-
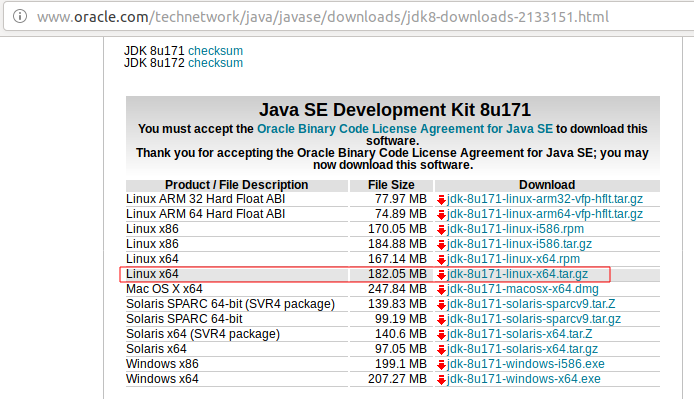
1.oracle官网下载压缩包点击链接2.解压tar-zxvfjdk-8u171-linux-x64.tar.gz3.移动到制定目录##将文件从下载目录挪到/usr/local下sudomvjdk1.8.0_171/usr/local/jdk1.84.设置环境变量vim/etc/profile在文件末尾加入exportJAVA_HOME=/usr/local/jdk1.8exportJRE_HOME=${JAVA_HOME}/jreexportCLASSPATH=.:${JAVA_HOME}/lib:${
-

如何设置CentOS系统以防止恶意程序的自动更新摘要:恶意程序的自动更新可能会给我们的CentOS系统带来严重的安全威胁,因此我们需要采取相应的措施来防止其自动更新。本文将介绍如何设置CentOS系统以防止恶意程序的自动更新,并给出相应的代码示例。禁用自动更新服务CentOS系统默认会自动使用yum服务进行软件包的更新,我们可以通过修改yum的配置文件来禁用
-

作为现代互联网世界的必要组成部分,API(应用程序编程接口)的重要性越来越受到重视。毫无疑问,API极大地促进了互联网生态系统的发展,因为它简化了不同应用之间的交互和通信,还能帮助开发者提高效率和节省时间。因此,越来越多的网站和服务正在将自己转变成为API,以便吸引更多的用户和开发者来使用。但是,将一个网站变成API的过程可能会带来很大的麻烦。一方面,需要在
-

在使用Linux系统时,经常会遇到文件权限问题。文件权限是指对文件或目录的访问权限控制,主要分为读取(r)、写入(w)和执行(x)三种权限。合理设置文件权限可以保护文件的安全性,但不正确的设置可能导致文件无法访问或被未授权的用户修改。本文将介绍几种常见的文件权限问题及其解决办法。文件无法执行当我们在执行一个脚本或可执行文件时,有时会遇到文件无法执行的问题。这
-

Linux中重新启动服务是非常常见的操作,通常可以通过以下步骤来完成:停止服务:首先需要停止原有的服务,确保在重新启动之前服务已经正常关闭。可以使用以下命令来停止服务,以Nginx服务为例:sudosystemctlstopnginx重新启动服务:一旦旧服务已停止,可以通过以下命令来重新启动服务:sudosystemctlstartngin
-

Linux系统的引导过程中,MasterBootRecord(MBR)扮演着至关重要的角色。MBR是位于硬盘的第一个扇区,通常为512字节,包含了引导操作系统所需的关键信息。本文将深入探讨LinuxMBR的功能与原理,同时提供具体的代码示例帮助读者更好地理解。MBR的功能与结构MBR的作用主要包括以下几个方面:引导加载器:MBR包含引导加载器(Boot
-

如何通过Linux运维技术跳槽涨薪随着信息技术的快速发展,Linux运维技术在当前的IT行业中变得越来越重要。Linux作为一种开源的操作系统,具有稳定性、安全性以及高度的灵活性,因此越来越多的企业开始采用Linux作为他们的主要操作系统。因此,具备良好的Linux运维技术将会成为一个很有竞争力的优势。通过提升自己的Linux运维技术,你不仅可以在现有岗位上
-

ps的%MEM不靠谱,因按RSS统计且重复计算共享内存;USS反映独占内存,PSS按进程数均摊共享页更合理;pmap-x看shared估算共享量,/proc/pid/smaps可精确获取PSS和USS。
-

答案:使用history命令可查看、限制、清除及搜索Linux命令历史,并执行特定记录。通过history显示全部或指定条数命令,用!编号重执行某条,Ctrl+R搜索关键词,history-c清空记录并删除~/.bash_history文件,编辑.bashrc修改HISTSIZE和HISTFILESIZE控制保存数量。
-

1.sar、iotop和perf是Linux性能监控三大工具,分别用于宏观趋势分析、实时I/O监控和底层事件追踪。sar能收集历史数据,支持CPU、内存、磁盘等多维度统计;iotop实时展示I/O大户进程;perf深入代码级性能分析。2.定位CPU瓶颈时,先用top/htop查看高CPU进程,再结合sar-u分析用户态、系统态或I/O等待占比,%us高则用perftop分析热点函数,%sy高则统计系统调用次数,%wa高则转向iotop排查I/O问题。3.排查内存泄露或交换空间使用时,先用free-h查看整
-

需用chattr命令设置文件不可修改等隐藏属性,lsattr命令查看属性状态;chattr+i使文件完全不可修改删除,+a仅允许追加;操作需root权限且仅ext2/3/4/xfs等文件系统支持。
-

要管理Linux系统服务,首先要掌握systemd及配套工具。1.启动服务用sudosystemctlstart服务名;2.停止服务用sudosystemctlstop服务名;3.重启服务用sudosystemctlrestart服务名;4.重载配置用sudosystemctlreload服务名;5.查看状态用systemctlstatus服务名;6.设置开机启动用sudosystemctlenable服务名;7.禁止开机启动用sudosystemctldisable服务名;8.查看所有服务单元用syst
-

设置环境变量的方法取决于生效范围和使用场景。1.临时设置:使用export命令,如exportMY_VARIABLE="HelloWorld",仅在当前终端会话有效,关闭后失效;2.用户级别永久设置:将变量写入~/.bash_profile(用于登录Shell)或~/.bashrc(用于非登录交互式Shell),并执行source使其生效;3.系统级别永久设置:修改/etc/profile或在/etc/profile.d/目录下创建脚本文件,需管理员权限,新用户登录后生效;选择配置文件时,若希望所有用户生
-

使用iftop可查看网卡实时流量,支持按连接排序,需sudo权限;2.nethogs按进程显示带宽占用,便于定位高消耗程序;3.sar-nDEV1提供每秒刷新的接口流量统计,含接收与发送速率;4.bmon以文本图形界面展示速率趋势和网络负载。根据需求选择工具:连接监控用iftop,进程排查用nethogs,历史数据用sar,可视化选bmon,多数命令需root权限运行。
-

Linux网络故障排查的起点是检查物理层与链路层连通性,逐步深入IP配置、路由、DNS、防火墙、服务状态及抓包分析。1.首先确认网线连接正常,使用iplinkshow或ifconfig-a查看网卡状态是否UP,DOWN则用命令激活;2.通过ipashow确认IP地址配置正确,iprshow检查默认路由是否存在;3.用ping测试本机、网关、外网IP和域名解析,判断问题层级;4.cat/etc/resolv.conf或resolvectlstatus确认DNS配置,dig或nslookup测试域名解析;5.