MySQL索引优化之分页探索详细介绍
来源:脚本之家
时间:2022-12-31 08:49:42 442浏览 收藏
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《MySQL索引优化之分页探索详细介绍》,聊聊索引、Mysql分页,我们一起来看看吧!
MySQL索引优化之分页探索
表结构
CREATE TABLE `demo` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄', `position` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '职位', `card_num` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '工卡号', PRIMARY KEY (`id`), KEY `index_union` (`name`,`age`,`position`) ) ENGINE=InnoDB AUTO_INCREMENT=450003 DEFAULT CHARSET=utf8; 450003条数据
limit分页执行情况
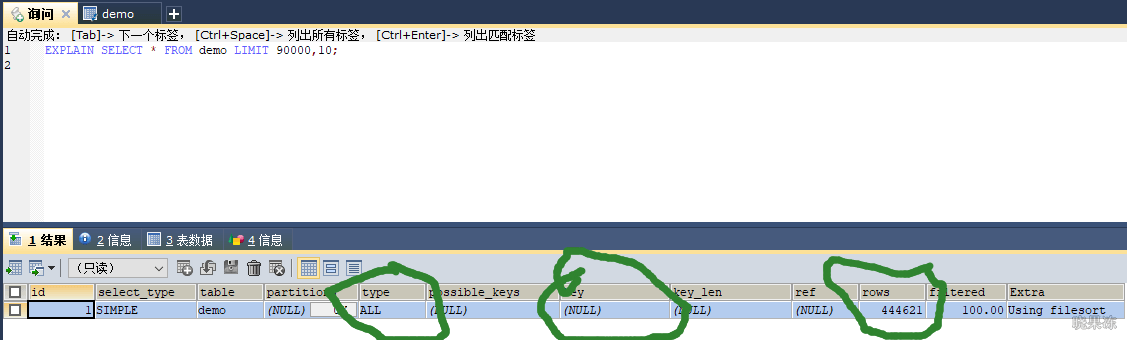
像select * from demo limit 90000,10;考虑到回表,所以mysql干脆选择全表扫描。
mysql不是直接从第90000行开始计算10条,而是从第一个叶子节点开始计数,计算90010行。
案例一
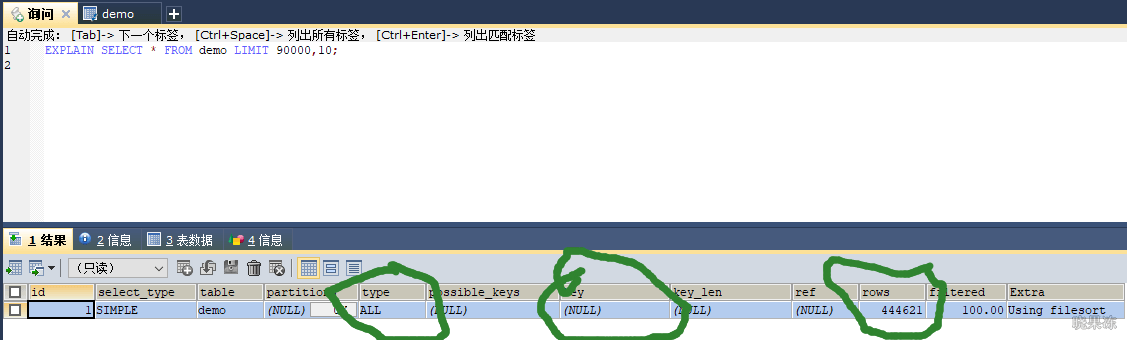
针对上图,当id是连续自增的时候,可以用主键筛选出id=90000之后的数据。因为主键的索引是B+树结构,本身就是有序的。
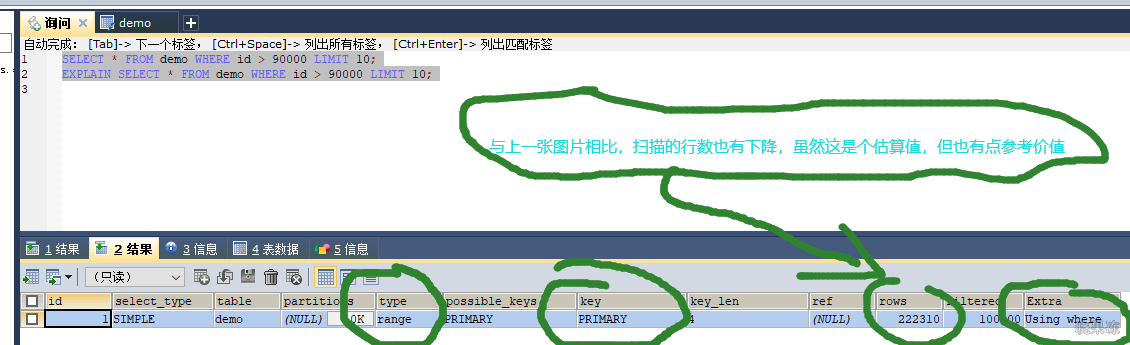
案例二
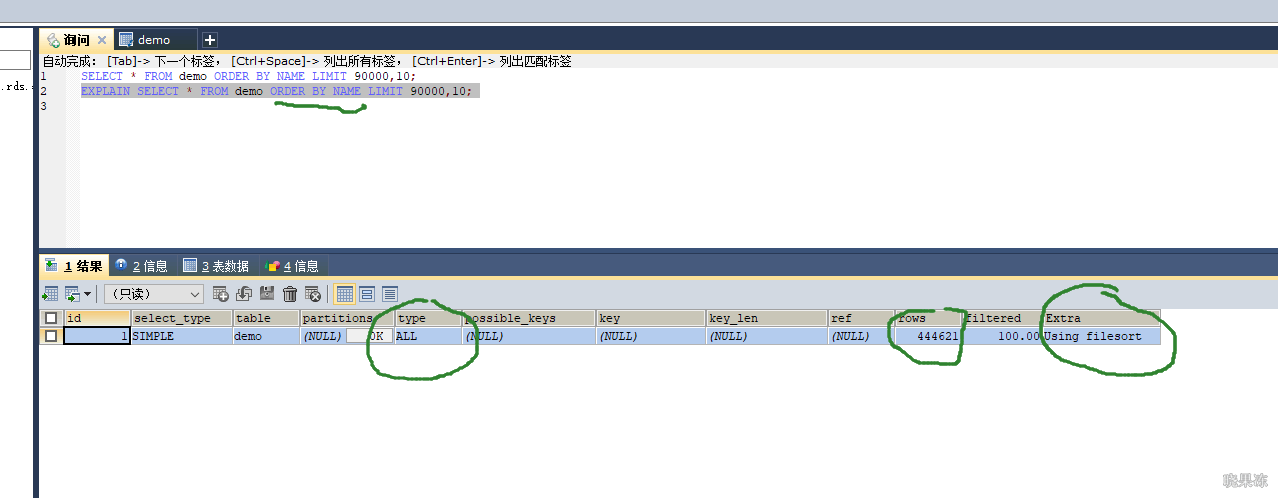
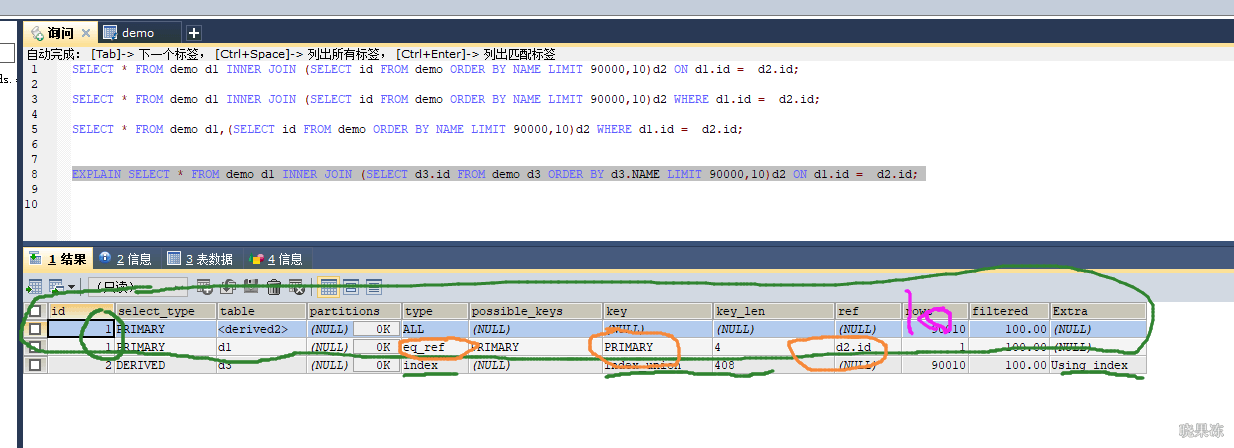
先按照name排序,然后再从第90000行起找10行,虽然name是索引,但select的列在index_union索引树上并没有保存。
所以还会涉及到回表,于是mysql直接选择扫主键索引树的叶子结点,先将40多万数据根据name排好序,然后计算90000行+10行。
优化方法:利用子查询解决最消耗时间的排序和回表问题,联合索引树种保存有主键id,order by name的话可以将name、age、position整个索引充分使用因为确定了最左列的排序,其余的俩列age、和position其实也是
