Python argparse 命令行工具实战:子命令、参数校验和配置合并
来源:17golang原创
时间:2026-06-13 08:18:37 241浏览 收藏
很多 Python 脚本一开始只是临时工具,参数直接写在代码里。用久之后,问题就来了:路径要改、天数要改、是否只预览也要改,最后变成“改一行代码再跑一次”。这时就该把脚本升级成命令行工具。
argparse 是 Python 标准库里的命令行参数解析模块,不需要额外安装。它适合做内部运维脚本、数据处理脚本、批量任务工具,也适合把零散脚本整理成团队可复用的小工具。
摘要
本文用“日志清理工具”做例子,从基础参数解析开始,逐步加入类型校验、布尔开关、子命令、配置文件默认值和环境变量覆盖。最后得到一个更稳的命令行入口:参数来源清楚、错误提示友好、运行前能先预览。
适合人群
适合写过 Python 脚本,但还没有系统整理命令行参数的开发者。你只需要会写函数、理解列表和字典,就能跟着示例改造自己的脚本。
目录
- 从 argv 到 argparse 解析结果
- 给参数加类型、默认值和开关
- 用子命令拆分不同动作
- 配置文件和环境变量如何合并
- 常见坑和上线前检查
一、从 argv 到 argparse 解析结果
先看一个最小版本。我们希望通过命令行传入日志目录、保留天数,并支持只预览不删除。
import argparse
from pathlib import Path
def build_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(
prog="logtool",
description="清理超过指定天数的日志文件",
)
parser.add_argument("--path", required=True, help="日志目录")
parser.add_argument("--days", type=int, default=7, help="保留最近多少天的日志")
parser.add_argument("--dry-run", action="store_true", help="只预览,不删除")
return parser
def main() -> None:
parser = build_parser()
args = parser.parse_args()
log_dir = Path(args.path)
print({"path": str(log_dir), "days": args.days, "dry_run": args.dry_run})
if __name__ == "__main__":
main()
运行示例:
python logtool.py --path ./logs --days 14 --dry-run
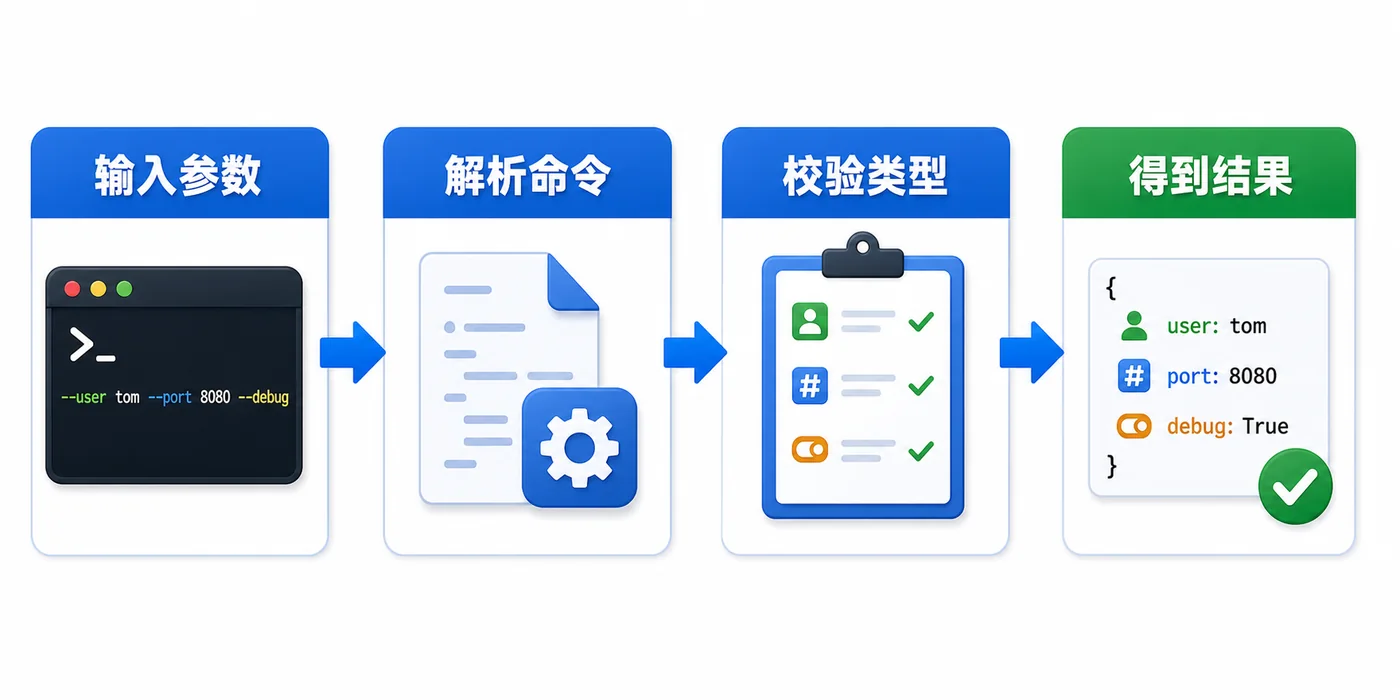
这张图对应 argparse 的核心流程:用户输入参数,解析器把字符串拆成结构化字段,再根据 type 和开关规则做校验,最后交给业务代码使用。这个过程比手动解析 sys.argv 更可靠。
二、给参数加类型、默认值和开关
命令行工具最怕“看起来能跑,但参数其实不合法”。例如保留天数不能小于 1,日志目录也必须存在。可以把检查逻辑放在解析后。
from pathlib import Path
def validate_args(args: argparse.Namespace) -> None:
log_dir = Path(args.path)
if not log_dir.exists():
raise SystemExit(f"日志目录不存在: {log_dir}")
if not log_dir.is_dir():
raise SystemExit(f"不是目录: {log_dir}")
if args.days
再把校验接到 main 里:
def main() -> None:
parser = build_parser()
args = parser.parse_args()
validate_args(args)
print("参数检查通过")
argparse 负责语法层面的解析,比如整数、开关、必填项;业务层面的规则,比如目录是否存在、天数是否合理,建议单独放在校验函数里。这样以后测试和维护都更轻松。
三、用子命令拆分不同动作
当工具动作变多以后,不要把所有参数都塞在一个入口里。比如日志工具可能有三个动作:scan 只扫描,clean 清理,report 输出统计。这时可以用子命令。
