聊聊Memcache转Redis有关缓存的“坑”
来源:51cto
时间:2023-01-24 14:55:28 145浏览 收藏
在数据库实战开发的过程中,我们经常会遇到一些这样那样的问题,然后要卡好半天,等问题解决了才发现原来一些细节知识点还是没有掌握好。今天golang学习网就整理分享《聊聊Memcache转Redis有关缓存的“坑”》,聊聊Redis、缓存、Memcache,希望可以帮助到正在努力赚钱的你。
【golang学习网.com原创稿件】在高并发场景下,很多人都把 Cache(高速缓冲存储器)当做可以“续命”的灵丹妙药,哪里高并发压力大,哪里就上传 Cache 来解决并发问题。
但有时候,即使使用了 Cache,却发现系统依然卡顿宕机,是因为 Cache 技术不好吗?非也,其实这是缓存的治理工作没有做好。
2018 年 5 月 18-19 日,由 golang学习网 主办的全球软件与运维技术峰会在北京召开。
在 19 日下午“高并发与实时处理”分会场,同程艺龙机票事业群 CTO 王晓波带来了《高并发场景的缓存治理》的主题演讲。
他针对如何让缓存更适合高并发使用、如何正确使用缓存、如何通过治理化解缓存问题等热点展开了阐述。
对于我们来说,我们是 OTA 的角色,所以有大量的数据要计算处理变为可售卖商品,总的来说是“商品搬运工,而非生产商”。
所以面对各种大数据并发运行的应用场景,我们需要通过各种缓存技术来提升服务的质量。
想必大家都听说过服务的治理和数据的治理,那么是否听说过缓存的治理呢?诚然,在许多场景下,Cache 成了应对各处出现高并发问题的一颗“银弹”。
但是它并非是放之四海皆准的,有时它反而成了一颗导致系统“挂掉”的自杀子弹。有时候这种原因的出现并非 Cache 本身的技术不好,而是我们没有做好治理。
下面,我们将从三个方面来具体讨论缓存的治理:
缓存使用中的一些痛点
如何用好缓存,用正确缓存
如何通过治理让缓存的问题化为无形
缓存使用中的一些痛点
我们同程的业务特点是:OTA 类商品,没有任何一个价格是固定的。像酒店,客户今天订、明天订、连续订三天、订两天,是否跨周末,他们最后得出的价格都是不一样的。
价格随着时间的变化而波动的。这些波动会引发大量的计算,进而带来性能上的损耗。
要解决性能的损耗问题,我们势必要插入各种 Cache,包括:价格的 Cache、时间段的 Cache、库存的 Cache。而且这些 Cache 的写入数据量远大于整个外部的请求数据量,即:写多于读。
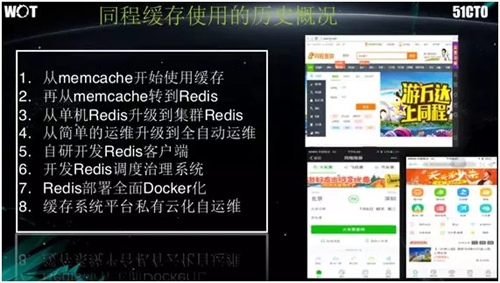
下面介绍同程缓存使用的历史:
一开始,我们仅使用一台 Memcache 来提供缓存服务。
后来,我们发现 Memcache 存在着支持并发性不好、可运维性欠佳、原子性操作不够、在误操作时产生数据不一致等问题。
因此,我们转为使用 Redis,以单线程保证原子性操作,而且它的数据类型也比较多。当有一批新的业务逻辑被写到 Redis 中时,我们就把它当作一个累加计数器。
当然,更有甚者把它当作数据库。由于数据库比较慢,他们就让数据线先写到 Redis,再落盘到数据库中。
