python教程技术文章
-
 全站脱敏显示必须重写Serializer的to_representation方法,而非to_internal_value;需结合模型Meta或显式声明敏感字段,在非DEBUG环境下执行掩码,且嵌套序列化器、SerializerMethodField等各路径均需统一处理。323 收藏
全站脱敏显示必须重写Serializer的to_representation方法,而非to_internal_value;需结合模型Meta或显式声明敏感字段,在非DEBUG环境下执行掩码,且嵌套序列化器、SerializerMethodField等各路径均需统一处理。323 收藏 -
 本文整理一套 Python 配置加载工作流,从默认值、JSON 文件、环境变量覆盖、字段检查到启动前错误报告,帮助你把散落的配置读取逻辑整理成可维护的入口。321 收藏
本文整理一套 Python 配置加载工作流,从默认值、JSON 文件、环境变量覆盖、字段检查到启动前错误报告,帮助你把散落的配置读取逻辑整理成可维护的入口。321 收藏 -
文章 · python教程 | 1星期前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理
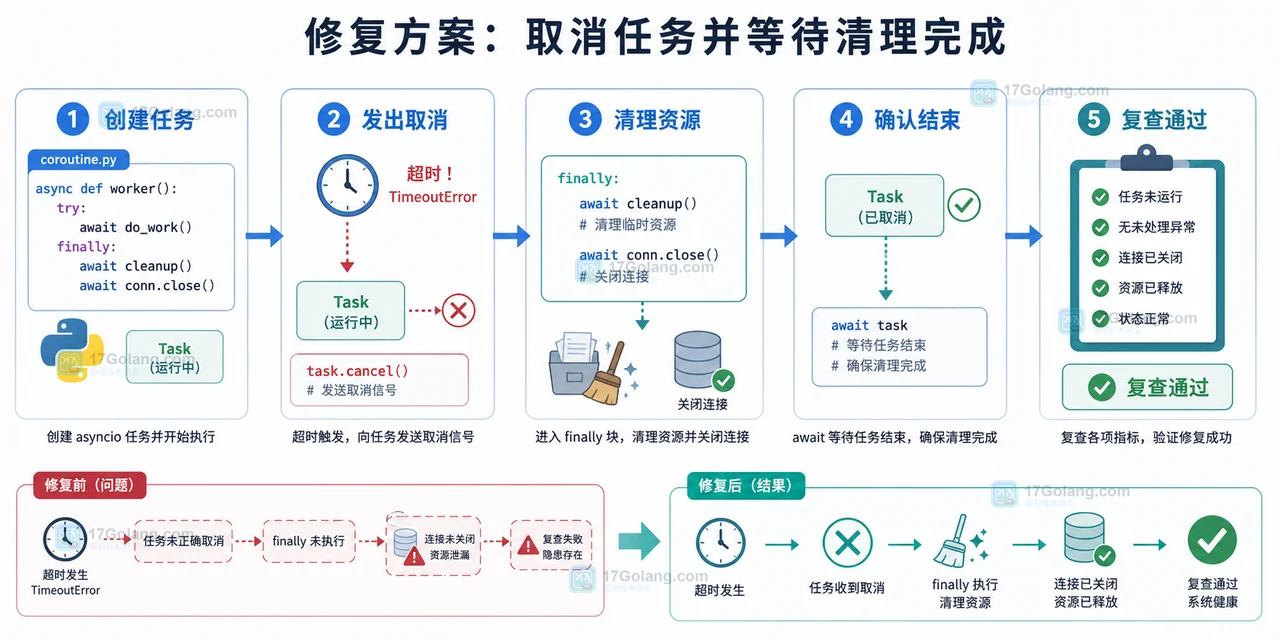 本文从一个 asyncio 超时后后台任务仍在继续的现象出发,排查 wait_for、shield、取消信号和资源清理的关系,并给出可复查的超时取消写法。320 收藏
本文从一个 asyncio 超时后后台任务仍在继续的现象出发,排查 wait_for、shield、取消信号和资源清理的关系,并给出可复查的超时取消写法。320 收藏 -