def build_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(prog="logtool")
subparsers = parser.add_subparsers(dest="command", required=True)
scan = subparsers.add_parser("scan", help="扫描可清理文件")
scan.add_argument("--path", required=True)
scan.add_argument("--days", type=int, default=7)
clean = subparsers.add_parser("clean", help="清理过期文件")
clean.add_argument("--path", required=True)
clean.add_argument("--days", type=int, default=7)
clean.add_argument("--dry-run", action="store_true")
report = subparsers.add_parser("report", help="输出日志统计")
report.add_argument("--path", required=True)
return parser
子命令的好处是边界清楚。扫描命令不需要删除开关,统计命令不需要保留天数,每个动作只暴露自己真正需要的参数。
python logtool.py scan --path ./logs --days 7 python logtool.py clean --path ./logs --days 30 --dry-run python logtool.py report --path ./logs
四、配置文件和环境变量如何合并
命令行参数适合临时覆盖,但固定配置不适合每次都敲。例如默认日志目录、默认保留天数,可以放到 JSON 配置里;敏感信息或部署环境差异,可以从环境变量读取。
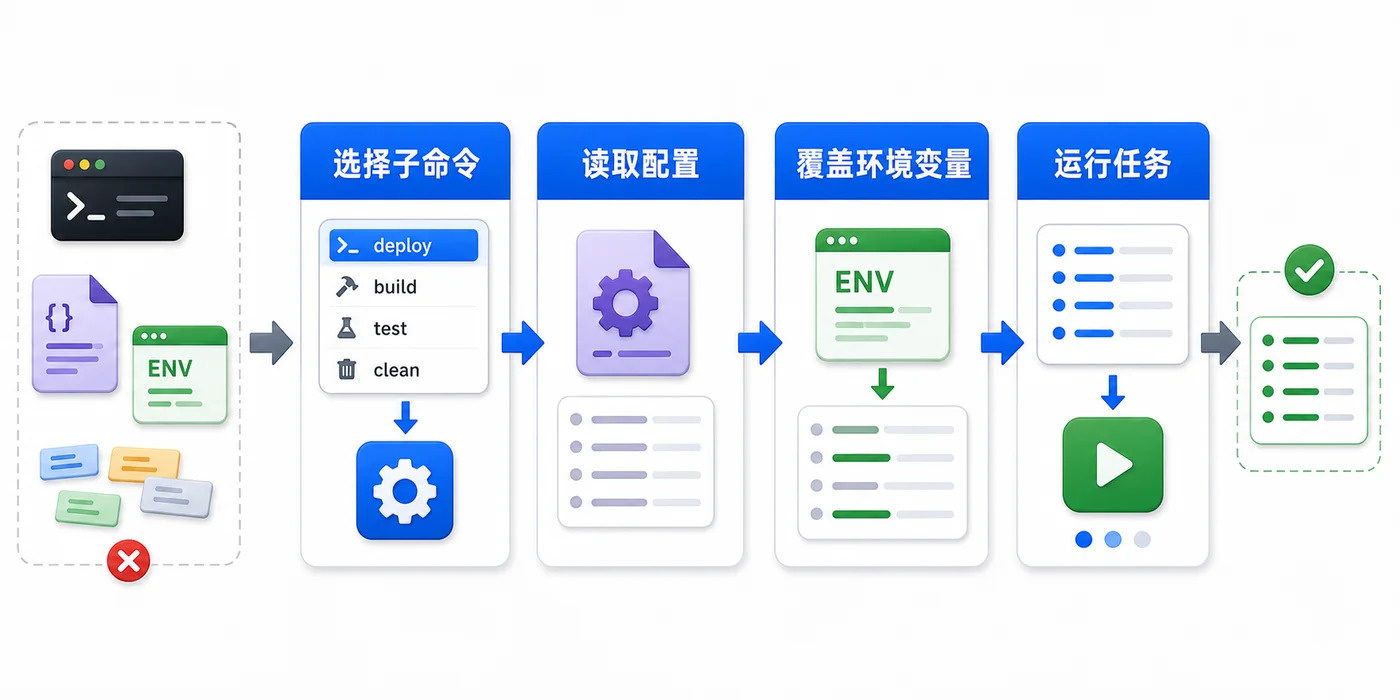
推荐合并顺序是:代码内置默认值
{
"path": "./logs",
"days": 14
}
读取配置并合并:
import json
import os
from dataclasses import dataclass
from pathlib import Path
@dataclass
class CleanOptions:
path: str
days: int
dry_run: bool
def load_config(file_path: str | None) -> dict:
if not file_path:
return {}
path = Path(file_path)
if not path.exists():
raise SystemExit(f"配置文件不存在: {path}")
return json.loads(path.read_text(encoding="utf-8"))
def merge_clean_options(args: argparse.Namespace) -> CleanOptions:
config = load_config(getattr(args, "config", None))
path = args.path or os.getenv("LOGTOOL_PATH") or config.get("path") or "./logs"
days = args.days or int(os.getenv("LOGTOOL_DAYS", config.get("days", 7)))
return CleanOptions(
path=path,
days=days,
dry_run=bool(args.dry_run),
)
注意这里用了 args.path or ...,所以参数定义里要允许不传路径:
clean.add_argument("--config", help="配置文件路径")
clean.add_argument("--path", help="日志目录")
clean.add_argument("--days", type=int, help="保留最近多少天的日志")
clean.add_argument("--dry-run", action="store_true")