随后,我们发现在单机 Redis 的情况下,Cache 成了系统的“命门”。哪怕上层的计算尚属良好、哪怕流量并不大,我们的服务也会“挂掉”。于是我们引入了集群 Redis。
同时,我们用 Java 语言自研了 Redis 的客户端。我们也在客户端里实现了二级 Cache。不过,我们发现还是会偶尔出现错乱的问题。
后来,我们还尝试了分布式 Cache,以及将 Redis 部署到 Docker 里面。
最终,我们发现这些问题都是跟场景相关。如果你所构建的场景较为紊乱,则直接会导致底层无法提供服务。
下面我们来看看有哪些需要治理的场景,通俗地说就是有哪些“坑”需要“填”。
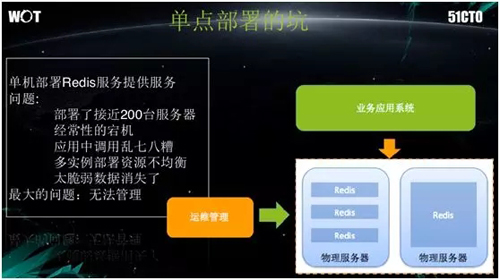
早期在单机部署 Redis 服务的时代,我们针对业务系统部署了一套使用脚本运维的平台。
当时在一台虚机上能跑六万左右的并发数据,这些对于 Redis 服务器来说基本够用了。
但是当大量部署,并达到了数百多台时,我们碰到了两个问题:
面对高并发的性能需求,我们无法单靠脚本进行运维。一旦运维操作出现失误或失控,就可能导致 Redis 的主从切换失败,甚至引起服务宕机,从而直接对整个业务端产生影响。
应用调用的凌乱。在采用微服务化之前,我们面对的往往是一个拥有各种模块的大系统。
而在使用场景中,我们常把 Redis 看成数据库、存有各种工程的数据源。同时我们将 Cache 视为一个黑盒子,将各种应用数据都放入其中。
例如,对于一个订单交易系统,你可能会把订单积分、订单说明、订单数量等信息放入其中,这样就导致了大量的业务模块被耦合于此,同时所有的业务逻辑数据块也集中在了 Redis 处。
那么就算我们去拆分微服务、做代码解耦,可是多数情况下缓存池中的大数据并没有得到解耦,多个服务端仍然通过 Redis 去共享和调用数据。
一旦出现宕机,就算你能对服务进行降级,也无法对数据本身采取降级,从而还是会导致整体业务的“挂掉”。
脆弱的数据消失了。由于大家都习惯把 Redit 当作数据库使用(虽然大家都知道在工程中不应该如此),毕竟它不是数据库,没有持久性,所以一旦数据丢失就会出现大的麻烦。
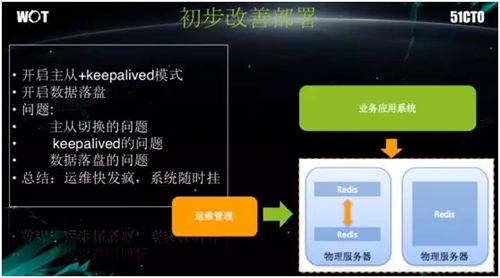
为了防止单台挂掉,我们可以采用多台 Redis。此时运维和应用分别有两种方案:
运维认为:可以做“主从”,并提供一个浮动的虚拟 IP(VIP)地址。在一个节点出现问题时,VIP 地址不用变更,直接连到下一个节点便可。
应用认为:可以在应用客户端里写入两个地址,并采取“哨兵”监控,来实现自动切换。
这两个方案看似没有问题,但是架不住 Redis 的滥用。我们曾经碰到过一个现实的案例:如上图右下角所示,两个 Redis 根据主从关系可以互相切换。
按照需求,存有 20G 数据的主 Redis 开始对从 Redis 进行同步。此时网络出现卡顿,而应用正好发现自己的请求也相应变慢了,因此上层应用根据网络故障采取主从切换。
然而此时由于主从 Redis 正好处于同步状态,资源消耗殆尽,那么在上次应用看来此时主从 Redis 都是不可达的。
