Go语言技术文章
-
 Python 调用外部命令超时后,杀掉父进程并不代表子进程和孙进程都结束。本文用 start_new_session 创建独立进程组,再按 TERM、等待、KILL 的顺序清理,并补上超时、权限和回归检查。496 收藏
Python 调用外部命令超时后,杀掉父进程并不代表子进程和孙进程都结束。本文用 start_new_session 创建独立进程组,再按 TERM、等待、KILL 的顺序清理,并补上超时、权限和回归检查。496 收藏 -
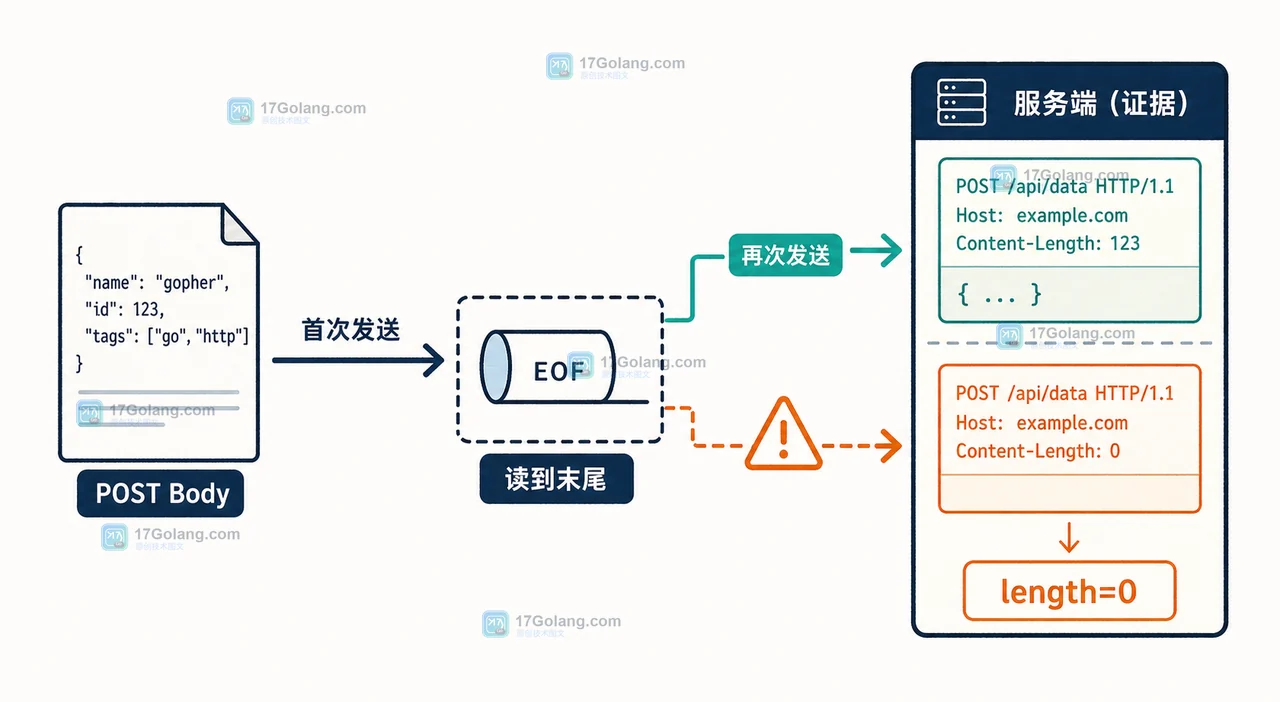 Go 的 POST 请求第一次失败后重试,服务端却读到空 Body,通常不是服务端丢数据,而是请求体只被消费了一次。本文用 bytes.Reader、GetBody 和两次请求日志拆开这个问题,给出可验证的重试写法与边界。488 收藏
Go 的 POST 请求第一次失败后重试,服务端却读到空 Body,通常不是服务端丢数据,而是请求体只被消费了一次。本文用 bytes.Reader、GetBody 和两次请求日志拆开这个问题,给出可验证的重试写法与边界。488 收藏 -