这套合并规则能让工具更适合不同环境:本地调试可以直接传参数,服务器上可以放配置文件,流水线里可以用环境变量覆盖。
五、把业务函数接进来
最后把解析结果交给真正的业务函数。示例里为了安全,只打印将要处理的文件,不直接删除。
from datetime import datetime, timedelta
def scan_old_logs(options: CleanOptions) -> list[Path]:
log_dir = Path(options.path)
deadline = datetime.now() - timedelta(days=options.days)
matched: list[Path] = []
for item in log_dir.glob("*.log"):
modified = datetime.fromtimestamp(item.stat().st_mtime)
if modified None:
files = scan_old_logs(options)
for file_path in files:
if options.dry_run:
print(f"[预览] 将清理: {file_path}")
else:
file_path.unlink()
print(f"已清理: {file_path}")
入口分发可以保持简单:
def main() -> None:
parser = build_parser()
args = parser.parse_args()
if args.command == "clean":
options = merge_clean_options(args)
validate_clean_options(options)
run_clean(options)
elif args.command == "scan":
print("扫描模式可以复用 scan_old_logs")
elif args.command == "report":
print("统计模式可以读取目录后输出数量和大小")
常见坑
1. 布尔参数不要写成 type=bool
type=bool 很容易得到反直觉结果。布尔开关建议使用 action="store_true" 或 action="store_false"。
2. required 不要滥用
如果参数可以来自配置文件或环境变量,就不要在命令行层面设置 required=True。否则还没来得及合并配置,解析阶段就已经失败了。
3. 错误提示要告诉用户怎么改
不要只输出“参数错误”。更好的提示是“日志目录不存在: ./logs”,或者“--days 必须大于等于 1”。这类提示能直接指向下一步操作。
上线前检查清单
--help是否能说明每个参数的含义。- 默认值是否安全,尤其是清理、覆盖、删除类工具。
- 是否提供
--dry-run预览模式。 - 参数来自命令行、配置文件、环境变量时,优先级是否清楚。
- 错误提示是否能让使用者知道下一步怎么修。
总结
argparse 不只是把字符串变成变量,它更像命令行工具的入口规范。先用它解析参数,再用校验函数保证业务规则,复杂动作交给子命令,固定配置放到文件和环境变量里。这样写出来的 Python 工具,既适合自己反复使用,也适合交给团队同事运行。
-
369 收藏
-
426 收藏
-
344 收藏
-
412 收藏
-
109 收藏
-
354 收藏
-
429 收藏
-
432 收藏
-
196 收藏
-
文章 · python教程 | 6天前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig324 收藏
-
435 收藏
-
478 收藏
-
文章 · python教程 | 1星期前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理320 收藏
-
321 收藏
-
365 收藏
-
文章 · python教程 | 2星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory228 收藏
-
文章 · python教程 | 2星期前 | 重试机制 · timeout · requests · Python教程 · 接口调试 · Python Http请求 Requests timeout retry 接口排查330 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习