python教程技术文章
-
 Python 调用外部命令超时后,杀掉父进程并不代表子进程和孙进程都结束。本文用 start_new_session 创建独立进程组,再按 TERM、等待、KILL 的顺序清理,并补上超时、权限和回归检查。496 收藏
Python 调用外部命令超时后,杀掉父进程并不代表子进程和孙进程都结束。本文用 start_new_session 创建独立进程组,再按 TERM、等待、KILL 的顺序清理,并补上超时、权限和回归检查。496 收藏 -
 批量导出不能只生成一个 CSV 文件。本文用 Python 标准库实现任务文件夹、状态文件、原子写入、结果查询和过期清理,让下载结果可追踪且不会长期堆积。495 收藏
批量导出不能只生成一个 CSV 文件。本文用 Python 标准库实现任务文件夹、状态文件、原子写入、结果查询和过期清理,让下载结果可追踪且不会长期堆积。495 收藏 -
文章 · python教程 | 4天前 | 并发 · python · 故障排查 · asyncio · 任务取消 · Python asyncio.create_task Python 任务取消 asyncio CancelledError Python 异步任务收尾
 Python 异步接口超时后,后台任务仍在访问数据库或写文件,常见原因不是 cancel() 失效,而是任务没有被保存、取消没有被等待,或协程吞掉了 CancelledError。本文用一个可复现的 asyncio 故障现场拆开这条链路,并给出带超时、回收和日志核对的改法。490 收藏
Python 异步接口超时后,后台任务仍在访问数据库或写文件,常见原因不是 cancel() 失效,而是任务没有被保存、取消没有被等待,或协程吞掉了 CancelledError。本文用一个可复现的 asyncio 故障现场拆开这条链路,并给出带超时、回收和日志核对的改法。490 收藏 -