我们经过深入排查,最终发现是在 Cache 中某个表的一个 Key 中,被存放了 20G 的数据。
而在程序层面上,他们并没有控制好该 Key 的消失时间(如一周),因而造成了该 Key 被持续追加增大的状况。
由上可见,就算我们对 Redis 进行了拆分,这个巨大的 Key 仍会存在于某一个“片”上。

如上图所示,仍以 Redis 为例,我们能够监控的方面包括:
当前客户端的连接数
客户端的输出与输入情况
是否出现堵塞
被分配的整个内存总量
主从复制时的状态信息
集群的情况
各服务器每秒执行的命令数量
可以说,这些监控的方面并不能及时地发现上述 20 个 G 的 Key 数据。再比如:通常系统是在客户下订单之后,才增加会员积分。
但是在应用设计上却将核心订单里的核心 Key,与本该滞后增加的积分辅助进程,放在了同一个实例之中。
由于我们能够监控到的都是些延迟信息,因此这种将级别高的数据与级别低的数据混淆的情况,是无法被监控到的。

上面是一段运维与开发的真实对话,曾发生在我们公司内部的 IM 上,它反映了在 DevOps 推进之前,运维与开发之间的矛盾。
开发问:Redis 为什么不能访问?
运维答:刚才服务器因内存故障自动重启了。其背后的原因是:一个 Cache 的故障导致了某个业务的故障。业务认为自己的代码没有问题,原因在于运维的 Cache 上。
开发问:为什么我的 Cache 的延迟这么大?
运维答:发现开发在此处放了几万条数据,从而影响了插入排序。
开发问:我写进去的 Key 找不到?肯定是 Cache 出错了。这其实是运维 Cache 与使用 Cache 之间的最大矛盾。
运维答:你的 Redis 超过最大限制了,根本就没写成功,或者写进去就直接被淘汰了。这就是大家都把它当成黑盒所带来的问题。
开发问:刚刚为何读取全部失败?
运维答:网络临时中断,在全同步完成之前,从机的读取全部失败了。这是一个非常经典的问题,当时运维为了简化起见,将主从代替了集群模式。
开发问:我的系统需要 800G 的 Redis,何时能准备好?
运维答:我们线上的服务器最大只有 256 G。
开发问:为什么 Redis 慢得像驴一样,是否服务器出了故障?
运维答:对千万级的 Key,使用 Keys*,肯定会慢。
由上可见这些问题既有来自运维的,也有来自开发的,同时还有当前技术所限制的。
我们在应对并发查询时,只注重它给我们带来的“快”这一性能特点,却忽略了对 Cache 的使用规范,以及在设计时需要考虑到的各种本身缺点。
如何用好缓存,用正确缓存?

因此在某次重大故障发生之后,我们总结出:没想到初始状态下只有 30000 行代码的小小 Redis 竟然能带来如此神奇的功能。
以至于它在程序员手中变成了一把“见到钉子就想锤的锤子”,即:他们看见任何的需求都想用缓存去解决。
于是他们相继开发出来了基于缓存的日志搜集器、倒计时、计数器、订单系统等,却忘记了它本身只是一个 Cache。一旦出现了故障,它们将如何去保证其本身呢?
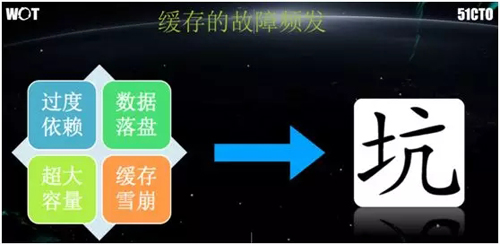
下面我们来看看缓存故障的具体因素有哪些?
