python教程技术文章
-
文章 · python教程 | 1天前 | 并发 · python · 故障排查 · asyncio · 任务取消 · Python asyncio.create_task Python 任务取消 asyncio CancelledError Python 异步任务收尾
 Python 异步接口超时后,后台任务仍在访问数据库或写文件,常见原因不是 cancel() 失效,而是任务没有被保存、取消没有被等待,或协程吞掉了 CancelledError。本文用一个可复现的 asyncio 故障现场拆开这条链路,并给出带超时、回收和日志核对的改法。490 收藏
Python 异步接口超时后,后台任务仍在访问数据库或写文件,常见原因不是 cancel() 失效,而是任务没有被保存、取消没有被等待,或协程吞掉了 CancelledError。本文用一个可复现的 asyncio 故障现场拆开这条链路,并给出带超时、回收和日志核对的改法。490 收藏 -
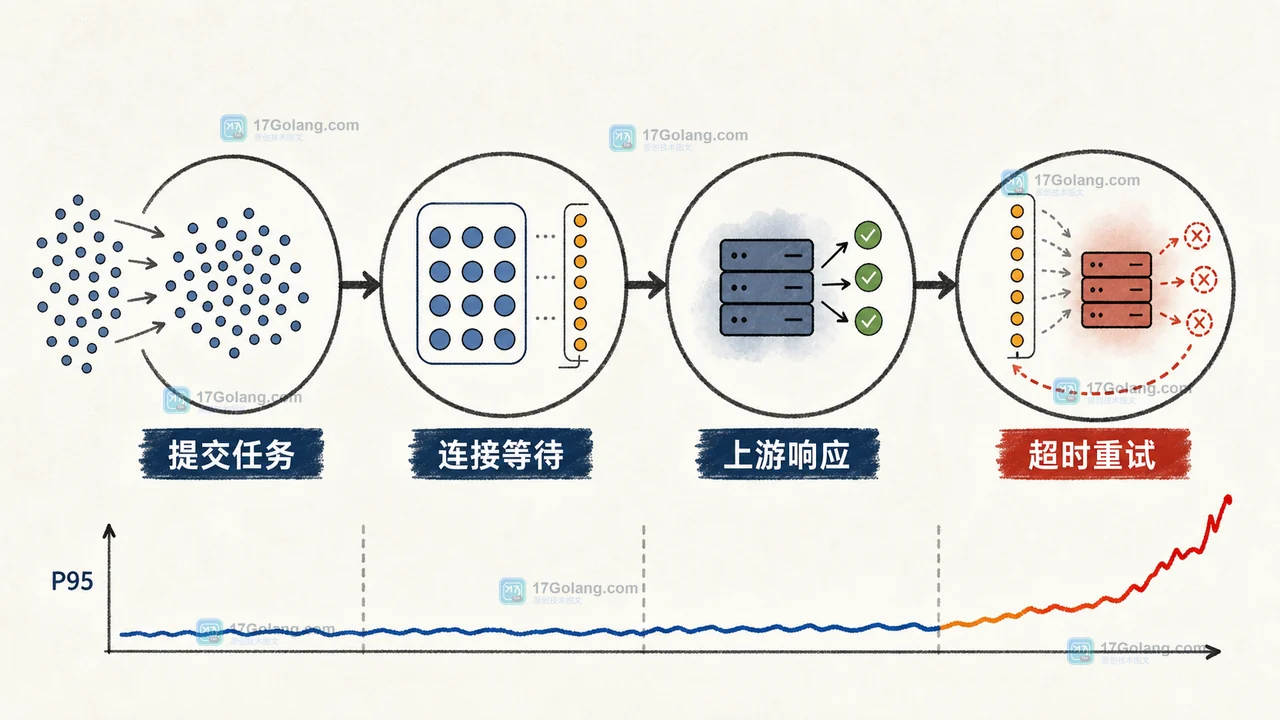 Python 批量调用外部接口时,任务越多不一定越快。本文从订单补数任务的耗时基线出发,用 httpx 连接池、asyncio.Semaphore 和超时预算控制请求数量,并通过压测结果说明配置边界与排查方法。196 收藏
Python 批量调用外部接口时,任务越多不一定越快。本文从订单补数任务的耗时基线出发,用 httpx 连接池、asyncio.Semaphore 和超时预算控制请求数量,并通过压测结果说明配置边界与排查方法。196 收藏