python教程技术文章
-
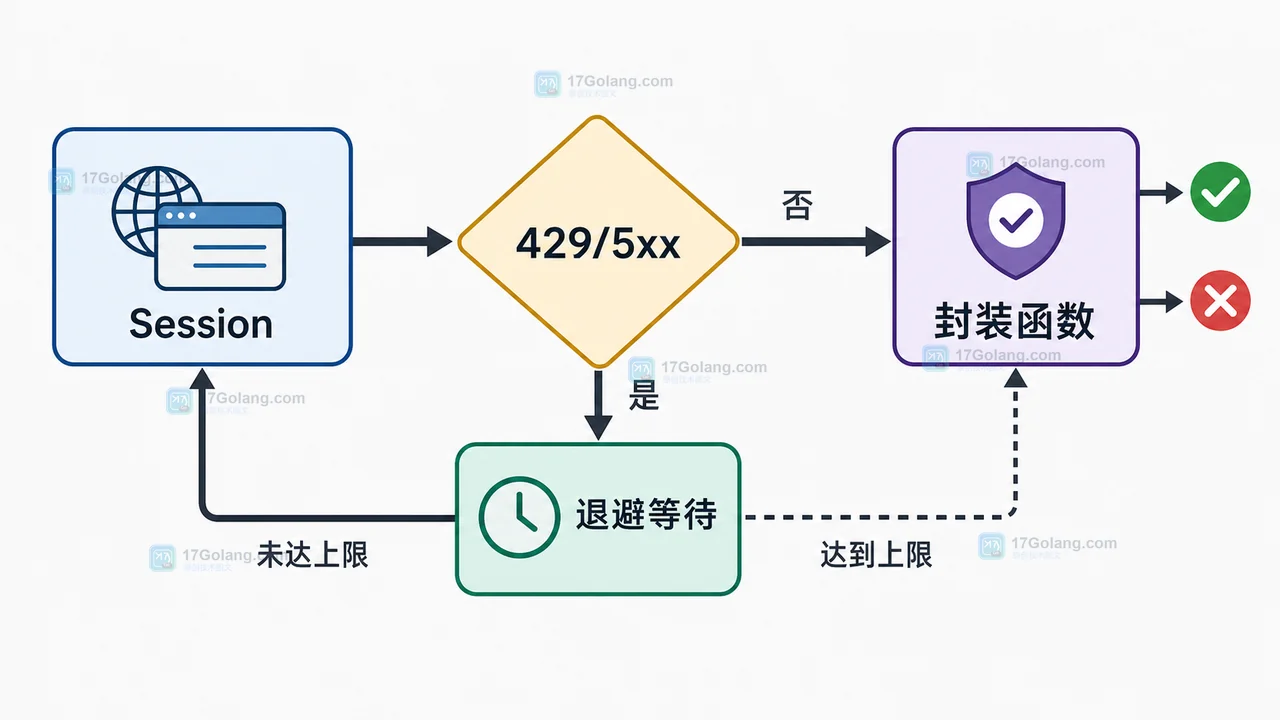 用一个最小 requests 配方解决 HTTP 请求卡住、慢接口无响应和偶发 5xx 问题:分开设置连接/读取超时,用 Session 统一重试,再封装业务请求函数。478 收藏
用一个最小 requests 配方解决 HTTP 请求卡住、慢接口无响应和偶发 5xx 问题:分开设置连接/读取超时,用 Session 统一重试,再封装业务请求函数。478 收藏 -
 Python 批量处理文件时,进度输出不能只追求好看:交互终端需要实时进度,CI 和重定向日志需要稳定文本,Ctrl+C 则要留下可恢复的检查点。本文用标准库实现 TTY 检测、节流输出、SIGINT 安全取消和断点续跑。473 收藏
Python 批量处理文件时,进度输出不能只追求好看:交互终端需要实时进度,CI 和重定向日志需要稳定文本,Ctrl+C 则要留下可恢复的检查点。本文用标准库实现 TTY 检测、节流输出、SIGINT 安全取消和断点续跑。473 收藏 -