过度依赖
即:明明不需要设置缓存之处,却非要用缓存。程序员们常认为某处可能会在将来出现大的并发量,故放置了缓存,却忘记了对数据进行隔离,以及使用的方式是否正确。
例如:在某些代码中,一个函数会执行一到两百次 Cache 的读取,通过反复的 get 操作,对同一个 Key 进行连续的读取。
试想,一次并发会带给 Redis 多少次操作呢?这些对于 Redis 来说负载是相当巨大的。
数据落盘
这是一个高频次出现的问题。由于大家确实需要一个高速的 KV 存储,来实现数据落盘需求。
因此他们都会把整个 Cache 当作数据库去使用,将任何不允许丢失的数据都放在 Cache 之中。
即使公司有各种使用规范,此现象仍是无法杜绝。最终我们在 Cache 平台上真正做了一个 KV 数据库供程序员们使用,并且要求他们在使用的时候,必须声明用的是 KV 数据库还是 Cache。
超大容量
由于大家都知道“放到内存里是最快的”,因此他们对于内存的需求是无穷尽的。更有甚者,有人曾向我提出 10 个 T 容量的需求,而根本不去考虑营收上的成本。
雪崩效应
由于我们使用的是大量依赖于缓存的数据,来为并发提供支撑,一旦缓存出现问题,就会产生雪崩效应。
即:外面的流量还在,你却不得不重启整个缓存服务器,进而会造成 Cache 被清空的情况。
由于断绝了数据的来源,这将导致后端的服务连片“挂掉”。为了防止雪崩的出现,我们会多写一份数据到特定磁盘上。
其数据“新鲜度”可能不够,但是当雪崩发生时,它会被加载到内存中,以防止雪崩的下一波冲击,从而能够顺利地过渡到我们重新将“新鲜”的数据灌进来为止。

我们对上面提到的“坑”总结一下:
最厉害的是:使用者乱用、滥用和懒用。如前例所说,我们平时对于缓存到底在哪里用、怎么用、防止什么等方面考虑得实在太少。
运维数千台毫无使用规则的缓存服务器。我们常说 DevOps 的做法是让应用与运维靠得更近,但是针对缓存进行运维时,由于应用开发都不关心里面的数据,又何谈相互靠近呢?
运维不懂开发,开发不懂运维。这导致了缓存系统上各自为政,无法真正地应用好 Cache。
缓存在无设计、无控制的情况下被使用。一般情况下 JVM 都能监控到内存的爆涨,并考虑是否需要回收。但是如前例所示,在出现了一个 Key 居然有 20G 大小时、我们却往往忽视了一个 Key 在缓存服务器上的爆涨。
开发人员能力的不同。由于不可能要求所有的开发人员都是前端工程师,那么当你这个团队里面有不同经验的人员时,如何让他们能写出同样规范的代码呢?
毕竟我们做的是工程,需要更多的人能够保证写出来的代码不会发生上述的问题。
太多的服务器资源被浪费。特别是 Cache 的整体浪费是非常巨大的。无论并发量高或低,是否真正需要,大家都在使用它的内存。
例如:在我们的几千台 Cache Server 中,最高浪费量可达 60%。一些只有几百或几千 KPS 要求的系统或数据也被设计运行在了 Cache 昂贵的内存中。
而实际上它们可能仅仅是为了应对一月一次、或一年一次促销活动的 Cache 高峰需求。
懒人心理,应对变化不够快。应对高并发量,十个程序员有五个会说:为数据层添加 Cache,而不会真正去为架构做长远的规划。