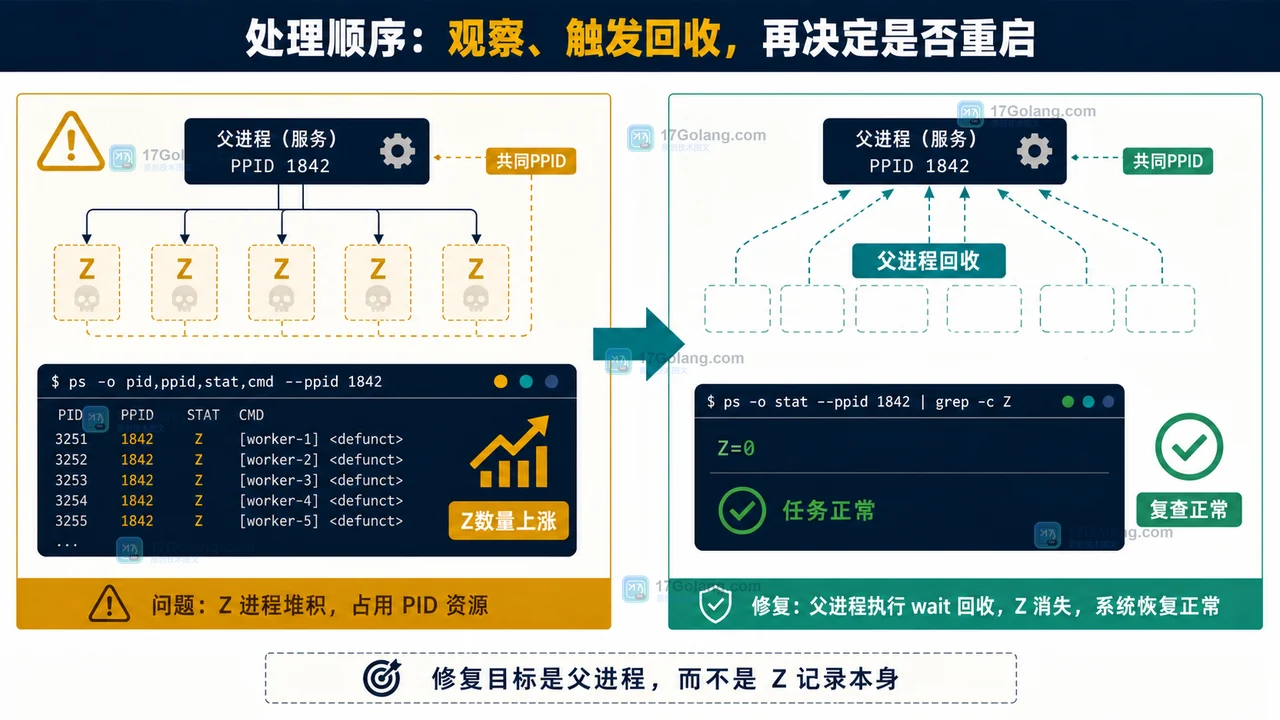 Linux 出现僵尸进程时,进程已经结束,却因为父进程没有回收退出状态而暂时留在进程表里。本文用 ps 的 Z 状态、PPID 和父进程回收逻辑定位问题,再给出可回滚的处理顺序,避免一上来就误杀正常服务。478 收藏
Linux 出现僵尸进程时,进程已经结束,却因为父进程没有回收退出状态而暂时留在进程表里。本文用 ps 的 Z 状态、PPID 和父进程回收逻辑定位问题,再给出可回滚的处理顺序,避免一上来就误杀正常服务。478 收藏 -
 Node.js 26.5.0 新增 Blob.textStream(),返回可读流。本文从 Blob 文本读取场景出发,对比 text()、stream() 和 textStream(),给出逐块处理、编码边界与版本核对方法。468 收藏
Node.js 26.5.0 新增 Blob.textStream(),返回可读流。本文从 Blob 文本读取场景出发,对比 text()、stream() 和 textStream(),给出逐块处理、编码边界与版本核对方法。468 收藏 -
Golang · Go问答 | 1天前 | 标准库 · bufio · 网络协议 · Go问答 · 流式读取 · peek Go bufio.Reader 协议解析 Go问答 Discard UnreadByte
