python教程技术文章
-
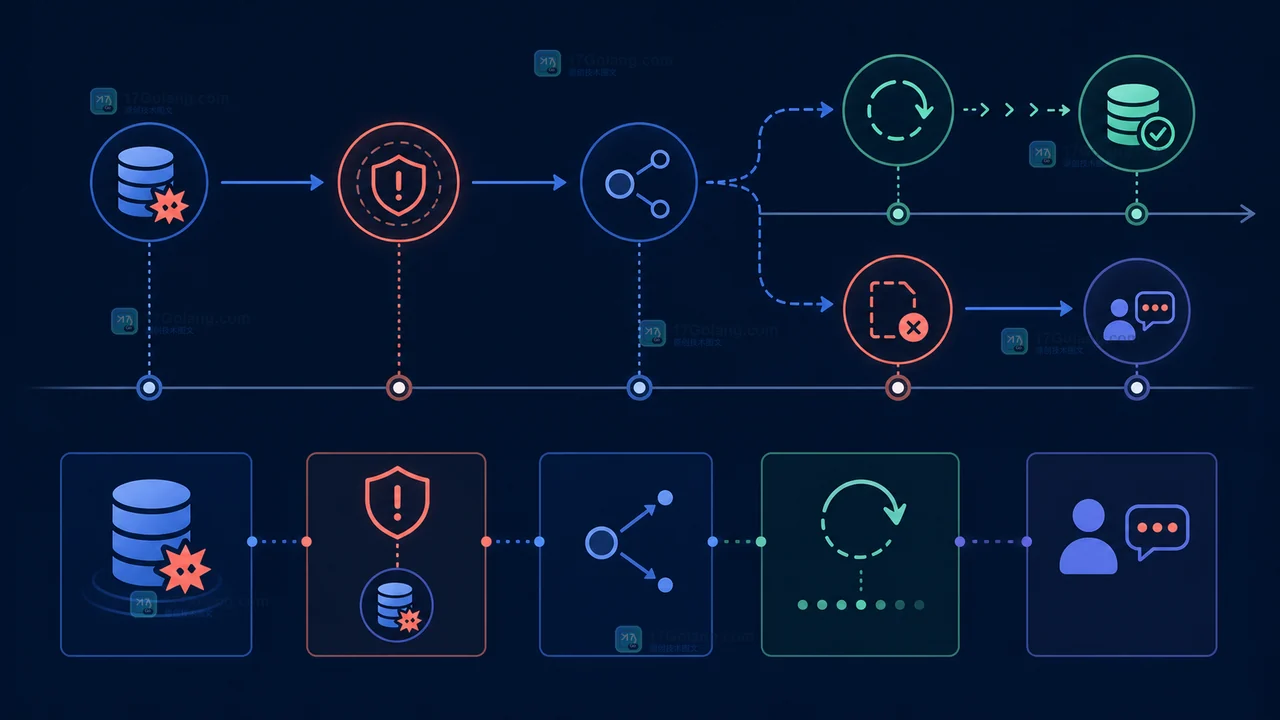 Python API 的返回值和异常是调用方契约的一部分。本文从预期不存在、无效输入、依赖失败和异常链保留四类场景出发,说明 None、内置异常和自定义异常该怎样取舍。313 收藏
Python API 的返回值和异常是调用方契约的一部分。本文从预期不存在、无效输入、依赖失败和异常链保留四类场景出发,说明 None、内置异常和自定义异常该怎样取舍。313 收藏 -
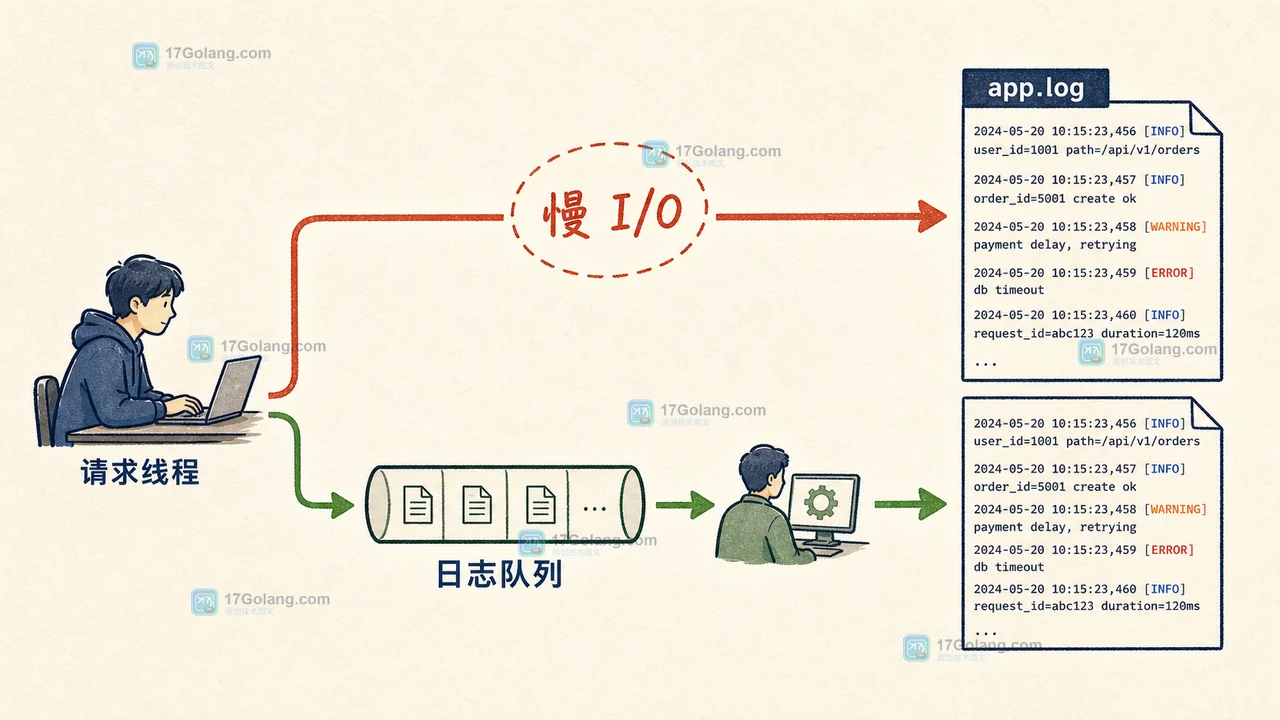 Python 服务在并发升高后,日志格式化和磁盘写入容易挤占请求线程。本文用 QueueHandler 与 QueueListener 拆开日志生产和落盘,比较直接写文件、队列日志两种方案,给出可运行示例、压测口径与优雅退出处理。268 收藏
Python 服务在并发升高后,日志格式化和磁盘写入容易挤占请求线程。本文用 QueueHandler 与 QueueListener 拆开日志生产和落盘,比较直接写文件、队列日志两种方案,给出可运行示例、压测口径与优雅退出处理。268 收藏 -