排好序的了,通过Extra字段也可以是使用了索引树做排序。
最外层的查询是根据主键来关联的,所以几乎可以忽略。10+10 因为id是主键,可以直接拿临时表10条数据去扫。
到此这篇关于MySQL索引优化之分页探索详细介绍的文章就介绍到这了,更多相关MySQL分页探索内容请搜索golang学习网以前的文章或继续浏览下面的相关文章希望大家以后多多支持golang学习网!
今天关于《MySQL索引优化之分页探索详细介绍》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于mysql的内容请关注golang学习网公众号!
-
234 收藏
-
151 收藏
-
109 收藏
-
377 收藏
-
104 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 雪白的流沙
- 细节满满,已收藏,感谢博主的这篇文章,我会继续支持!
- 2023-03-02 18:32:31
-
- 优雅的乌龟
- 这篇技术贴出现的刚刚好,好细啊,感谢大佬分享,收藏了,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-02-19 14:17:37
-
- 怕黑的蜗牛
- 这篇技术文章真是及时雨啊,细节满满,很好,码起来,关注楼主了!希望楼主能多写数据库相关的文章。
- 2023-02-18 06:45:06
-
- 魁梧的灯泡
- 感谢大佬分享,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者大大分享文章内容!
- 2023-02-05 06:13:16
-
- 笑点低的宝马
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢大佬分享文章!
- 2023-01-07 13:18:02
-
- 追寻的朋友
- 这篇文章内容真是及时雨啊,太细致了,很棒,码起来,关注作者了!希望作者能多写数据库相关的文章。
- 2023-01-06 22:34:36
-
- 等待的硬币
- 这篇技术文章真是及时雨啊,老哥加油!
- 2023-01-05 21:51:59
-
- 傻傻的舞蹈
- 很详细,已收藏,感谢师傅的这篇文章,我会继续支持!
- 2023-01-03 13:11:32
-
- 合适的太阳
- 这篇技术文章出现的刚刚好,细节满满,赞 ??,mark,关注大佬了!希望大佬能多写数据库相关的文章。
- 2022-12-31 22:53:42