文章 · python教程 | 22小时前 | 时间处理 · python · zoneinfo · 后端开发 · UTC · Python DateTime UTC 夏令时 zoneinfo fold
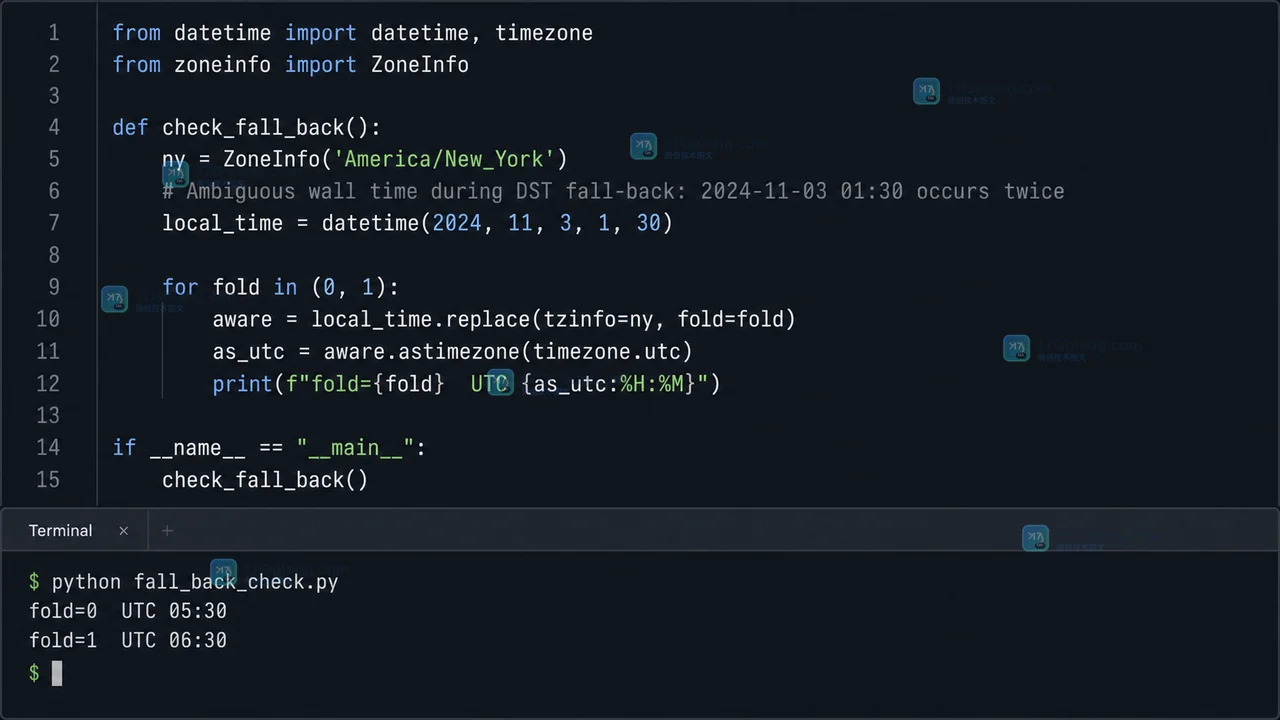 预约、提醒和活动排期里,用户输入的本地时间不能直接当 UTC 保存。本文用一个小型预约转换器说明 Python zoneinfo 的最小用法:保留时区键、把带时区时间转成 UTC,并在夏令时回拨造成的重复时间里明确记录 fold 选择。469 收藏
预约、提醒和活动排期里,用户输入的本地时间不能直接当 UTC 保存。本文用一个小型预约转换器说明 Python zoneinfo 的最小用法:保留时区键、把带时区时间转成 UTC,并在夏令时回拨造成的重复时间里明确记录 fold 选择。469 收藏 -
文章 · python教程 | 1天前 | 命令行 · 异常处理 · Input · Python教程 · ValueError · 命令行交互 ValueError Python input int 输入校验 EOFError