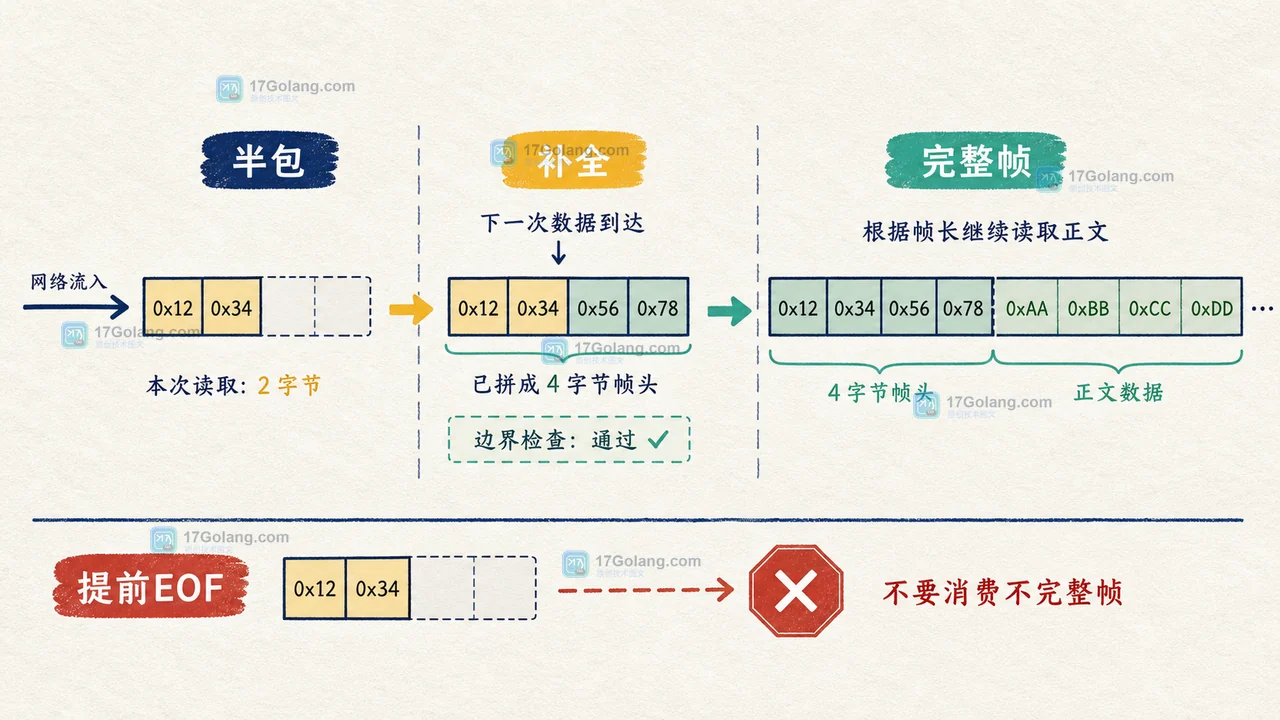 Go 用 bufio.Reader 解析带长度或分隔符的协议时,Peek 只是查看缓冲内容,不会推进读取位置;Discard 才会消费字节。本文用一个简化帧协议拆开 Peek、Read、Discard、UnreadByte 的数据流转和边界处理。414 收藏
Go 用 bufio.Reader 解析带长度或分隔符的协议时,Peek 只是查看缓冲内容,不会推进读取位置;Discard 才会消费字节。本文用一个简化帧协议拆开 Peek、Read、Discard、UnreadByte 的数据流转和边界处理。414 收藏 -
文章 · 前端 | 1天前 | 前端 · javascript · 浏览器性能 · 交互优化 · 数据表格 · 前端 性能优化 requestAnimationFrame 布局抖动 表格列拖拽 Pointer Events
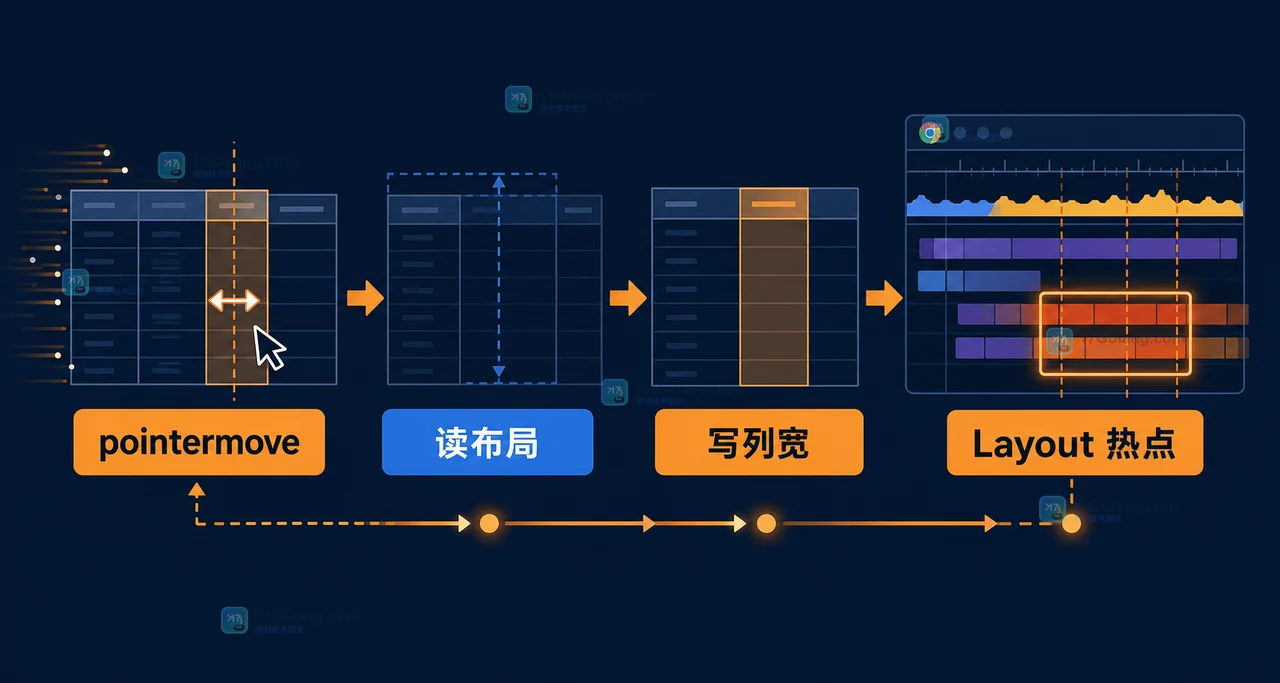 表格列拖拽时出现指针跟不上、列宽抖动和松手后跳回,通常不是 Pointer Events 本身慢,而是每个 pointermove 都同步读写布局。本文用 120Hz 屏幕的可复现场景,比较直接写入与 requestAnimationFrame 合帧方案,并给出最终验收指标与边界。397 收藏