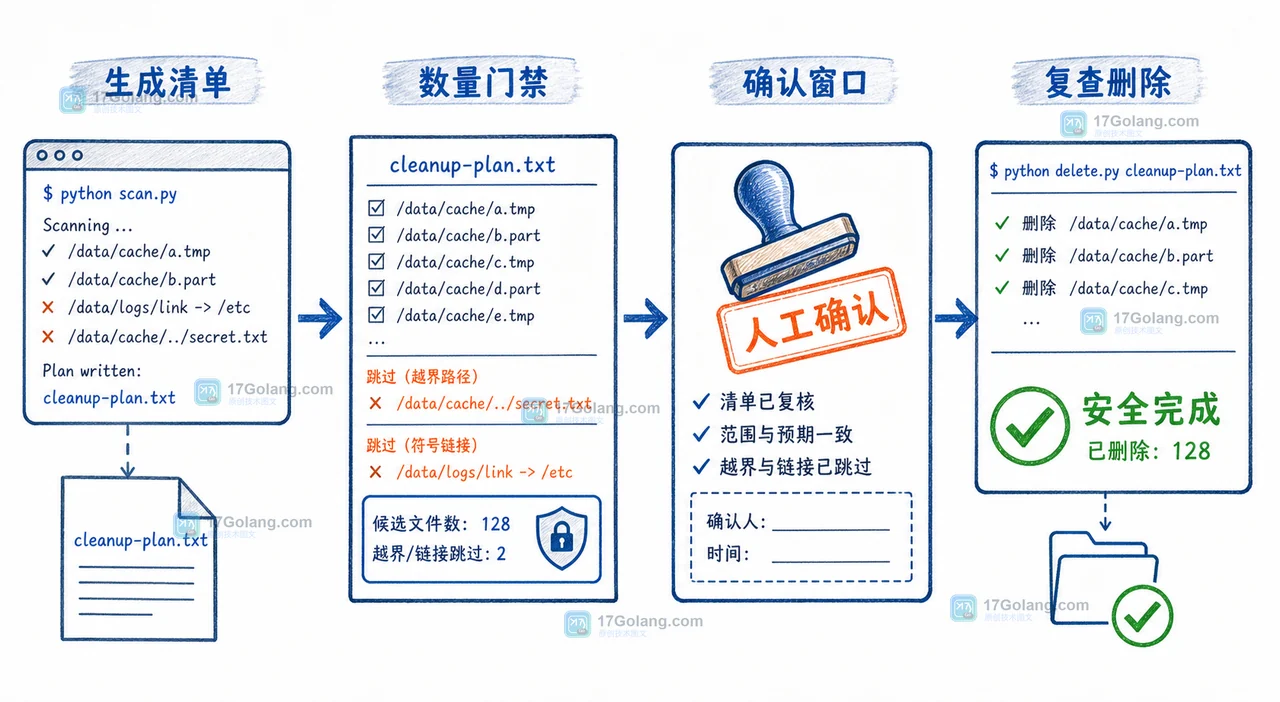 临时目录清理最容易出问题的地方,不是调用 unlink,而是筛选条件太宽、相对路径越界和删错文件后无法复盘。用 pathlib 统一解析路径,按后缀和 mtime 过滤,先写入待删清单再处理,就能把一次性脚本变成可检查、可回退的清理流程。219 收藏
临时目录清理最容易出问题的地方,不是调用 unlink,而是筛选条件太宽、相对路径越界和删错文件后无法复盘。用 pathlib 统一解析路径,按后缀和 mtime 过滤,先写入待删清单再处理,就能把一次性脚本变成可检查、可回退的清理流程。219 收藏 -
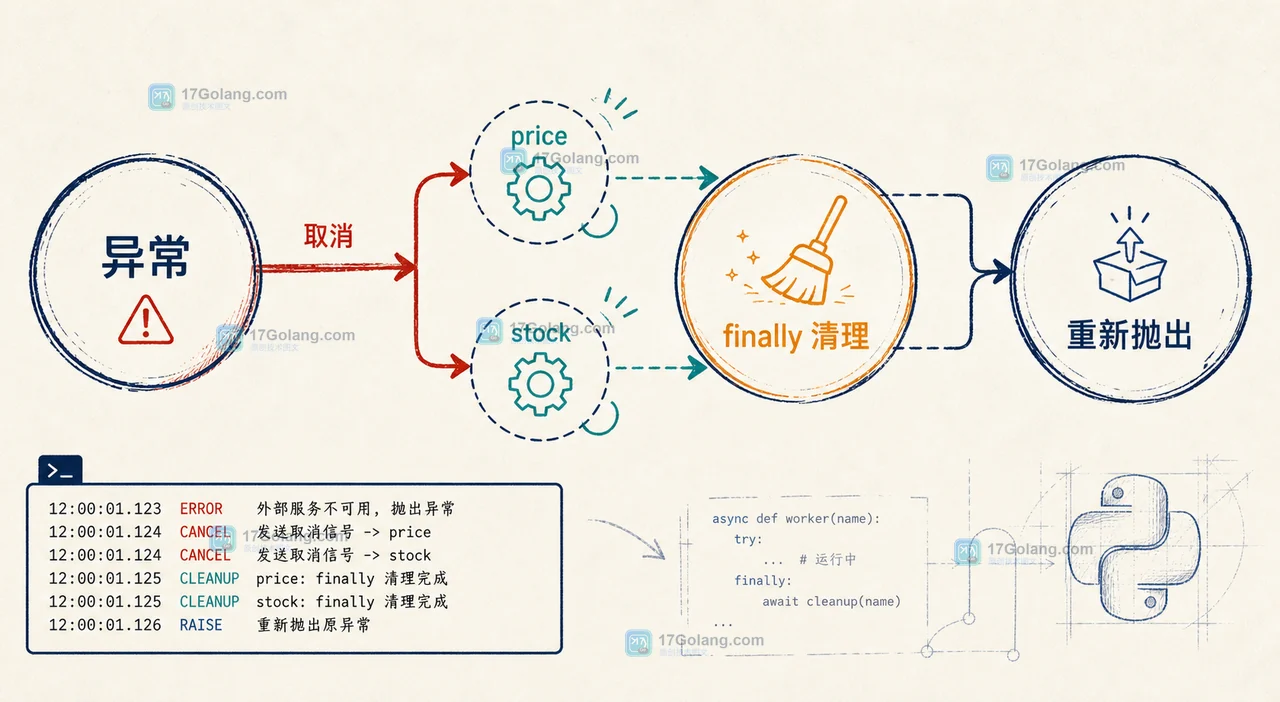 asyncio.gather 遇到子任务异常时,默认只把第一个异常交给调用方,其他任务可能仍在运行。本文用可复现实验说明 return_exceptions、Task.cancel 和 finally 清理之间的边界。210 收藏
asyncio.gather 遇到子任务异常时,默认只把第一个异常交给调用方,其他任务可能仍在运行。本文用可复现实验说明 return_exceptions、Task.cancel 和 finally 清理之间的边界。210 收藏 -