 猜数字游戏是Python入门的绝佳实践,它融合了随机数生成、用户交互、条件判断和循环控制等核心编程概念。通过构建这个游戏,初学者能直观理解代码如何与用户互动,并在解决输入验证、类型转换等问题的过程中加深对编程逻辑和数据类型的掌握。加入次数限制、自定义范围和再玩一次等功能可提升趣味性和挑战性,而良好的代码结构、变量命名及异常处理则有助于培养规范的编程习惯。这个小游戏不仅是语法练习,更是编程思维的启蒙训练。318 收藏
猜数字游戏是Python入门的绝佳实践,它融合了随机数生成、用户交互、条件判断和循环控制等核心编程概念。通过构建这个游戏,初学者能直观理解代码如何与用户互动,并在解决输入验证、类型转换等问题的过程中加深对编程逻辑和数据类型的掌握。加入次数限制、自定义范围和再玩一次等功能可提升趣味性和挑战性,而良好的代码结构、变量命名及异常处理则有助于培养规范的编程习惯。这个小游戏不仅是语法练习,更是编程思维的启蒙训练。318 收藏 -
 PyCharm的独特之处在于其集成的开发工具、丰富的自定义选项和快捷方式,以及对Python生态系统的全面支持。1)它提供了智能代码补全和调试功能,2)支持从Django到数据科学工具的广泛生态系统,3)具有强大的代码重构和性能优化工具,4)内置虚拟环境和依赖包管理功能,使得开发过程更加高效和顺畅。312 收藏
PyCharm的独特之处在于其集成的开发工具、丰富的自定义选项和快捷方式,以及对Python生态系统的全面支持。1)它提供了智能代码补全和调试功能,2)支持从Django到数据科学工具的广泛生态系统,3)具有强大的代码重构和性能优化工具,4)内置虚拟环境和依赖包管理功能,使得开发过程更加高效和顺畅。312 收藏 -