表格列拖拽时出现指针跟不上、列宽抖动和松手后跳回,通常不是 Pointer Events 本身慢,而是每个 pointermove 都同步读写布局。本文用 120Hz 屏幕的可复现场景,比较直接写入与 requestAnimationFrame 合帧方案,并给出最终验收指标与边界。397 收藏 -
 Go 1.26 重写了 go fix,它现在可以借助分析器发现并应用一批安全的现代化改动。本文从一个旧模块升级现场切入,说明如何先扫描、再查看差异、分批应用,并用 go test、go vet 和基准测试确认改动没有越过兼容边界。396 收藏
Go 1.26 重写了 go fix,它现在可以借助分析器发现并应用一批安全的现代化改动。本文从一个旧模块升级现场切入,说明如何先扫描、再查看差异、分批应用,并用 go test、go vet 和基准测试确认改动没有越过兼容边界。396 收藏 -
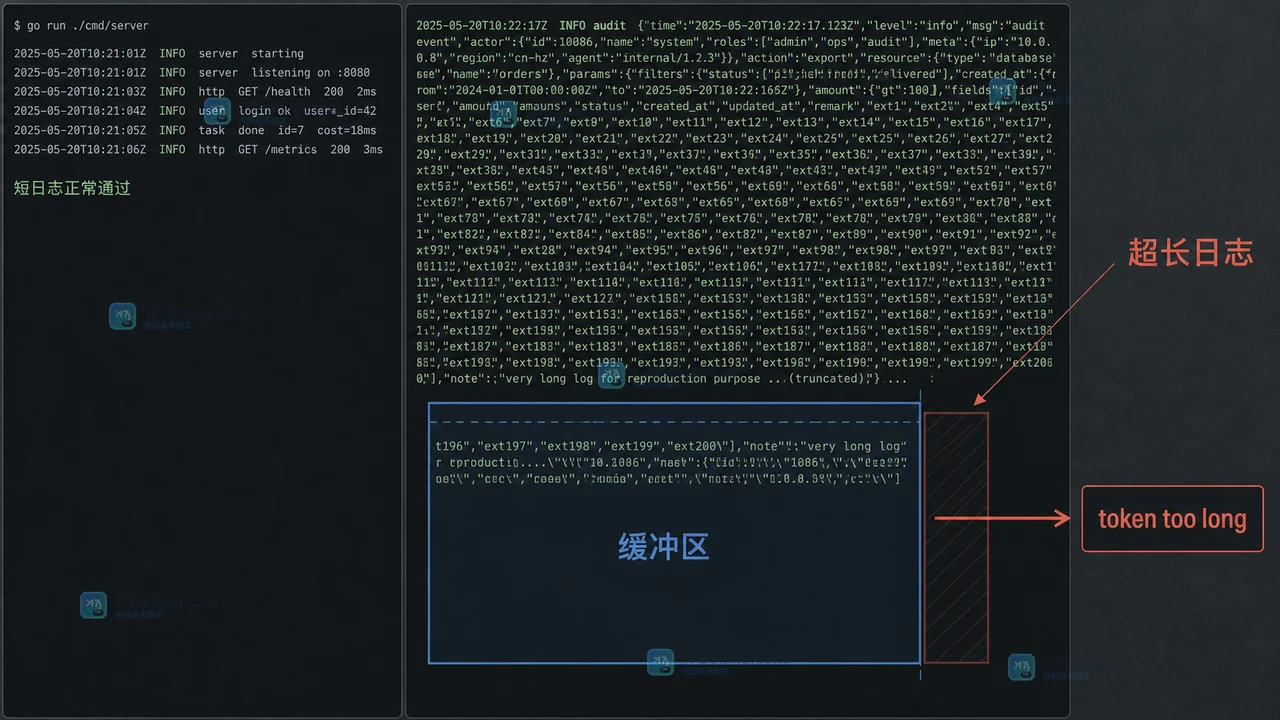 Go 用 bufio.Scanner 读取日志、CSV 或命令输出时,遇到超长行可能直接停止。本文用最小实验复现 token too long,解释 Buffer、MaxScanTokenSize、SplitFunc 的关系,并给出 Scanner 与 bufio.Reader 的选型边界。391 收藏
