是未指定-XX:HeapDumpPath,JVM默认写入当前工作目录,而生产环境常因权限不足、路径只读或磁盘满导致静默失败;必须显式指定可写且有足够空间的绝对路径。477 收藏 -
 TransactionSystemException报错需先查getCause(),90%为SQLException或ConnectionClosedException;常见原因包括连接池未校验连接有效性、本类方法调用导致事务失效、InnoDB锁等待超时。477 收藏
TransactionSystemException报错需先查getCause(),90%为SQLException或ConnectionClosedException;常见原因包括连接池未校验连接有效性、本类方法调用导致事务失效、InnoDB锁等待超时。477 收藏 -
 Integer.parseInt()严格解析字符串为int,不接受null、空串、空格、非数字字符或溢出值,需前置校验和异常捕获;valueOf()返回缓存Integer对象;进制解析须先去除前缀;溢出时应改用BigInteger.intValueExact()等安全方式。477 收藏
Integer.parseInt()严格解析字符串为int,不接受null、空串、空格、非数字字符或溢出值,需前置校验和异常捕获;valueOf()返回缓存Integer对象;进制解析须先去除前缀;溢出时应改用BigInteger.intValueExact()等安全方式。477 收藏 -
 最可靠的判空方式是obj==null。它能准确识别未分配内存的对象,避免调用方法时抛出NullPointerException;其他方式如toString()或isEmpty()在null时会直接崩溃。477 收藏
最可靠的判空方式是obj==null。它能准确识别未分配内存的对象,避免调用方法时抛出NullPointerException;其他方式如toString()或isEmpty()在null时会直接崩溃。477 收藏 -
 fail-fast的核心是检测集合结构被意外修改而非并发;ArrayList的modCount在结构性修改时自增,迭代器构造时复制为expectedModCount,next()/hasNext()前比对二者,不等则抛ConcurrentModificationException。476 收藏
fail-fast的核心是检测集合结构被意外修改而非并发;ArrayList的modCount在结构性修改时自增,迭代器构造时复制为expectedModCount,next()/hasNext()前比对二者,不等则抛ConcurrentModificationException。476 收藏 -
 Java读取文件乱码的根本原因是程序字符编码与文件实际编码不一致,需明确文件真实编码并显式指定,禁用系统默认编码,处理BOM,统一项目UTF-8规范。476 收藏
Java读取文件乱码的根本原因是程序字符编码与文件实际编码不一致,需明确文件真实编码并显式指定,禁用系统默认编码,处理BOM,统一项目UTF-8规范。476 收藏 -
 Java线程有六种状态:NEW、RUNNABLE、BLOCKED、WAITING、TIMED_WAITING、TERMINATED;它们是Thread类中可直接通过getState()读取的真实枚举值,反映线程在JVM和操作系统调度下的真实行为。476 收藏
Java线程有六种状态:NEW、RUNNABLE、BLOCKED、WAITING、TIMED_WAITING、TERMINATED;它们是Thread类中可直接通过getState()读取的真实枚举值,反映线程在JVM和操作系统调度下的真实行为。476 收藏