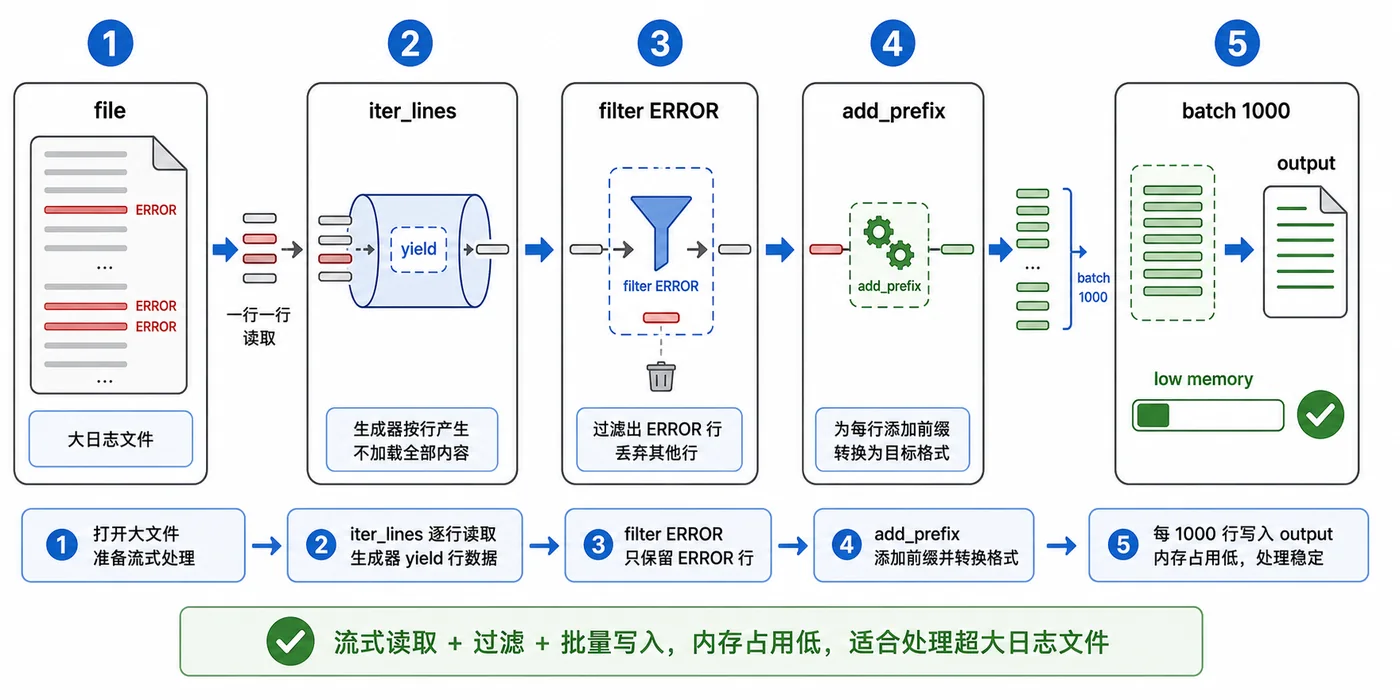 用日志清洗场景演示 Python 处理大文件的稳定方式:不要一次性 read 全部内容,而是用生成器逐行读取、过滤有效行,再按批次写入结果文件,降低内存压力。311 收藏
用日志清洗场景演示 Python 处理大文件的稳定方式:不要一次性 read 全部内容,而是用生成器逐行读取、过滤有效行,再按批次写入结果文件,降低内存压力。311 收藏 -
文章 · python教程 | 3星期前 | ORM · Django · 异步编程 · 生产实践 · Python教程 · 后端开发 · Python Django 性能优化 orm 事务 ASGI 生产实践 async view sync_to_async
 从 Python Django async view 线上改造入手,讲清异步视图、同步 ORM 边界、sync_to_async、事务收口和上线检查。310 收藏
从 Python Django async view 线上改造入手,讲清异步视图、同步 ORM 边界、sync_to_async、事务收口和上线检查。310 收藏 -
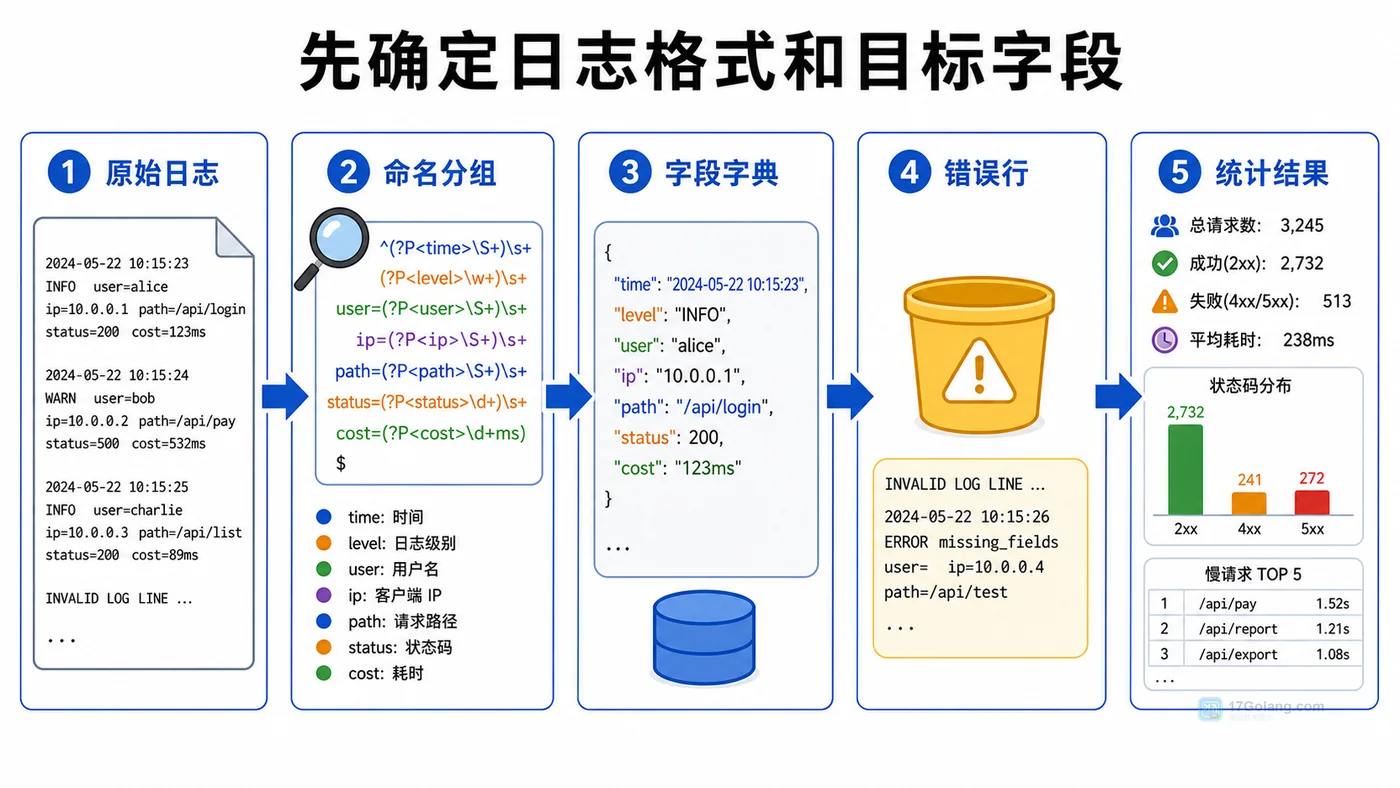 本文用 Python 解析访问日志的场景讲清正则命名分组:如何把原始日志拆成字段字典,如何处理格式不符合预期的错误行,最后统计接口访问次数、状态码分布和慢请求。308 收藏
本文用 Python 解析访问日志的场景讲清正则命名分组:如何把原始日志拆成字段字典,如何处理格式不符合预期的错误行,最后统计接口访问次数、状态码分布和慢请求。308 收藏 -