 Python 的 input 总会返回字符串,直接交给 int 转换时,空值、字母和终端输入结束都会让交互变得难用。文章从用户实际输入出发,给出循环校验、范围限制、退出命令和 EOFError 边界的最小实现,并附上核对清单。458 收藏
Python 的 input 总会返回字符串,直接交给 int 转换时,空值、字母和终端输入结束都会让交互变得难用。文章从用户实际输入出发,给出循环校验、范围限制、退出命令和 EOFError 边界的最小实现,并附上核对清单。458 收藏 -
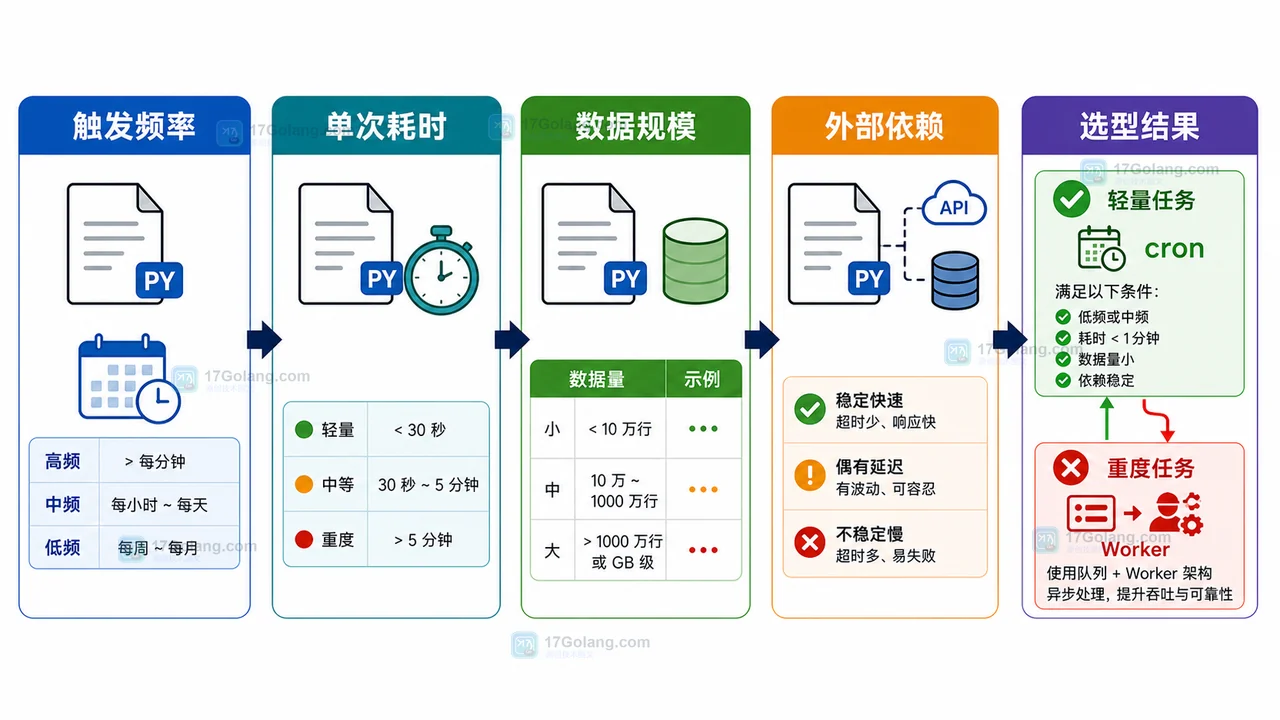 围绕 Python 定时任务上云,按负载、约束、方案对比、推荐架构、风险点和落地清单,比较单机 cron、容器任务、队列 Worker 和函数运行方案。435 收藏
围绕 Python 定时任务上云,按负载、约束、方案对比、推荐架构、风险点和落地清单,比较单机 cron、容器任务、队列 Worker 和函数运行方案。435 收藏 -