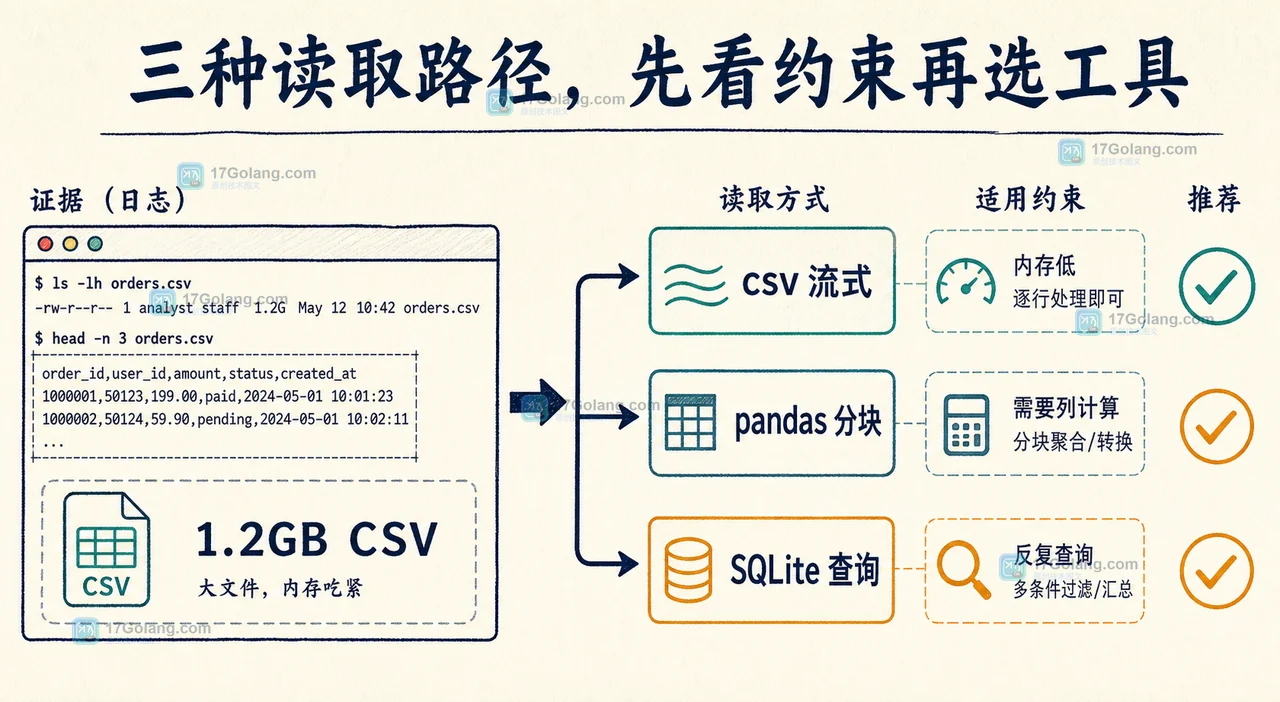 面对百万行 CSV,不要一上来就把文件整体读进内存。本文用同一份订单导出数据比较 csv 流式读取、pandas chunksize 和 SQLite 分批导入,给出按内存、清洗复杂度和后续查询需求选方案的可运行边界。330 收藏
面对百万行 CSV,不要一上来就把文件整体读进内存。本文用同一份订单导出数据比较 csv 流式读取、pandas chunksize 和 SQLite 分批导入,给出按内存、清洗复杂度和后续查询需求选方案的可运行边界。330 收藏 -
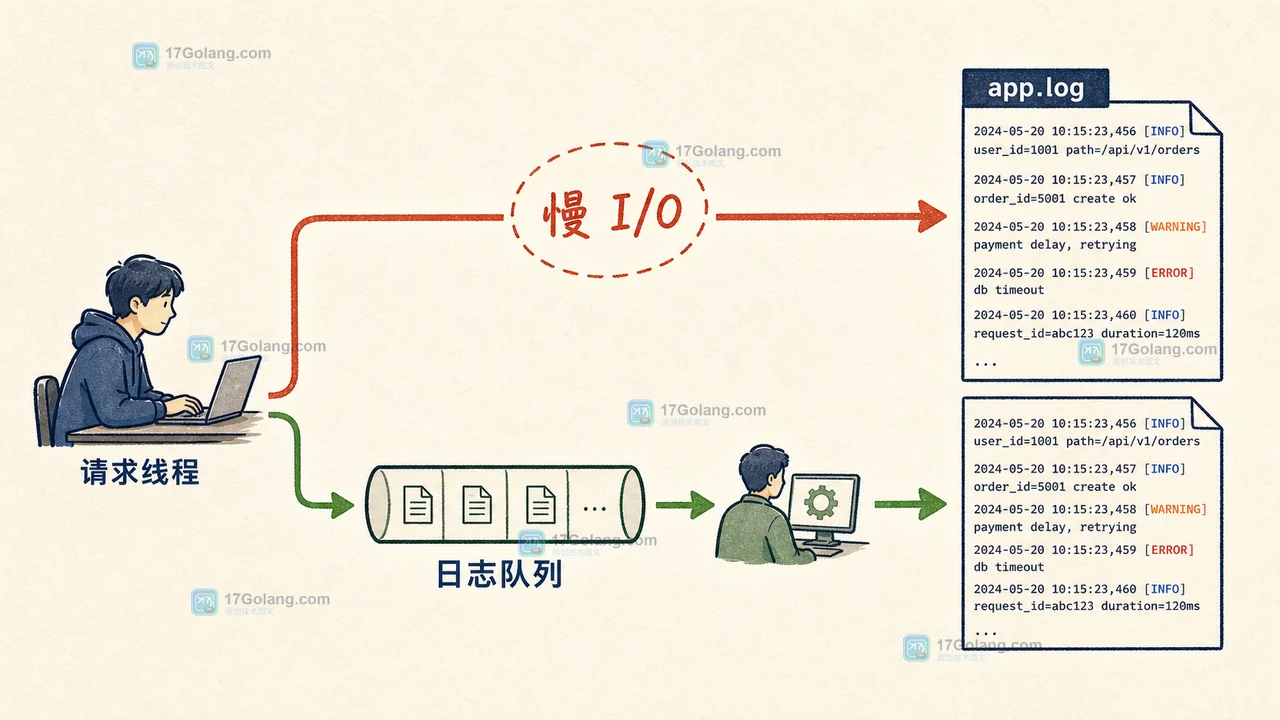 Python 服务在并发升高后,日志格式化和磁盘写入容易挤占请求线程。本文用 QueueHandler 与 QueueListener 拆开日志生产和落盘,比较直接写文件、队列日志两种方案,给出可运行示例、压测口径与优雅退出处理。268 收藏
Python 服务在并发升高后,日志格式化和磁盘写入容易挤占请求线程。本文用 QueueHandler 与 QueueListener 拆开日志生产和落盘,比较直接写文件、队列日志两种方案,给出可运行示例、压测口径与优雅退出处理。268 收藏 -