 直接MockSQLAlchemy模型易失败,因其非可调用对象,真正需Mock的是session实例及其Query链式行为,须让mock支持.filter()等中间调用并仅在.all()等终端方法返回数据。304 收藏
直接MockSQLAlchemy模型易失败,因其非可调用对象,真正需Mock的是session实例及其Query链式行为,须让mock支持.filter()等中间调用并仅在.all()等终端方法返回数据。304 收藏 -
文章 · python教程 | 3星期前 | 工程化 · 自动化测试 · pytest · CI · 生产实践 · Python教程 · Python CI pytest fixture tmp_path monkeypatch pytest-xdist 测试稳定性
 从 Python 项目 CI 偶发失败入手,讲清 pytest fixture 共享状态、tmp_path 文件隔离、monkeypatch 自动回滚和 xdist 并发验证的实战治理方法。303 收藏
从 Python 项目 CI 偶发失败入手,讲清 pytest fixture 共享状态、tmp_path 文件隔离、monkeypatch 自动回滚和 xdist 并发验证的实战治理方法。303 收藏 -
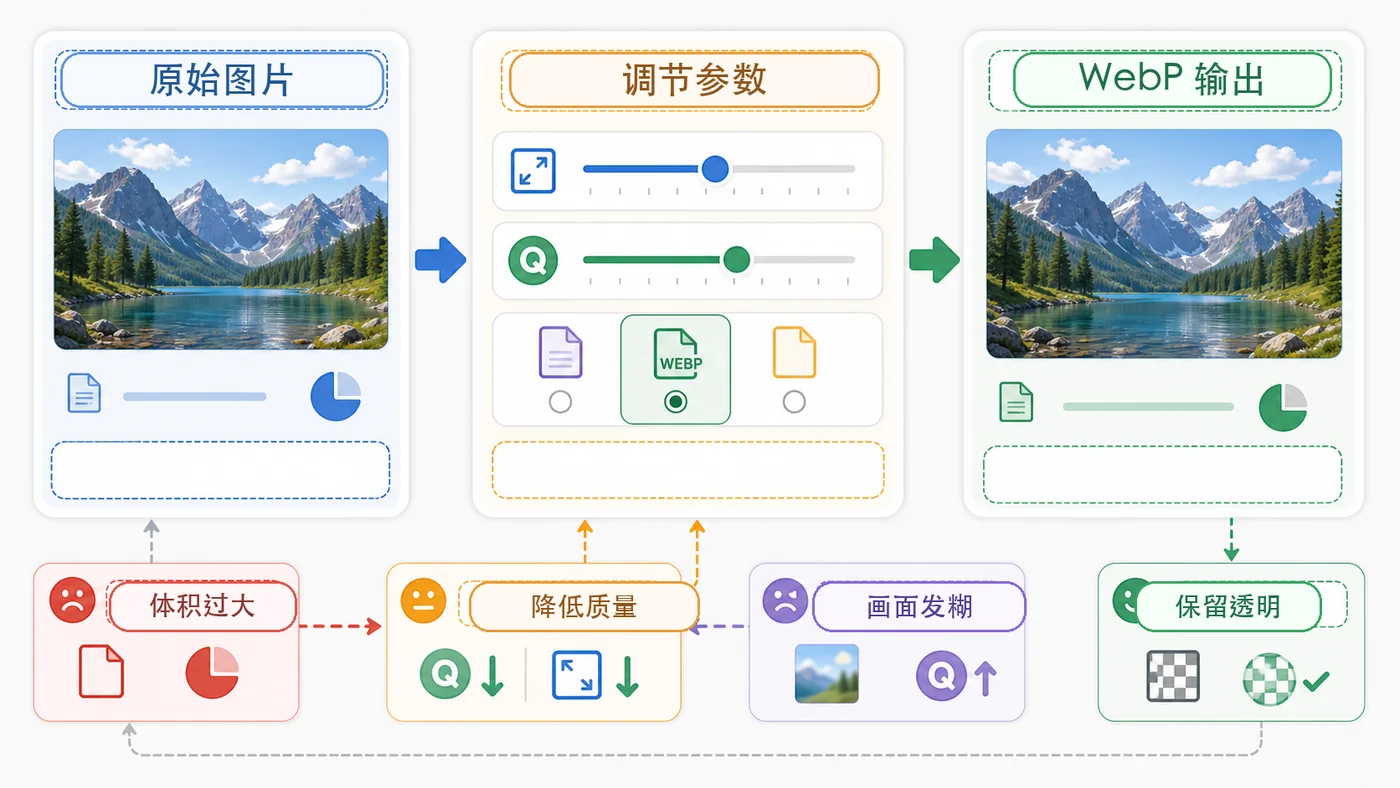 本文用 Python Pillow 实现图片批量压缩:从输入目录读取图片,按最大宽度等比缩放,输出 WebP,并生成压缩清单方便检查体积和清晰度。299 收藏
本文用 Python Pillow 实现图片批量压缩:从输入目录读取图片,按最大宽度等比缩放,输出 WebP,并生成压缩清单方便检查体积和清晰度。299 收藏 -