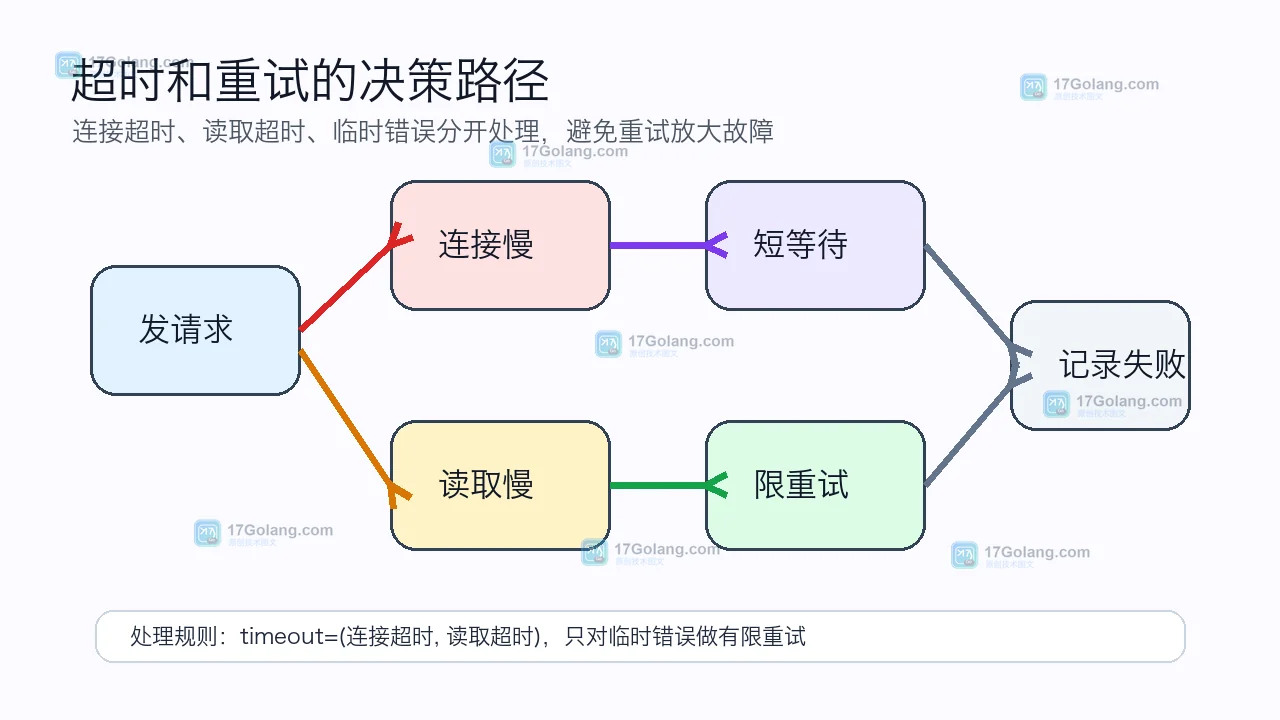 Python 脚本调用外部接口时,如果 requests 不设置 timeout,网络抖动会把 worker 长时间挂住。本文从队列堆积现象入手,讲清排查路径、超时参数、重试策略和上线前检查清单。435 收藏
Python 脚本调用外部接口时,如果 requests 不设置 timeout,网络抖动会把 worker 长时间挂住。本文从队列堆积现象入手,讲清排查路径、超时参数、重试策略和上线前检查清单。435 收藏 -
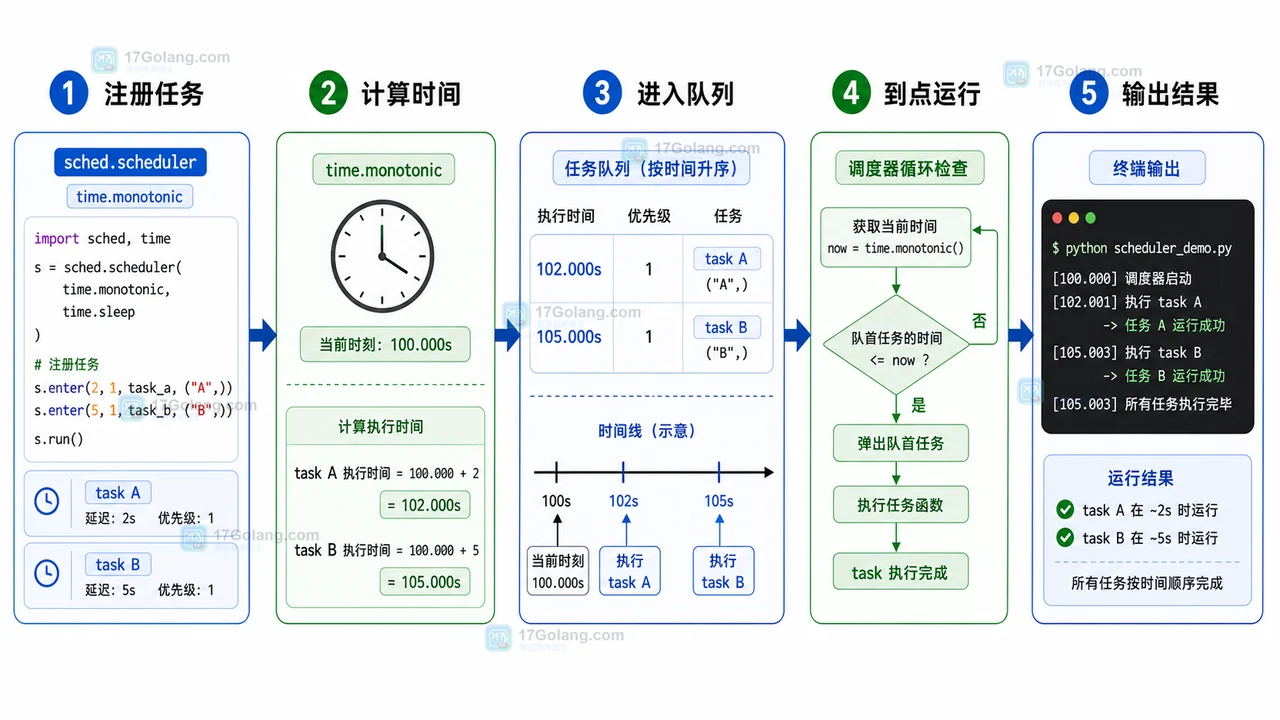 用 Python 标准库 sched 做一个本地轻量定时任务实验,覆盖任务注册、轮询运行、周期任务、失败重试、运行检查和清理边界,适合小脚本和本地自动化场景。432 收藏
用 Python 标准库 sched 做一个本地轻量定时任务实验,覆盖任务注册、轮询运行、周期任务、失败重试、运行检查和清理边界,适合小脚本和本地自动化场景。432 收藏 -