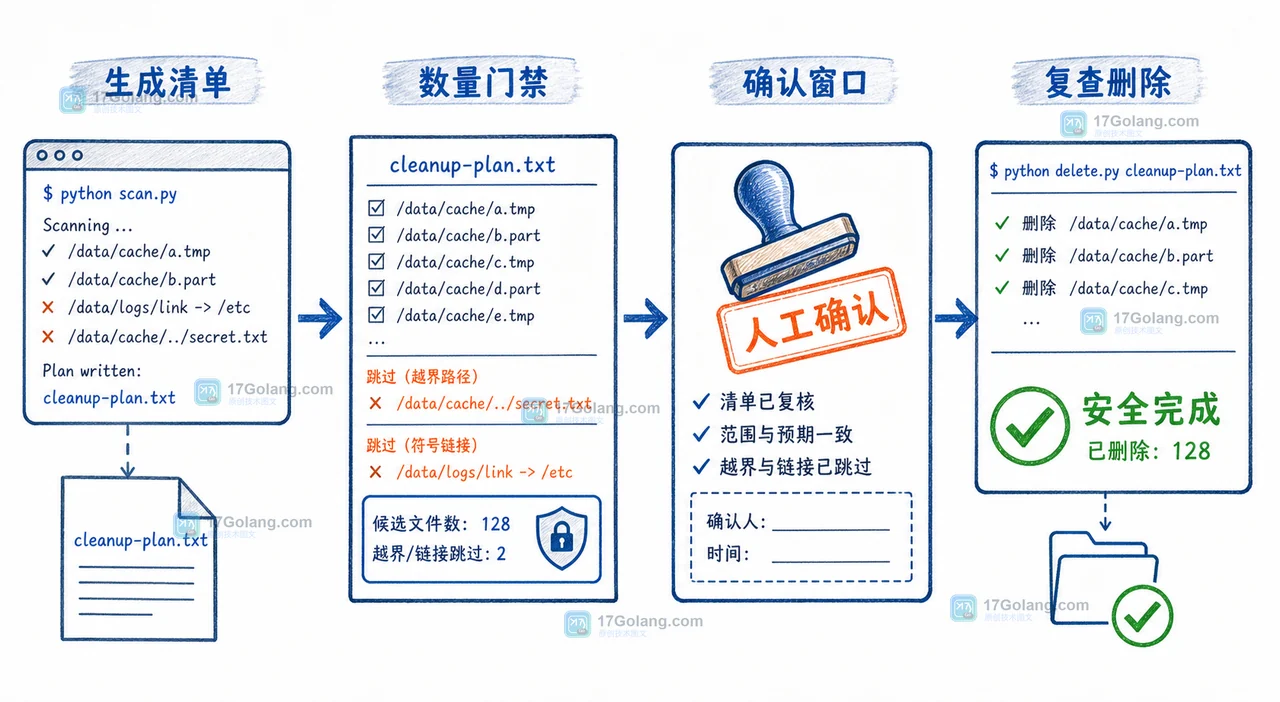 临时目录清理最容易出问题的地方,不是调用 unlink,而是筛选条件太宽、相对路径越界和删错文件后无法复盘。用 pathlib 统一解析路径,按后缀和 mtime 过滤,先写入待删清单再处理,就能把一次性脚本变成可检查、可回退的清理流程。219 收藏
临时目录清理最容易出问题的地方,不是调用 unlink,而是筛选条件太宽、相对路径越界和删错文件后无法复盘。用 pathlib 统一解析路径,按后缀和 mtime 过滤,先写入待删清单再处理,就能把一次性脚本变成可检查、可回退的清理流程。219 收藏 -
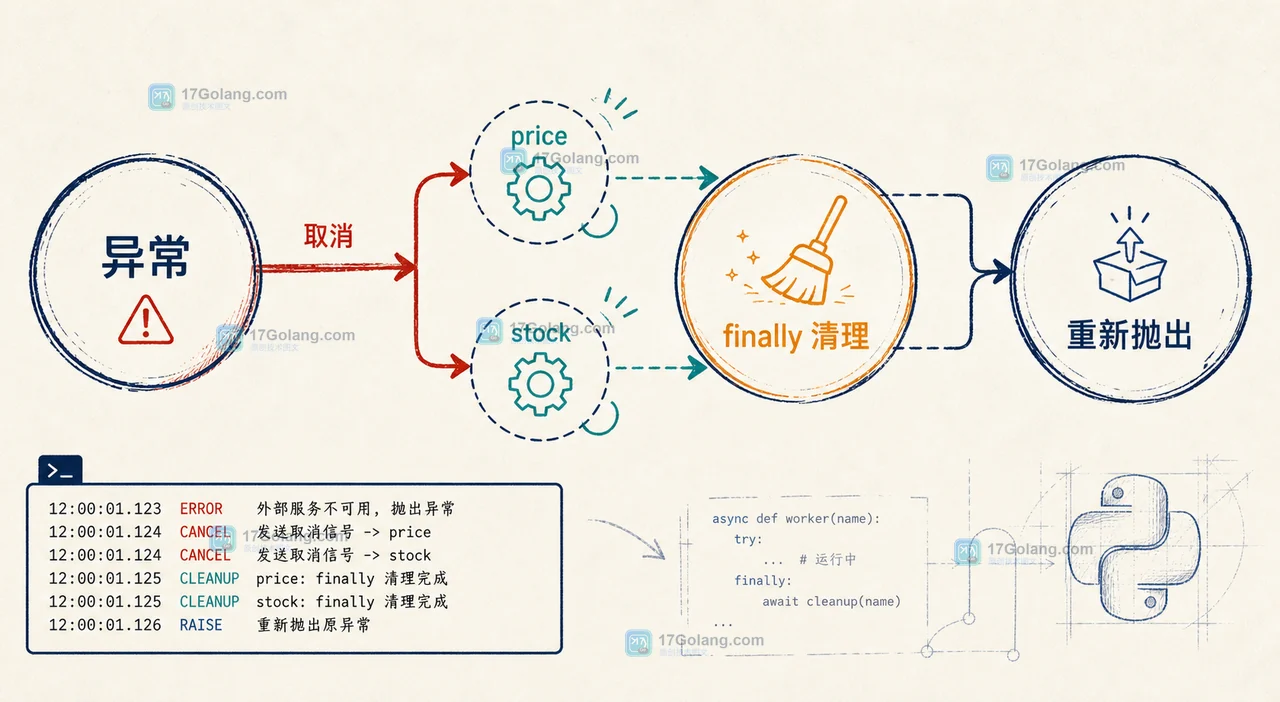 asyncio.gather 遇到子任务异常时,默认只把第一个异常交给调用方,其他任务可能仍在运行。本文用可复现实验说明 return_exceptions、Task.cancel 和 finally 清理之间的边界。210 收藏