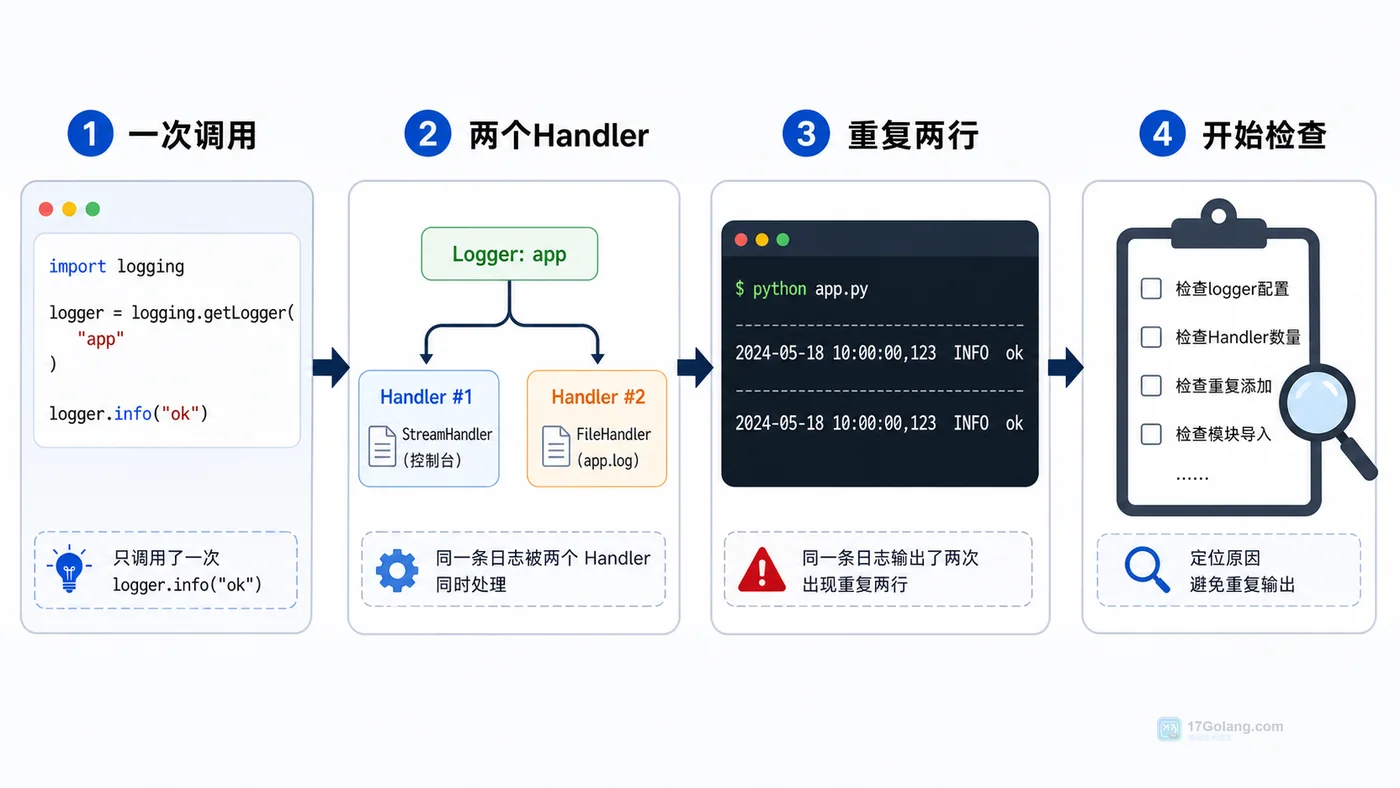 Python 项目里同一条日志重复出现两三次,常见原因是重复 addHandler 或子 logger 向根 logger 继续上抛。本文从复现现象开始,逐步检查 Handler 数量、logger 层级和 propagate 配置,整理一套稳定的日志初始化写法。299 收藏
Python 项目里同一条日志重复出现两三次,常见原因是重复 addHandler 或子 logger 向根 logger 继续上抛。本文从复现现象开始,逐步检查 Handler 数量、logger 层级和 propagate 配置,整理一套稳定的日志初始化写法。299 收藏 -
 本文详解如何在Python中使用glob模块编写准确的通配符模式,匹配形如123_beta_faces.nii.gz或042_beta_faces_up.nii.gz的文件路径,避免过度匹配,并给出可直接运行的代码示例与关键注意事项。本文详解如何在Python中使用`glob`模块编写准确的通配符模式,匹配形如`123_beta_faces.nii.gz`或`042_beta_faces_up.nii.gz`的文件路径,避免267 收藏
本文详解如何在Python中使用glob模块编写准确的通配符模式,匹配形如123_beta_faces.nii.gz或042_beta_faces_up.nii.gz的文件路径,避免过度匹配,并给出可直接运行的代码示例与关键注意事项。本文详解如何在Python中使用`glob`模块编写准确的通配符模式,匹配形如`123_beta_faces.nii.gz`或`042_beta_faces_up.nii.gz`的文件路径,避免267 收藏 -