如何通过治理让缓存的问题化为无形
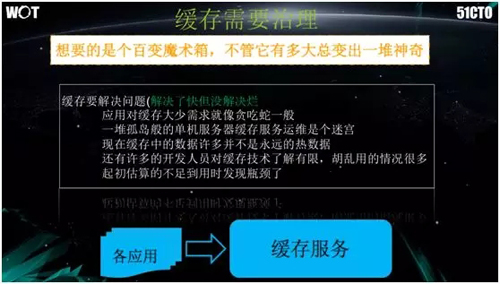
那么到底缓存应当如何被治理呢?从真正的开发哲学角度上说,我们想要的是一个百变的魔术箱,它能够快速地自我变化与处理,而不需要开发和运维人员担心滥用的问题。
另外,其他需要应对的方面还包括:应用对缓存大小的需求就像贪吃蛇一般,一堆孤岛般的单机服务器,缓存服务运维则像一个迷宫。
因此,我们希望构建的是一种能适用各种应用场景的缓存服务,而不是冷冰冰的 Cache Server。

起初我们尝试了各种现成的开源方案,但是后来发现它们或多或少存在着一些问题。
例如:
Cachecloud,对于部署和运维方面欠佳。
Codis,本身做了一个很大的集群,但是我们考虑到当这么一个超大池出现问题时,整个团队在应对上会失去灵活性。
例如:我们会担心业务数据块可能未做隔离,就被放到了池中,那么当一个实例“挂掉”时,所有的数据块都会受到影响。
Pika,虽然可以使用硬盘,但是部署方式很少。
Twemproxy,只是代理见长,其他的能力欠佳。

后来,我们选择自己动手,做了一个 phoenix 的方案。整个系统包含了客户端、运维平台、以及存储扩容等方面。
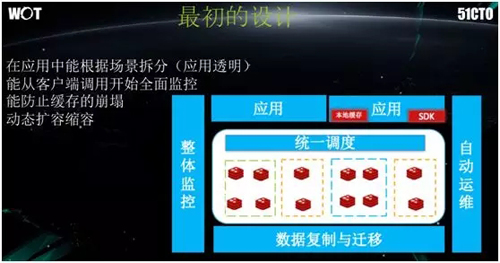
在最初期的架构设计上,我们只让应用端通过简单的 SDK 去使用该系统。
为了避免服务端延续查找 Cache Server 的模式,我们要求应用事先声明其项目和数据场景,然后给系统分配一个 Key。SDK 籍此为应用分配一个新的或既有的缓存仓库。
如上图所示,为了加快速度,我们将缓存区分出多个虚拟的逻辑池,它们对于上层调度系统来说就是一个个的场景。
那么应用就可以籍此申请包含需要存放何种数据的场景,最后根据所分配到的 Key 进行调用。
此处,底层是各种数据的复制和迁移,而两边则是相应的监控和运维。

但是在系统真正“跑起来”的时候,我们发现很难对其进行部署和扩容,因此在改造时,我们做重了整个缓存客户端 SDK,并引入了场景的配置。
我们通过进行本地缓存的管理,添加过滤条件,以保证客户端读取缓存时,能够知道具体的数据源和基本的协议,从而判断出要访问的是 Redis、还是 MemCache、或是其他类型的存储。

在 Cache 客户端做好之后,我们又碰到了新的问题:由于同程使用了包括 Java、.Net、Go,Node.js 等多种语言的开发模式,如果为每一种语言都准备和维护一套 Cache 的客户端的话,显然非常耗费人力。
同时,对于维护来说:只要是程序就会有 Bug,只要有 Bug 就需要升级。一旦所有事业部的所有应用都要升级 SDK,那么对于所有嵌套应用的中间件来说,都要进行升级测试,这将会牵扯到巨大的回归量。
可以说这样的反复测试几乎是不现实的。于是我们需要做出一个代理层,通过把协议、过滤、场景等内容下沉到 Proxy 中,以实现SDK的整体轻量化。
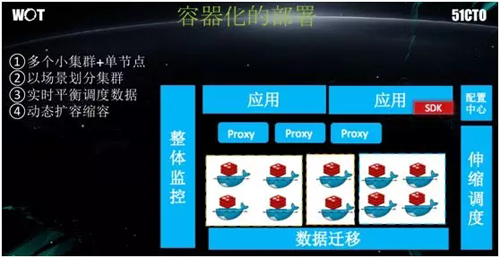