asyncio.gather 遇到子任务异常时,默认只把第一个异常交给调用方,其他任务可能仍在运行。本文用可复现实验说明 return_exceptions、Task.cancel 和 finally 清理之间的边界。210 收藏 -
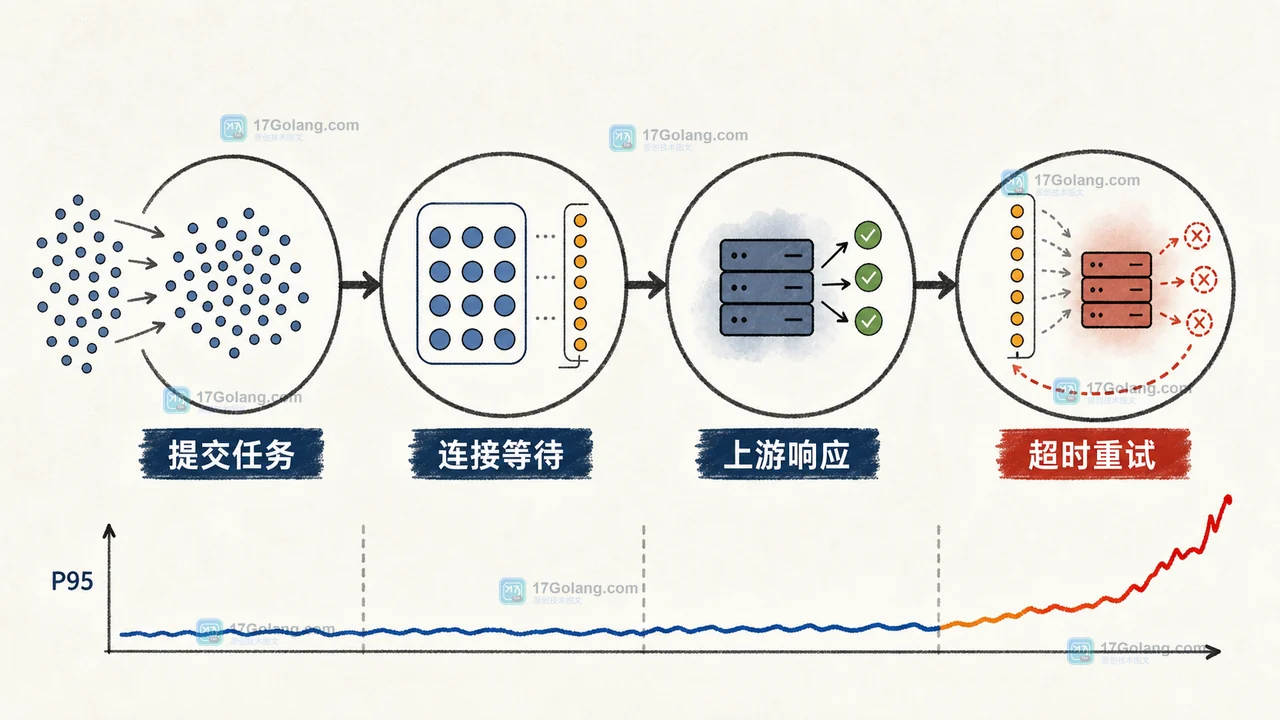 Python 批量调用外部接口时,任务越多不一定越快。本文从订单补数任务的耗时基线出发,用 httpx 连接池、asyncio.Semaphore 和超时预算控制请求数量,并通过压测结果说明配置边界与排查方法。196 收藏
Python 批量调用外部接口时,任务越多不一定越快。本文从订单补数任务的耗时基线出发,用 httpx 连接池、asyncio.Semaphore 和超时预算控制请求数量,并通过压测结果说明配置边界与排查方法。196 收藏