 本文详解如何在Pandas中根据sum和结构不一的bid字符串字段(含百分比、固定金额、分段条件)逐行计算commission,通过正则解析+条件匹配实现灵活、鲁棒的行级逻辑运算。本文详解如何在Pandes中根据`sum`和结构不一的`bid`字符串字段(含百分比、固定金额、分段条件)逐行计算commission,通过正则解析+条件匹配实现灵活、鲁棒的行级逻辑运算。在实际金融或交易类数据分析中,佣金(commission265 收藏
本文详解如何在Pandas中根据sum和结构不一的bid字符串字段(含百分比、固定金额、分段条件)逐行计算commission,通过正则解析+条件匹配实现灵活、鲁棒的行级逻辑运算。本文详解如何在Pandes中根据`sum`和结构不一的`bid`字符串字段(含百分比、固定金额、分段条件)逐行计算commission,通过正则解析+条件匹配实现灵活、鲁棒的行级逻辑运算。在实际金融或交易类数据分析中,佣金(commission265 收藏 -
 async-lru能直接装饰asyncdef函数,但必须用@alru_cache()(带括号),否则装饰器未生效;它基于asyncio.Lock保证并发安全,缓存键由可哈希参数生成,不支持TTL、不可哈希类型或session实例传参。261 收藏
async-lru能直接装饰asyncdef函数,但必须用@alru_cache()(带括号),否则装饰器未生效;它基于asyncio.Lock保证并发安全,缓存键由可哈希参数生成,不支持TTL、不可哈希类型或session实例传参。261 收藏