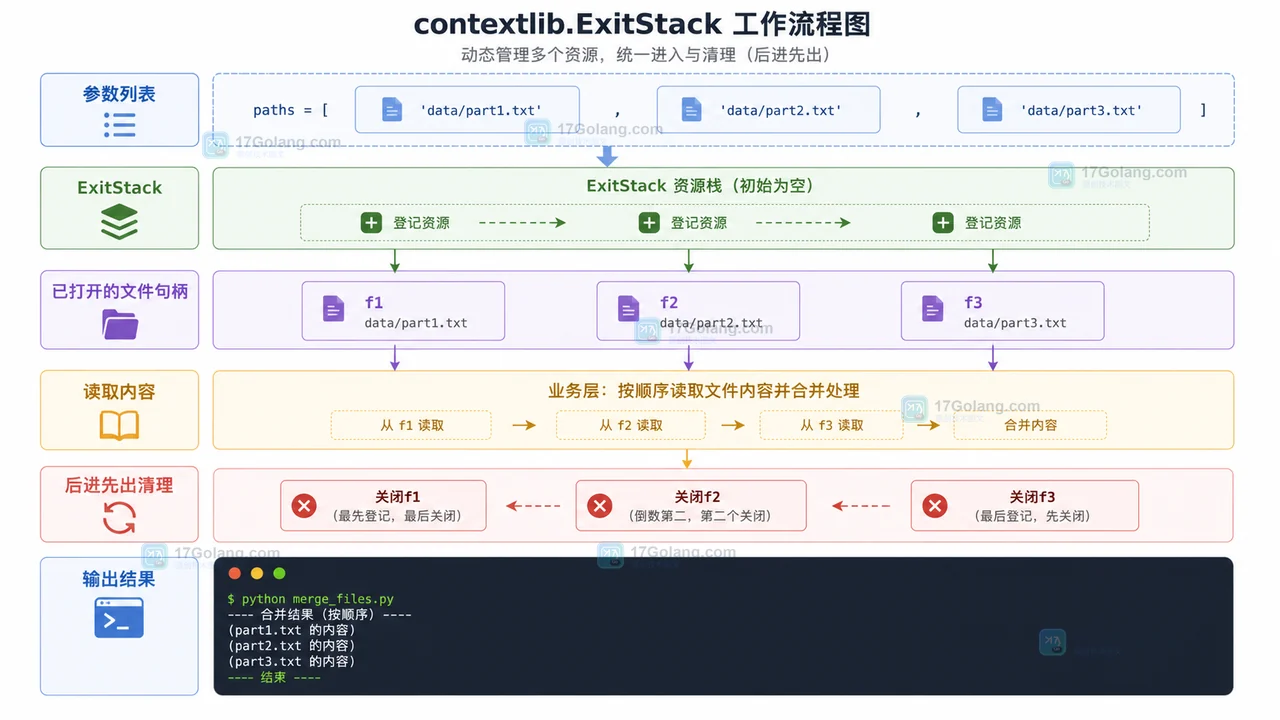 用 Python 标准库 contextlib 写一套资源清理小配方,从自定义上下文管理器、suppress 到 ExitStack,解决文件、临时目录和多资源关闭顺序问题。429 收藏
用 Python 标准库 contextlib 写一套资源清理小配方,从自定义上下文管理器、suppress 到 ExitStack,解决文件、临时目录和多资源关闭顺序问题。429 收藏 -
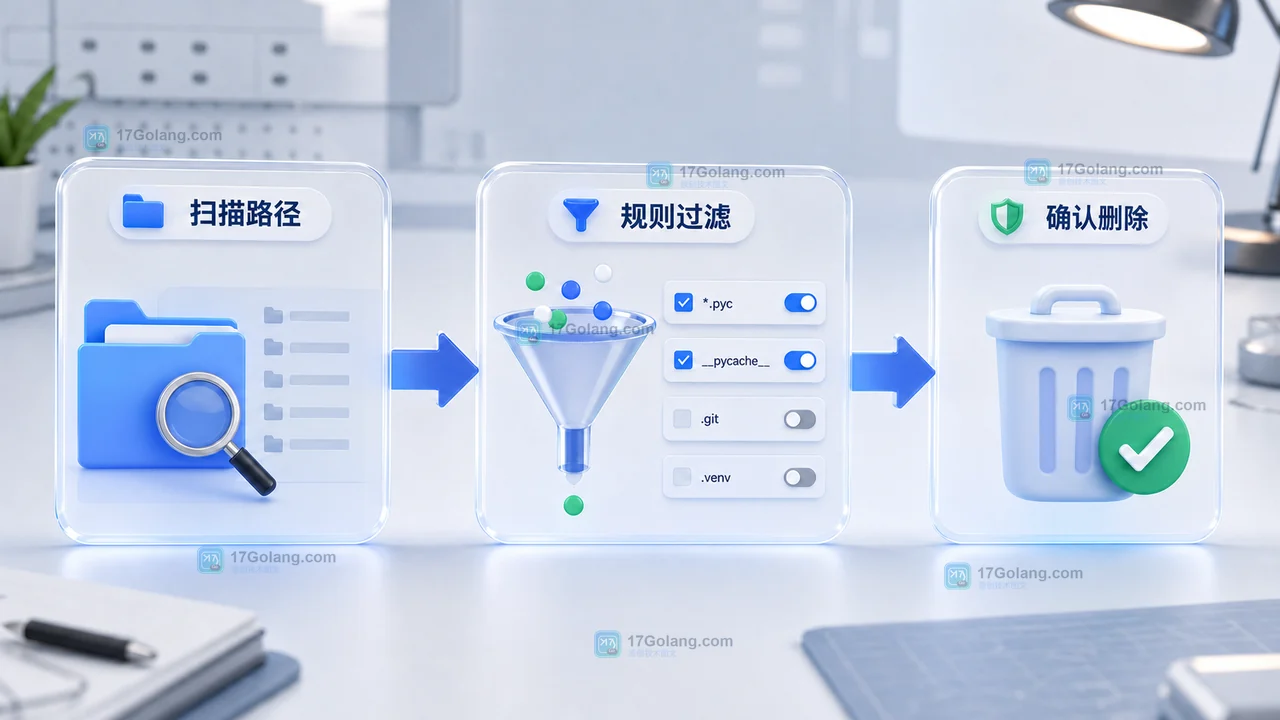 用 Python 做临时文件夹清理,重点不在递归删除本身,而在边界、阈值、白名单和试运行。本文从一个小工具项目出发,带你完成扫描、过滤、预览、删除确认和运行验收,适合处理 __pycache__、旧日志、构建缓存等可清理文件。428 收藏
用 Python 做临时文件夹清理,重点不在递归删除本身,而在边界、阈值、白名单和试运行。本文从一个小工具项目出发,带你完成扫描、过滤、预览、删除确认和运行验收,适合处理 __pycache__、旧日志、构建缓存等可清理文件。428 收藏 -