与此同时,我们在部署时也引入了容器,将整个 Redis 都运行在容器之中,并让容器去完成整个应用的部署。
通过容器化的部署,集群的建立变得极其简单,我们也大幅丰富了集群的方案。
我们实现了为每个应用场景都能配有一个(或一种)Key,并且被一个(或一种)集群来服务。
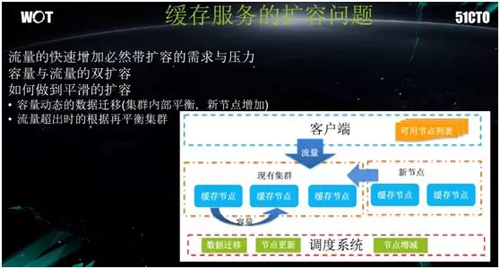
众所周知,Redis 虽然实现了迁移扩容,但是其操作较为复杂。因此我们自行研发了一套迁移调度系统,自动化地实现了从流量扩容到数据扩容、以及从纵向到横向的扩容。
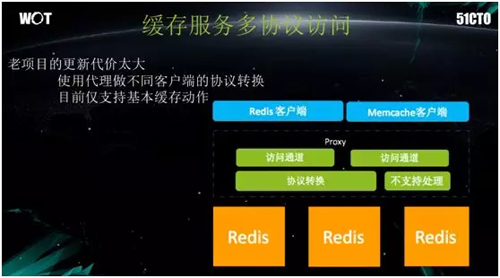
如前所述,我们有着 Redis 和 Memcache 两种客户端,它们是使用不同的协议进行访问。因此,我们通过统一的 Proxy 来实现良好的支持。
如今在我们的缓存平台上,运维人员唯一需要做的就是:往该缓存平台里添加一台物理服务器、插上网线、然后系统就能够自动发现新的服务器的加入,进而开启 Redis。
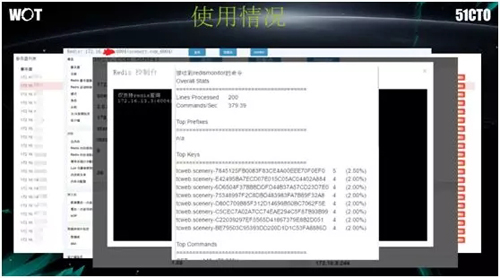
而对于单场景下的 Redis 实例,我们也能够通过控制台,以获取包括 Top10 的 Key、当前访问最多的 Key、Key 的属主、最后由谁执行了写入或修改等多个监控项。
可见,由于上下层都是自建的,因此我们扩展了原来 Redis 里没有的监控项。
上图是 Topkey 使用情况的一个示例,就像程序在故障时经常用到的 Dump 文件一样,它能够反映出后续的各种编排。
王晓波,同程艺龙机票事业群 CTO,专注于高并发互联网架构设计、分布式电子商务交易平台设计、大数据分析平台设计、高可用性系统设计。 设计过多个并发百万以上平台。 拥有十多年丰富的技术架构、技术咨询经验,深刻理解电商系统对技术选择的重要性。
【golang学习网原创稿件,合作站点转载请注明原文作者和出处为golang学习网.com】

好了,本文到此结束,带大家了解了《聊聊Memcache转Redis有关缓存的“坑”》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多数据库知识!
-
286 收藏
-
117 收藏
-
185 收藏
-
426 收藏
-
298 收藏
-
数据库 · Redis | 10小时前 | 数据结构 · Redis · BitMap · 缓存设计 · 签到统计 · redis bitmap 用户签到 SETBIT GETBIT BITCOUNT464 收藏
-
180 收藏
-
数据库 · Redis | 16小时前 | Redis · 消息队列 · Stream · 消费组 · redis 消息队列 Redis Stream 消费组 XREADGROUP XACK XPENDING XAUTOCLAIM187 收藏
-
139 收藏
-
116 收藏
-
111 收藏
-
438 收藏
-
146 收藏
-
476 收藏
-
216 收藏
-
180 收藏
-
326 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习