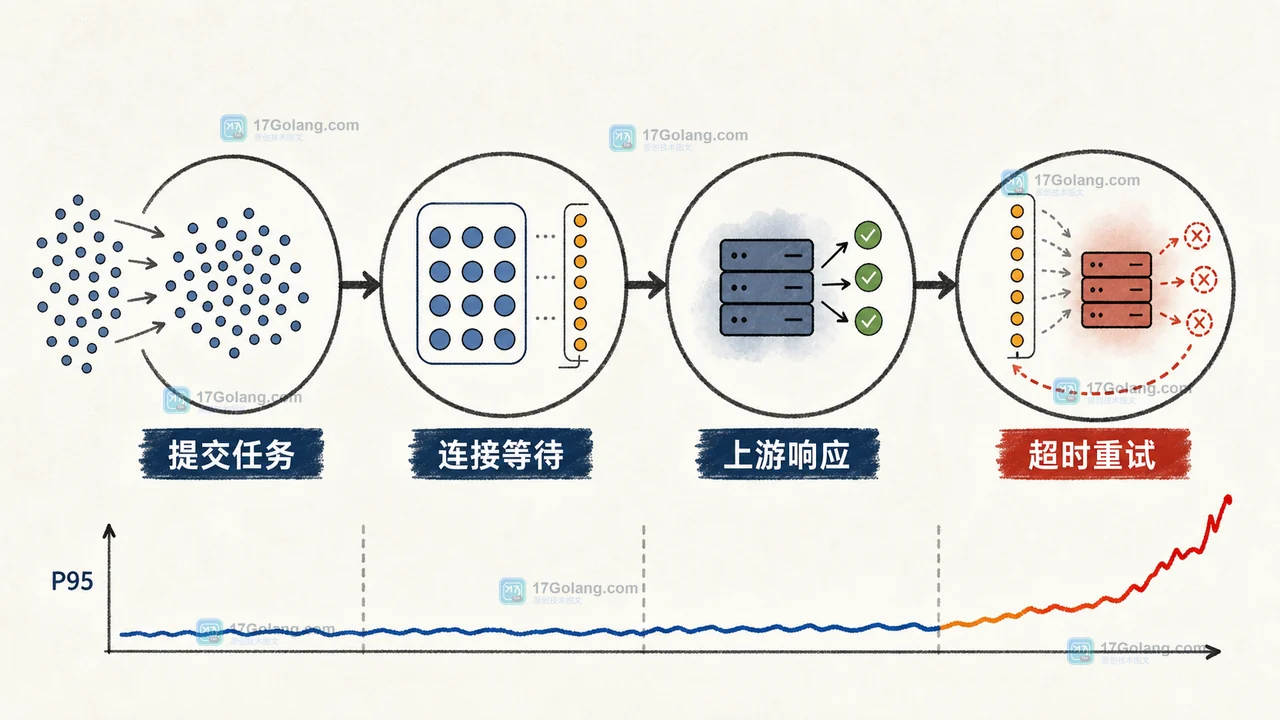 Python 批量调用外部接口时,任务越多不一定越快。本文从订单补数任务的耗时基线出发,用 httpx 连接池、asyncio.Semaphore 和超时预算控制请求数量,并通过压测结果说明配置边界与排查方法。196 收藏
Python 批量调用外部接口时,任务越多不一定越快。本文从订单补数任务的耗时基线出发,用 httpx 连接池、asyncio.Semaphore 和超时预算控制请求数量,并通过压测结果说明配置边界与排查方法。196 收藏 -
文章 · python教程 | 1星期前 | 并发编程 · python · 多线程 · asyncio · 多进程 · queue.Queue Python并发 Python任务队列 asyncio.Queue multiprocessing.Queue
 Python 里同样叫 Queue 的对象,其实服务于线程、协程和进程三种完全不同的边界。本文从任务在哪儿运行、满队列怎么背压、完成状态怎么收尾三个维度,比较 queue.Queue、asyncio.Queue 与 multiprocessing.Queue,并给出可直接核对的最小示例。165 收藏
Python 里同样叫 Queue 的对象,其实服务于线程、协程和进程三种完全不同的边界。本文从任务在哪儿运行、满队列怎么背压、完成状态怎么收尾三个维度,比较 queue.Queue、asyncio.Queue 与 multiprocessing.Queue,并给出可直接核对的最小示例。165 收藏 -