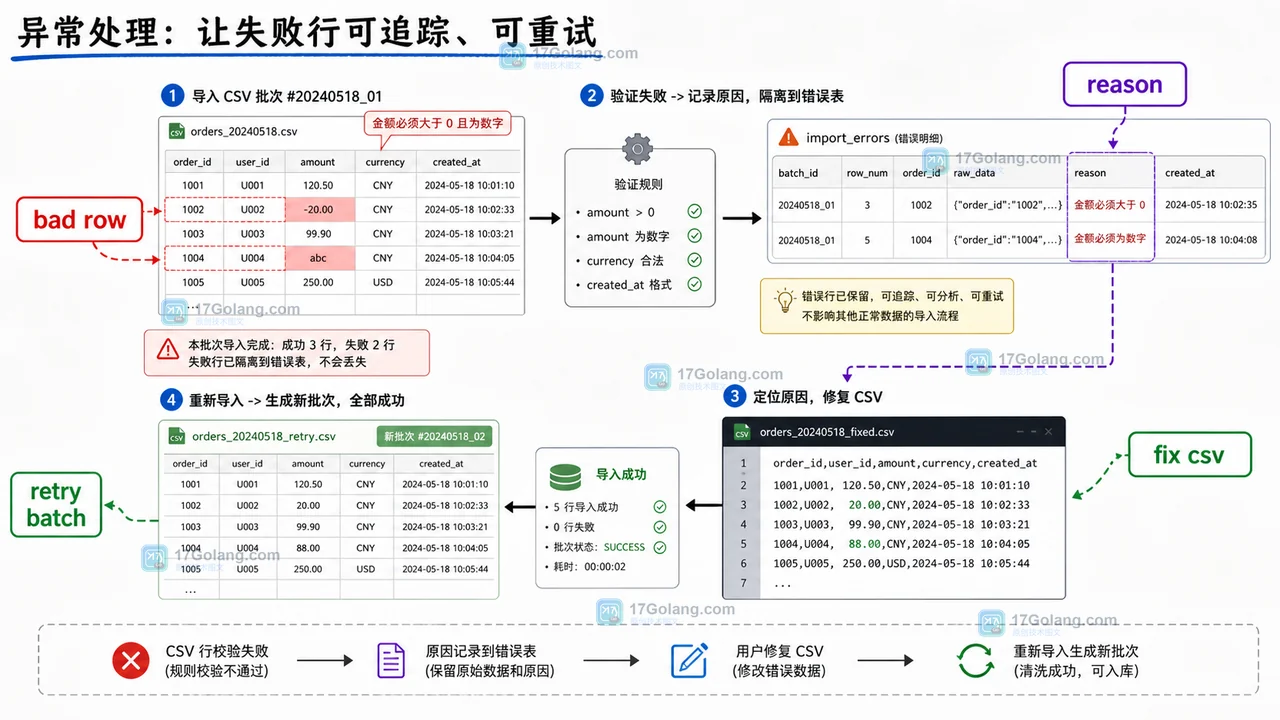 用 Python 标准库搭建 CSV 导入流水线,按原始文件、字段校验、SQLite 存储、查询路径、错误行处理和临时文件清理讲清数据生命周期。354 收藏
用 Python 标准库搭建 CSV 导入流水线,按原始文件、字段校验、SQLite 存储、查询路径、错误行处理和临时文件清理讲清数据生命周期。354 收藏 -
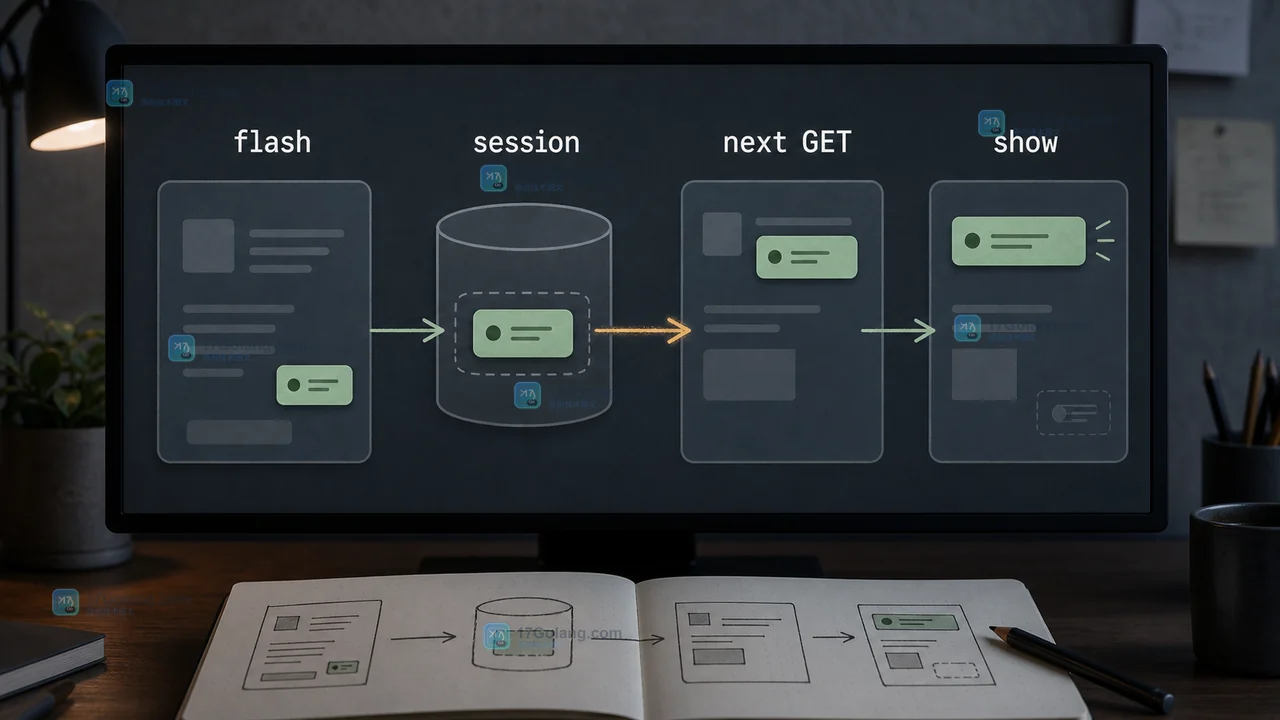 Flask 表单保存后直接渲染页面,刷新浏览器往往会再次提交 POST。用 Post/Redirect/Get 把保存动作和展示页面拆开,再配合 flash 把一次性反馈交给下一次 GET,能让刷新、回退和提示消息各自落在正确边界。343 收藏
Flask 表单保存后直接渲染页面,刷新浏览器往往会再次提交 POST。用 Post/Redirect/Get 把保存动作和展示页面拆开,再配合 flash 把一次性反馈交给下一次 GET,能让刷新、回退和提示消息各自落在正确边界。343 收藏 -
文章 · python教程 | 2星期前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig
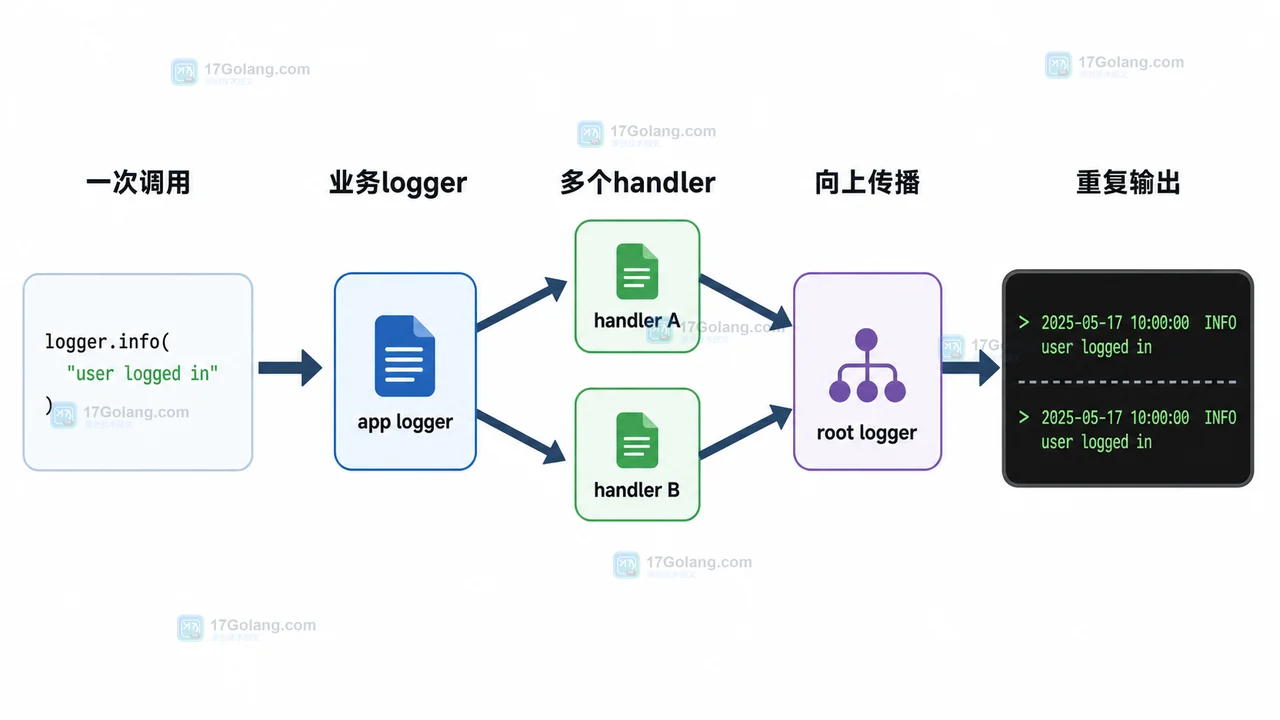 从 Python logging 一条日志重复输出的现象出发,逐步检查 handler 数量、basicConfig 位置和 propagate 传播链,给出可复现代码和稳定修复方式。324 收藏
从 Python logging 一条日志重复输出的现象出发,逐步检查 handler 数量、basicConfig 位置和 propagate 传播链,给出可复现代码和稳定修复方式。324 收藏 -
文章 · python教程 | 3星期前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理
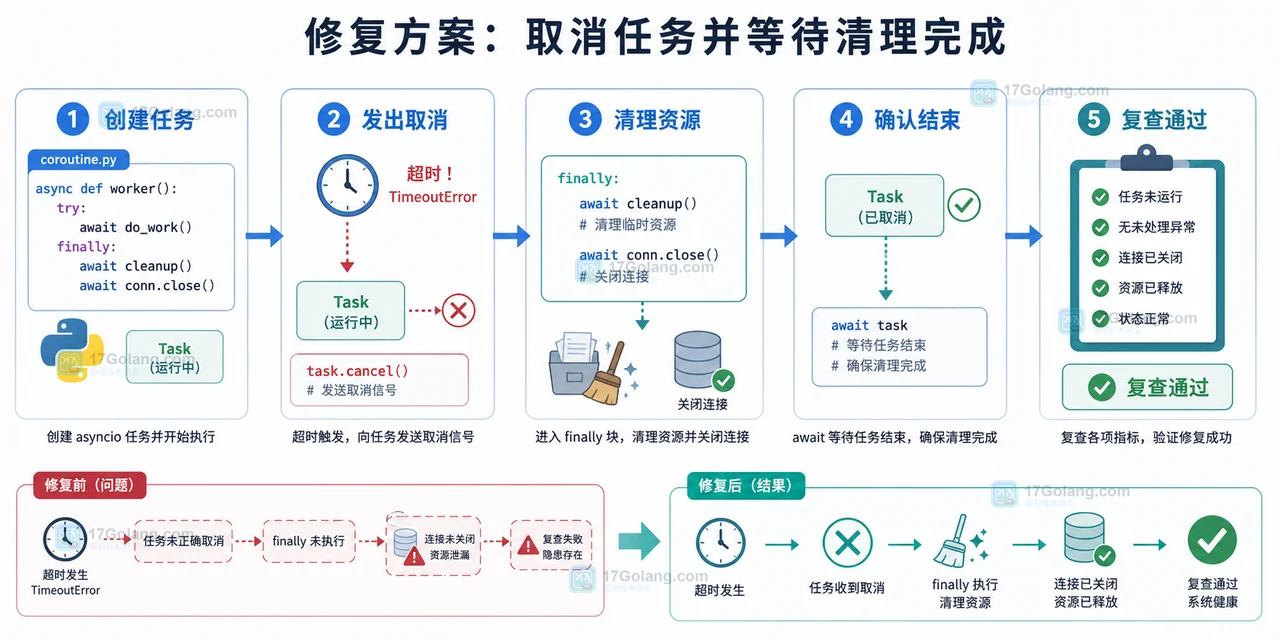 本文从一个 asyncio 超时后后台任务仍在继续的现象出发,排查 wait_for、shield、取消信号和资源清理的关系,并给出可复查的超时取消写法。320 收藏