Go 用 bufio.Scanner 读取日志、CSV 或命令输出时,遇到超长行可能直接停止。本文用最小实验复现 token too long,解释 Buffer、MaxScanTokenSize、SplitFunc 的关系,并给出 Scanner 与 bufio.Reader 的选型边界。391 收藏 -
数据库 · Redis | 1天前 | Redis · go · Pipeline · 批处理 · 重试 · 幂等性 · 重试 go-redis 幂等键 批量写入 Redis Pipeline 逐条结果
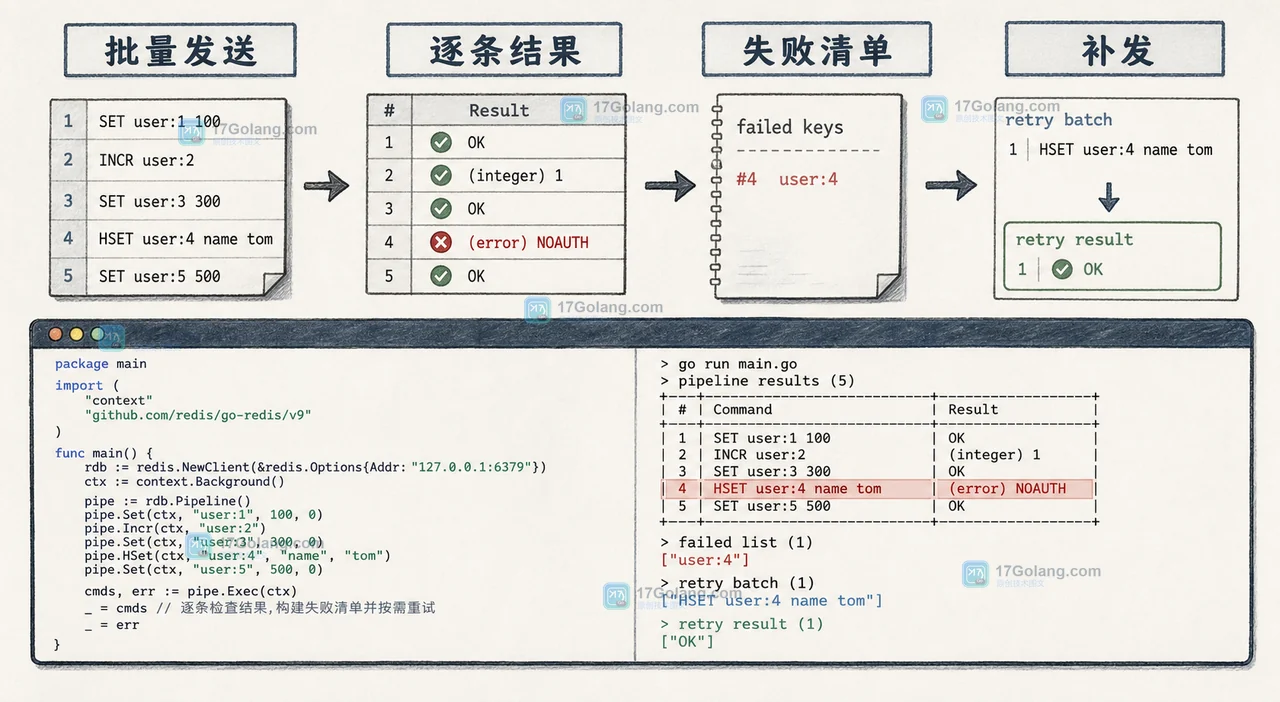 Redis Pipeline 能减少网络往返,却不会把一批命令变成事务。用 go-redis 演示批量写入的部分成功、结果核对、可安全重试的边界,以及如何用幂等键避免重试造成重复副作用。391 收藏
Redis Pipeline 能减少网络往返,却不会把一批命令变成事务。用 go-redis 演示批量写入的部分成功、结果核对、可安全重试的边界,以及如何用幂等键避免重试造成重复副作用。391 收藏 -
 把 os.DirFS 接到模板、压缩包或配置读取代码后,./config.yaml 这类看似正常的路径会被 io/fs.ValidPath 拒绝。本文用最小示例解释相对路径规则、filepath 与 path 的边界,以及迁移旧代码时如何保留用户输入语义。388 收藏