 Python 异步接口用 asyncio.wait_for 设置超时后,日志里却还能看到后台任务继续运行,通常不是 wait_for 失效,而是任务引用、shield 或 finally 清理边界没有处理好。本文用可复现代码拆开超时取消语义,并给出资源回收和验证方法。158 收藏
Python 异步接口用 asyncio.wait_for 设置超时后,日志里却还能看到后台任务继续运行,通常不是 wait_for 失效,而是任务引用、shield 或 finally 清理边界没有处理好。本文用可复现代码拆开超时取消语义,并给出资源回收和验证方法。158 收藏 -
 Python sqlite3 事务回滚经常不是数据库坏了,而是连接的 autocommit、旧式 isolation_level 与 with 代码块边界没有对齐。用一个可复现实验看清提交、回滚和异常传播。136 收藏
Python sqlite3 事务回滚经常不是数据库坏了,而是连接的 autocommit、旧式 isolation_level 与 with 代码块边界没有对齐。用一个可复现实验看清提交、回滚和异常传播。136 收藏 -
 Python multiprocessing.Pool 在服务停机时如果没有区分 close、terminate 和 join,主进程可能已经退出流程,子进程却仍然占着资源。本文用批处理场景复现停机卡住、按顺序解释三个方法的职责,并给出异常、超时和回滚检查清单。133 收藏
Python multiprocessing.Pool 在服务停机时如果没有区分 close、terminate 和 join,主进程可能已经退出流程,子进程却仍然占着资源。本文用批处理场景复现停机卡住、按顺序解释三个方法的职责,并给出异常、超时和回滚检查清单。133 收藏 -
文章 · python教程 | 1星期前 | 字符串 · 标准库 · 模板 · python · Python 3.14 · Template Python 3.14 t-string string.templatelib PEP 750
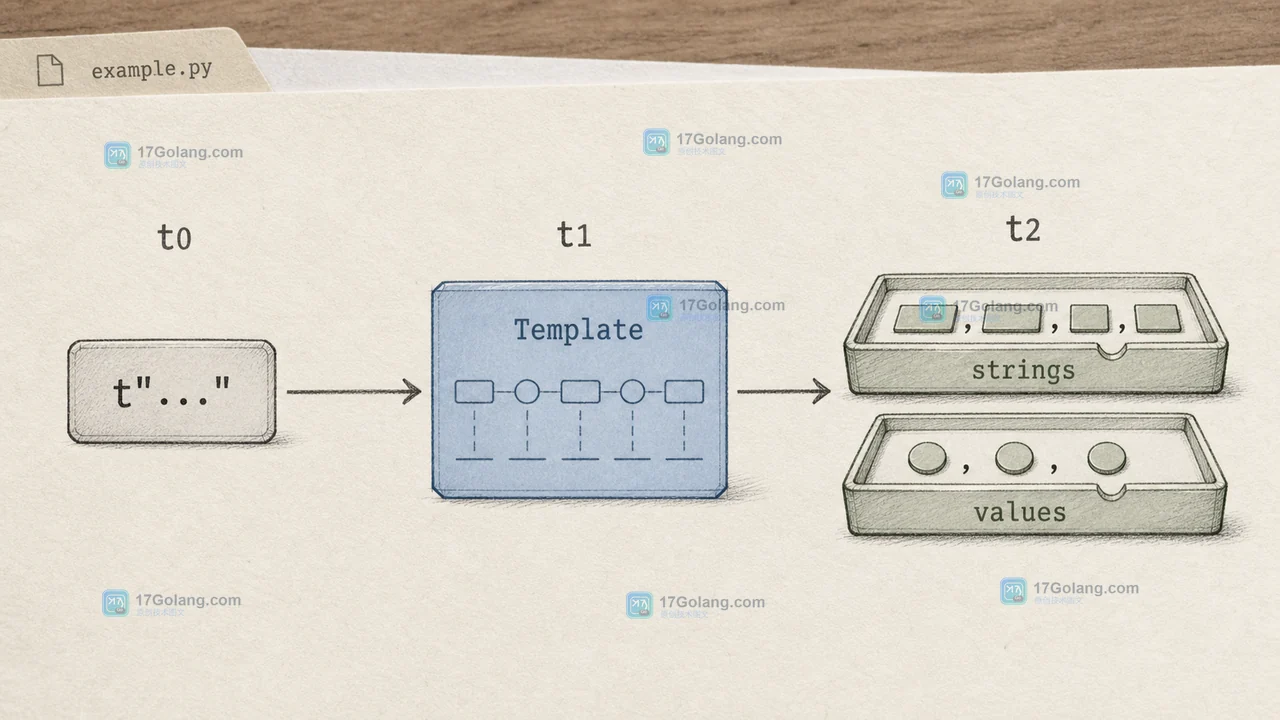 Python 3.14 的 t-string 仍使用花括号插值,但结果是可检查的 Template,而不是已经拼好的 str。掌握 strings、interpolations、conversion 与 format_spec 的边界,才能把它用于日志、HTML 或领域文本处理。121 收藏
Python 3.14 的 t-string 仍使用花括号插值,但结果是可检查的 Template,而不是已经拼好的 str。掌握 strings、interpolations、conversion 与 format_spec 的边界,才能把它用于日志、HTML 或领域文本处理。121 收藏 -
文章 · python教程 | 1星期前 | 面向对象 · python · 后端开发 · dataclass · default_factory · Python Field 可变默认值 dataclass default_factory 列表字段
 dataclass 里的 list、dict、set 不能直接当默认值:当前 Python 会把常见的不可哈希默认值拦成 ValueError。应使用 field(default_factory=list) 在每次创建实例时生成新列表;当默认值来自配置或需要延迟构造时,也要分清工厂函数、浅拷贝和 None 的语义。111 收藏
dataclass 里的 list、dict、set 不能直接当默认值:当前 Python 会把常见的不可哈希默认值拦成 ValueError。应使用 field(default_factory=list) 在每次创建实例时生成新列表;当默认值来自配置或需要延迟构造时,也要分清工厂函数、浅拷贝和 None 的语义。111 收藏