本文从一个 asyncio 超时后后台任务仍在继续的现象出发,排查 wait_for、shield、取消信号和资源清理的关系,并给出可复查的超时取消写法。320 收藏 -
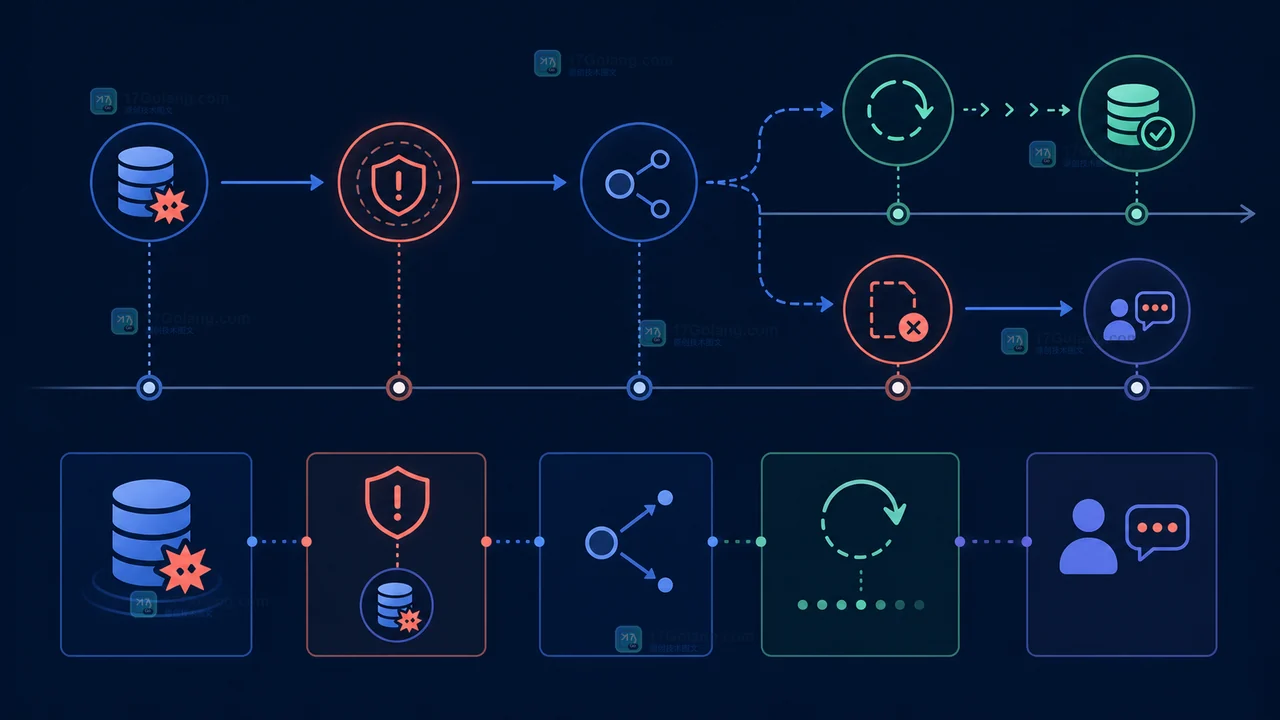 Python API 的返回值和异常是调用方契约的一部分。本文从预期不存在、无效输入、依赖失败和异常链保留四类场景出发,说明 None、内置异常和自定义异常该怎样取舍。313 收藏
Python API 的返回值和异常是调用方契约的一部分。本文从预期不存在、无效输入、依赖失败和异常链保留四类场景出发,说明 None、内置异常和自定义异常该怎样取舍。313 收藏 -
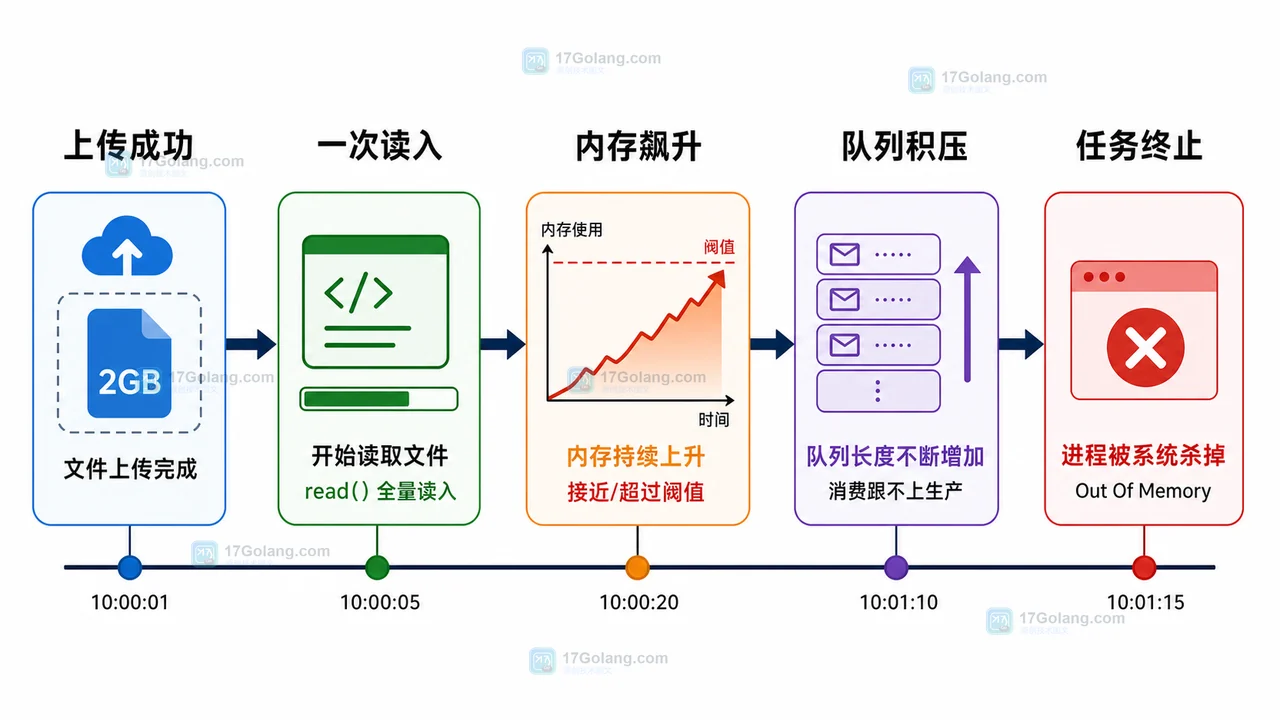 复盘一次 Python 大文件导入导致内存飙升的问题,按影响面、时间线、触发条件、根因、修复动作和防复发清单讲清 read() 一次读入与分块迭代的差异。196 收藏
复盘一次 Python 大文件导入导致内存飙升的问题,按影响面、时间线、触发条件、根因、修复动作和防复发清单讲清 read() 一次读入与分块迭代的差异。196 收藏