把 os.DirFS 接到模板、压缩包或配置读取代码后,./config.yaml 这类看似正常的路径会被 io/fs.ValidPath 拒绝。本文用最小示例解释相对路径规则、filepath 与 path 的边界,以及迁移旧代码时如何保留用户输入语义。388 收藏 -
科技周边 · 人工智能 | 1天前 | go · openai · AI接口 · Responses API · Go OpenAI Responses API background mode 异步轮询 大模型接口
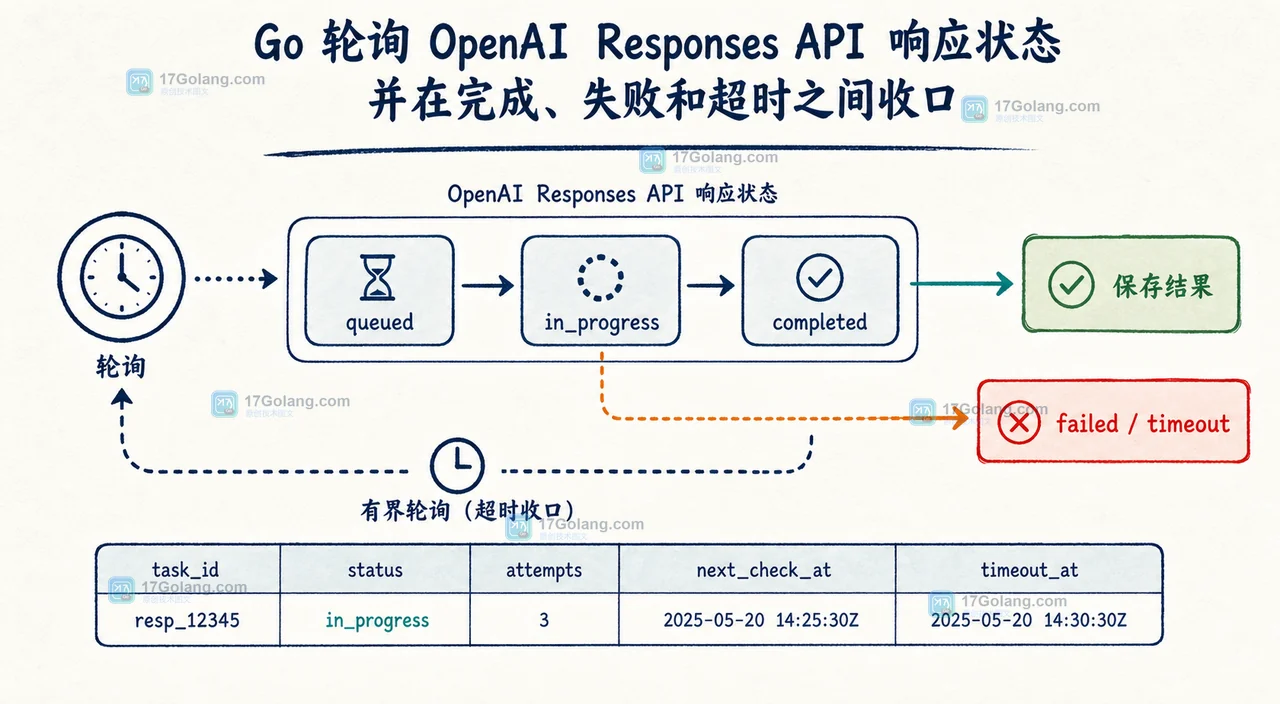 用 Go 接入 OpenAI Responses API 时,长推理或工具调用容易让同步 HTTP 请求撞上超时。本文从同步调用迁移到 background 模式,演示如何提交任务、按响应 ID 轮询、处理失败状态,并说明约 10 分钟保留窗口与 Zero Data Retention 的边界。388 收藏
用 Go 接入 OpenAI Responses API 时,长推理或工具调用容易让同步 HTTP 请求撞上超时。本文从同步调用迁移到 background 模式,演示如何提交任务、按响应 ID 轮询、处理失败状态,并说明约 10 分钟保留窗口与 Zero Data Retention 的边界。388 收藏 -
