python教程技术文章
-
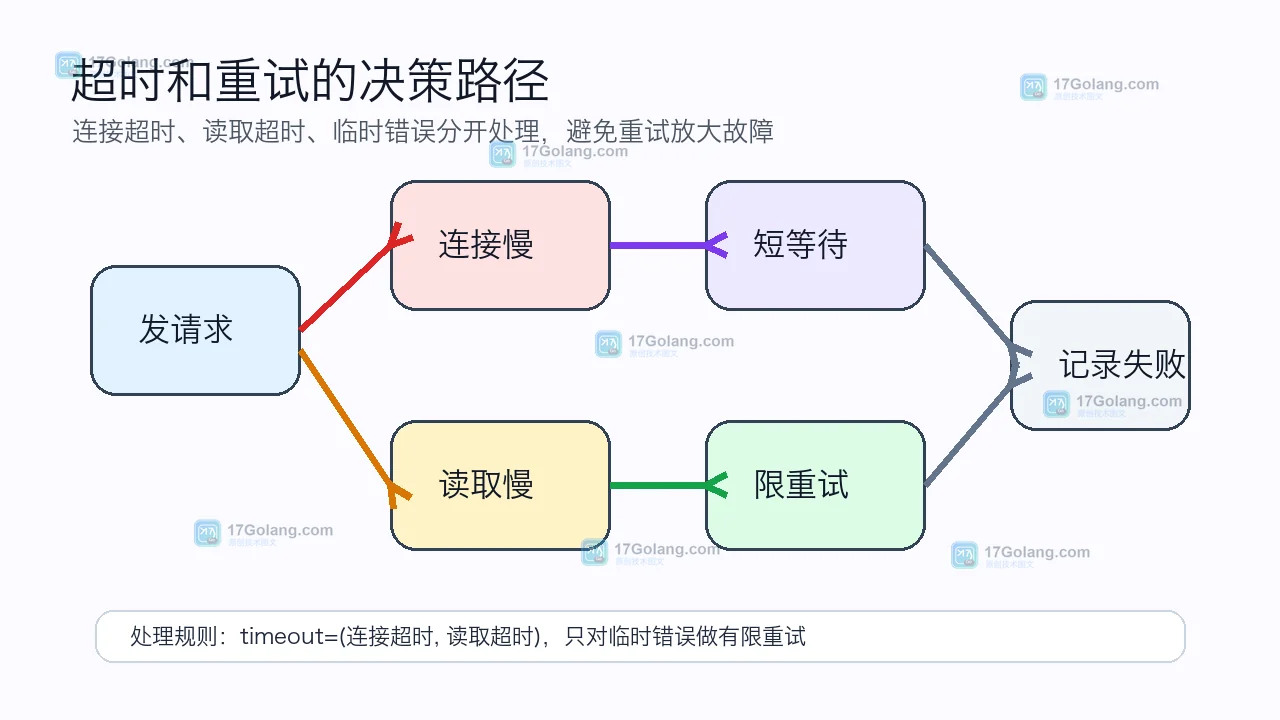 Python 脚本调用外部接口时,如果 requests 不设置 timeout,网络抖动会把 worker 长时间挂住。本文从队列堆积现象入手,讲清排查路径、超时参数、重试策略和上线前检查清单。435 收藏
Python 脚本调用外部接口时,如果 requests 不设置 timeout,网络抖动会把 worker 长时间挂住。本文从队列堆积现象入手,讲清排查路径、超时参数、重试策略和上线前检查清单。435 收藏 -
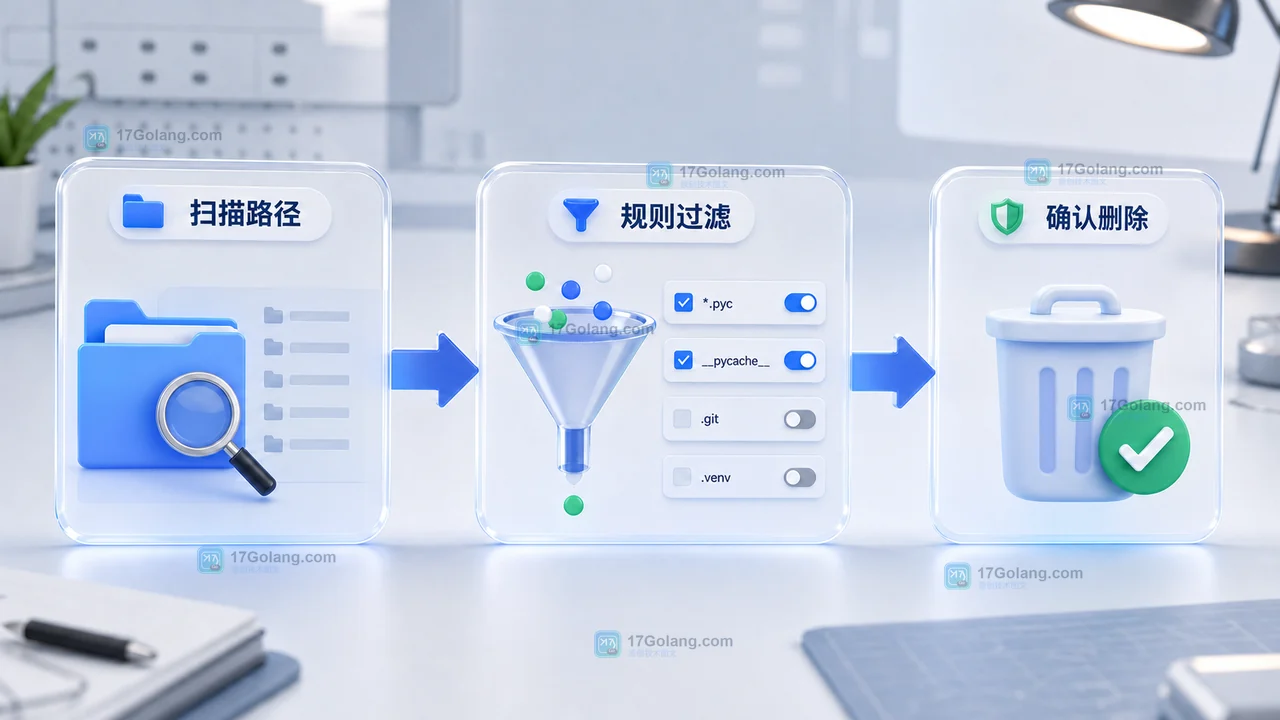 用 Python 做临时文件夹清理,重点不在递归删除本身,而在边界、阈值、白名单和试运行。本文从一个小工具项目出发,带你完成扫描、过滤、预览、删除确认和运行验收,适合处理 __pycache__、旧日志、构建缓存等可清理文件。428 收藏
用 Python 做临时文件夹清理,重点不在递归删除本身,而在边界、阈值、白名单和试运行。本文从一个小工具项目出发,带你完成扫描、过滤、预览、删除确认和运行验收,适合处理 __pycache__、旧日志、构建缓存等可清理文件。428 收藏