-

宝塔面板软件商店插件列表空白的解决方法包括:一、检查服务器网络连通性;二、重启宝塔服务并清除缓存;三、手动更新软件商店数据源;四、检查并清理hosts中bt.cn绑定;五、切换至国内镜像源。
-

通义万相生成高质量童话插图需锚定核心要素、启用构图保护并复用种子值;具体方法包括:一、结构化提示词驱动;二、线稿转风格化;三、局部重绘强化魔法细节;四、风格迁移统一多图气质;五、种子锁定批量生成角色系列。
-

Go函数冷启动延迟高因main/init中耗时初始化,应移至包级变量+sync.Once;handler须无状态幂等;内存宜设128MB–512MB;所有I/O必须传入context.Context。
-

SpringBootActuator的监控接口需通过权限控制、网络隔离、HTTPS加密及限制暴露端点等方式安全配置。首先,结合SpringSecurity配置拦截规则,仅允许特定角色或IP访问敏感端点;其次,将Actuator部署在内部网络或通过堡垒机访问,避免公网暴露;第三,启用HTTPS确保通信安全;第四,按需暴露必要端点,而非无差别开放全部接口。此外,可自定义HealthIndicator扩展健康检查逻辑,并利用healthgroups划分核心与非核心服务状态,实现更细粒度的健康监测。
-

数据库迁移是用PHP代码描述表结构变更,通过up()和down()方法实现可重复、可回退、跨环境执行;必须新建迁移处理变更,禁止修改已执行文件;migrate按时间戳顺序执行并记录批次,rollback按批回退,fresh会清空重跑但生产禁用。
-

Go语言提示失效的首要原因是gopls未正常运行,需确认其版本、重启服务、检查go.mod存在性及配置中禁用旧工具链。
-

答案:通过反射读取StructTag实现JSON字段映射与动态赋值。首先利用reflect.Type获取结构体字段的json标签,解析标签获取实际JSON键名,构建JSON键到结构体字段的映射表;然后结合reflect.Value根据JSON键查找对应字段并设置值,支持字符串、整数等类型,适用于自定义解码、序列化器等场景,需注意指针传递、字段可设置性及性能优化。
-

应使用原生DB事务、重载JSON访问器、显式赋值触发更新或调整隔离级别与加锁。具体包括:一、用DB::transaction配合json_set或完整JSON字符串更新;二、重载setJsonAttribute并清除脏状态;三、通过casts配置后显式重新赋值JSON字段;四、降低隔离级别至READCOMMITTED或行锁+完整替换+json_encode校验。
-

Apache仅能加载一个PHP模块,多版本共存需通过端口隔离或PHP-FPM代理实现,而非httpd.conf中并行启用多个LoadModule;硬切配置须重启服务,且php.ini路径、扩展兼容性须严格匹配对应PHP版本。
-

Less中用.make-col循环生成响应式列类需基于@grid-columns动态计算宽度,嵌套断点媒体查询,联动声明.make-row负边距与.make-col内边距,并用extract()按需过滤列数与断点以控制CSS体积。
-

2026年毕业生申领租房补贴需满足学历、社保、住房、租赁及单位五类条件:毕业时间须为2026年内且为全日制;社保须由属地用人单位连续缴纳6个月;名下无房(含共有、期房等);租赁合同须住建部门备案且租期≥3个月;用人单位须符合当地资质要求(如注册地、性质等)。
-

实例方法必须带self且只能通过实例调用;@classmethod必须带cls,类和实例均可调用;@staticmethod无隐式参数,适用于不依赖实例或类的纯函数。
-
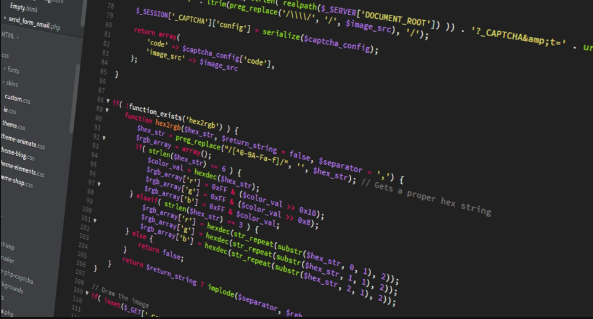
优先选imagettftext():支持TTF字体、旋转、抗锯齿,可防OCR;imagestring()仅限内置1–5号位图字体,无旋转抗锯齿,仅适用于极简验证码。
-

color-mix()必须显式指定颜色空间(如insrgb)并用小数(如0.5)而非裸百分比(如50%)表示权重;不支持calc()等函数动态计算权重,仅限静态值。
-

Java黑名单机制核心是“拦截+校验+持久化”,应置于请求进入业务逻辑前(如Web层Interceptor、RPC层Filter、服务内敏感操作前),避免DAO层硬编码;存储依规模与实时性选型。