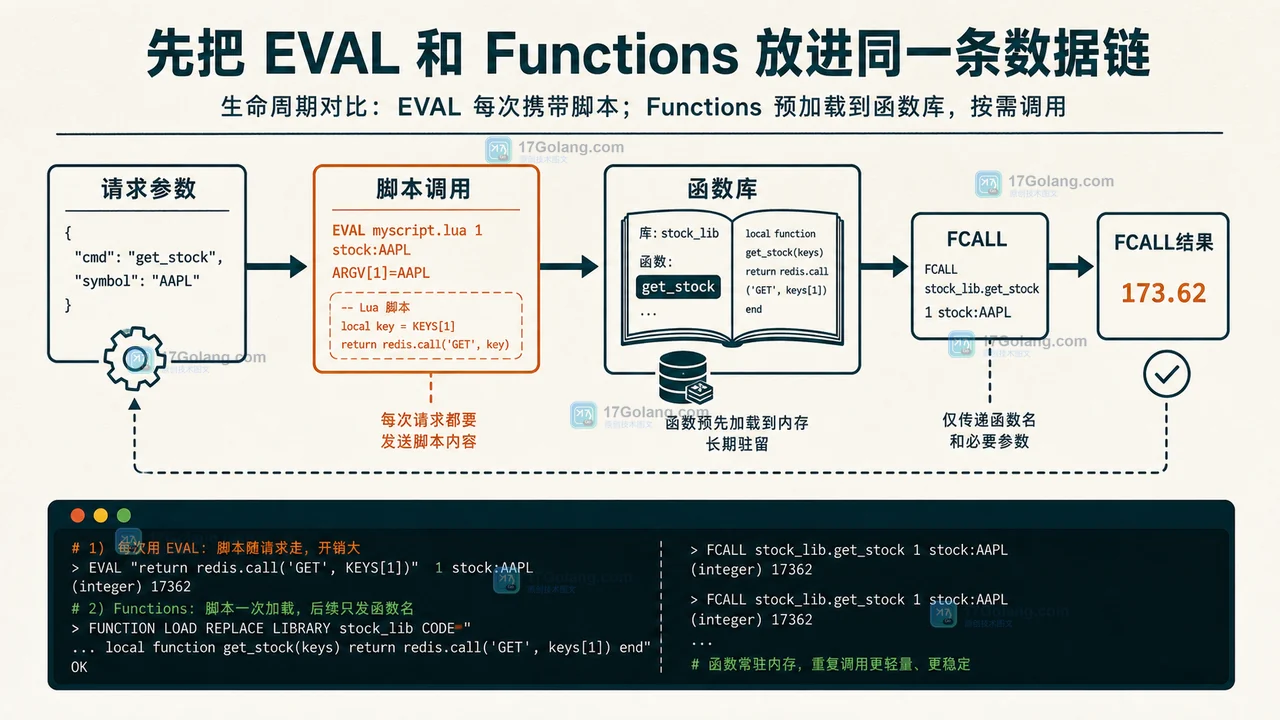 Redis Functions 从 7.0 开始为服务端逻辑提供了可加载、可复用的库模型,但它不是所有 Lua 脚本的直接替代。本文用请求级脚本调用、FUNCTION LOAD、FCALL 和集群键约束拆出迁移边界。386 收藏
Redis Functions 从 7.0 开始为服务端逻辑提供了可加载、可复用的库模型,但它不是所有 Lua 脚本的直接替代。本文用请求级脚本调用、FUNCTION LOAD、FCALL 和集群键约束拆出迁移边界。386 收藏 -
 接口能返回 200,不代表客户端真的能用。本文用 Go 标准库 httptest.NewServer 从零写一个小型接口烟雾测试器,逐步检查状态码、Content-Type、JSON 字段和超时,并给出适合 CI 的验收边界。385 收藏
接口能返回 200,不代表客户端真的能用。本文用 Go 标准库 httptest.NewServer 从零写一个小型接口烟雾测试器,逐步检查状态码、Content-Type、JSON 字段和超时,并给出适合 CI 的验收边界。385 收藏 -
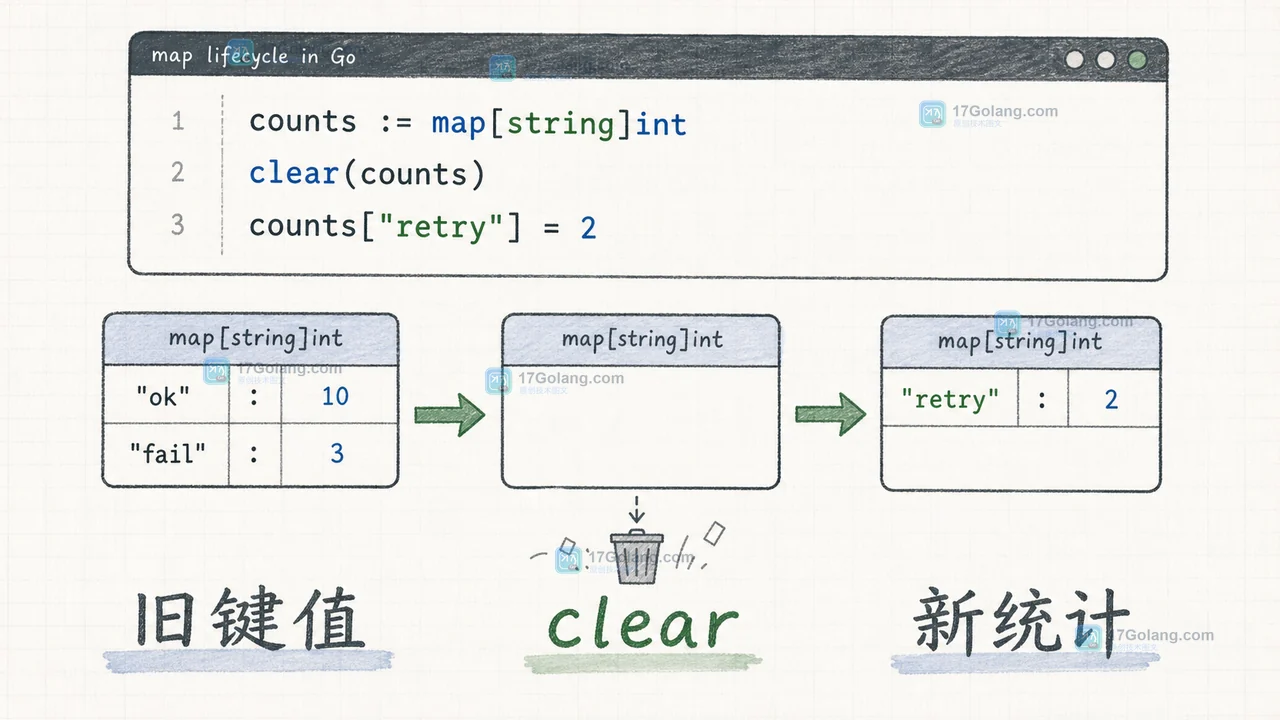 Go 1.21 引入的 clear 可以清空 map 或 slice,但两者的结果并不一样:map 保留对象并删除键值,slice 只把元素置为零值且长度容量不变。本文用缓存重建和批处理缓冲两个场景,说明 clear 的行为、引用影响、容量边界和可验证的复用写法。384 收藏
Go 1.21 引入的 clear 可以清空 map 或 slice,但两者的结果并不一样:map 保留对象并删除键值,slice 只把元素置为零值且长度容量不变。本文用缓存重建和批处理缓冲两个场景,说明 clear 的行为、引用影响、容量边界和可验证的复用写法。384 收藏 -
文章 · 前端 | 1天前 | 前端 · javascript · css · 浏览器API · document.startViewTransition CSS View Transitions 页面切换动画
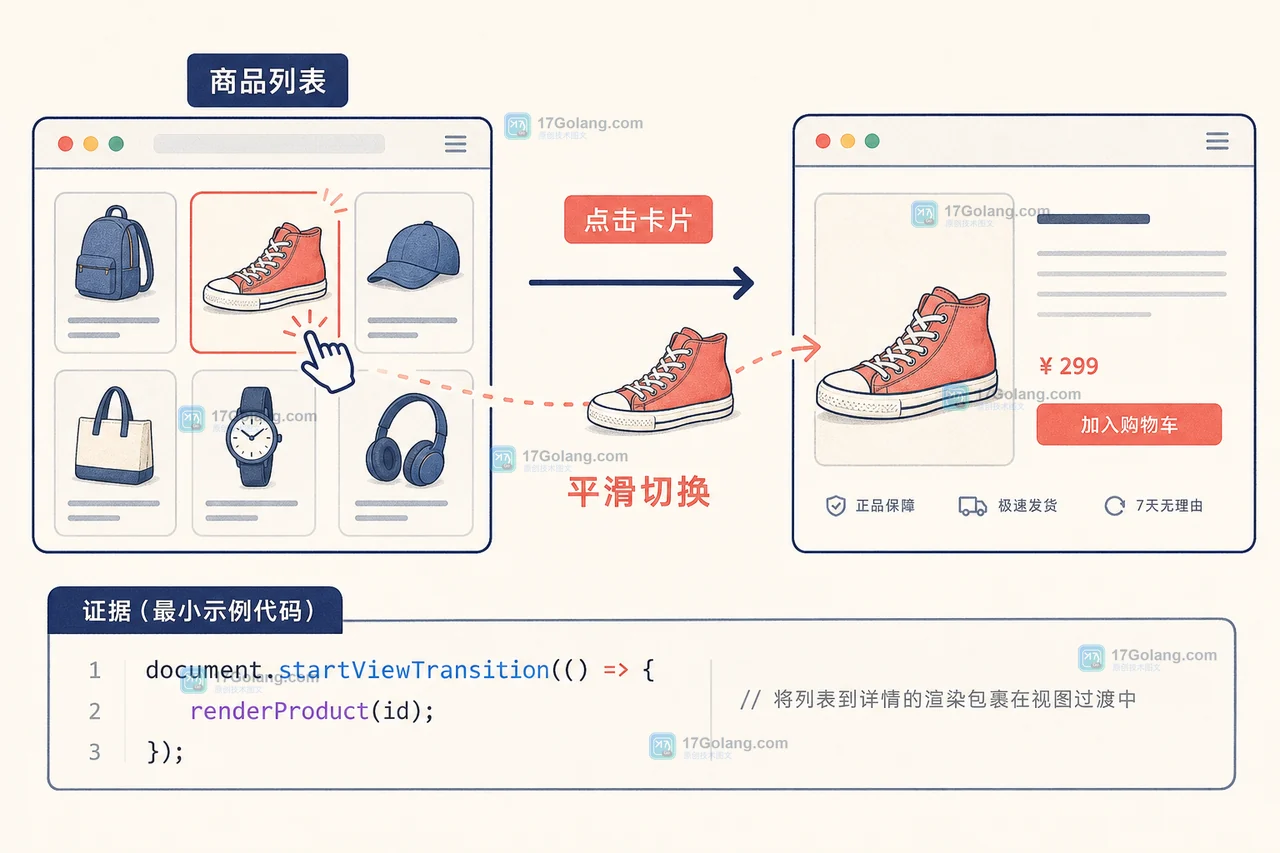 用一个无框架商品列表示例,讲清 CSS View Transitions API 的最小接入、元素命名、同文档切换、降级处理和浏览器兼容边界。375 收藏
用一个无框架商品列表示例,讲清 CSS View Transitions API 的最小接入、元素命名、同文档切换、降级处理和浏览器兼容边界。375 收藏