python教程技术文章
-
文章 · python教程 | 3星期前 | WEB开发 · 工程化 · 配置管理 · flask · 生产实践 · Python教程 · Python Flask G 配置管理 请求上下文 应用上下文 生产实践 current_app teardown app factory
 从 Python Flask 生产连接泄漏和上下文错误入手,讲清 app factory、配置加载、g 请求内资源缓存、teardown 清理和后台任务边界。257 收藏
从 Python Flask 生产连接泄漏和上下文错误入手,讲清 app factory、配置加载、g 请求内资源缓存、teardown 清理和后台任务边界。257 收藏 -
 Python字符串匹配主要靠re模块,核心是编写正确pattern并调用对应函数:match()从开头匹配,search()全局搜索;findall()返回匹配字符串列表,finditer()返回含位置等信息的Match对象迭代器;sub()替换、split()分割;常用pattern建议compile编译提升效率,括号实现分组提取。253 收藏
Python字符串匹配主要靠re模块,核心是编写正确pattern并调用对应函数:match()从开头匹配,search()全局搜索;findall()返回匹配字符串列表,finditer()返回含位置等信息的Match对象迭代器;sub()替换、split()分割;常用pattern建议compile编译提升效率,括号实现分组提取。253 收藏 -
 strip()仅删除字符串首尾属于指定字符集的字符,不按子串匹配;removeprefix/removesuffix则精确删除固定前缀或后缀,Python3.9+引入,语义明确、安全可靠。252 收藏
strip()仅删除字符串首尾属于指定字符集的字符,不按子串匹配;removeprefix/removesuffix则精确删除固定前缀或后缀,Python3.9+引入,语义明确、安全可靠。252 收藏 -
 不安全。Flask的session虽支持字典操作,但仅防篡改不加密,依赖SECRET_KEY签名Cookie;未设密钥则静默失效;应优先用session.get()防KeyError,并避免存敏感数据。244 收藏
不安全。Flask的session虽支持字典操作,但仅防篡改不加密,依赖SECRET_KEY签名Cookie;未设密钥则静默失效;应优先用session.get()防KeyError,并避免存敏感数据。244 收藏 -
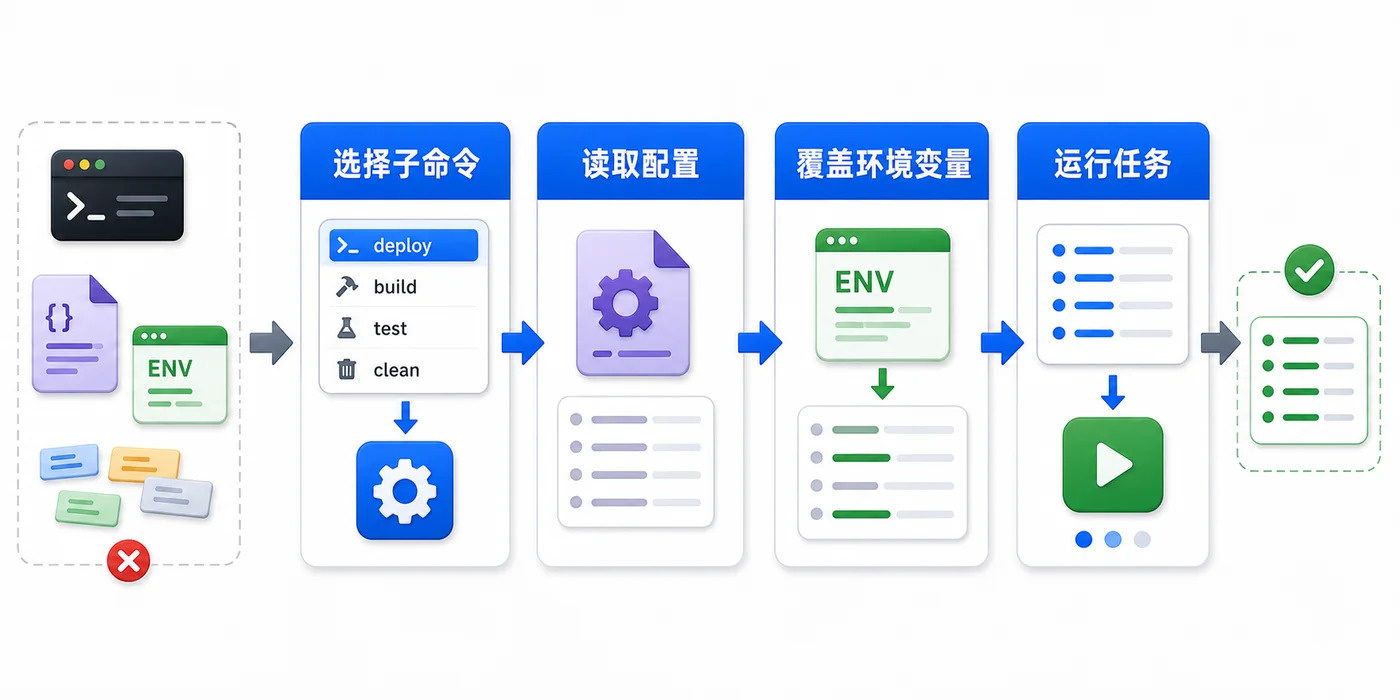 本文用日志清理工具做例子,演示 Python argparse 如何解析参数、校验类型、设计子命令,并把配置文件和环境变量合并成最终运行参数。241 收藏
本文用日志清理工具做例子,演示 Python argparse 如何解析参数、校验类型、设计子命令,并把配置文件和环境变量合并成最终运行参数。241 收藏 -
 面对千类万人脸数据集(每类10张图像),直接使用DeepFace内置预训练模型提取特征并构建分类器是高效可靠的选择;微调需谨慎评估计算成本与泛化风险,通常不建议从零训练。面对千类万人脸数据集(每类10张图像),直接使用DeepFace内置预训练模型提取特征并构建分类器是高效可靠的选择;微调需谨慎评估计算成本与泛化风险,通常不建议从零训练。在实际人脸识别任务中,模型选择的核心逻辑不是“能否微调”,而是“是否值得微调”。DeepFace默认集成的VGG-Fac238 收藏
面对千类万人脸数据集(每类10张图像),直接使用DeepFace内置预训练模型提取特征并构建分类器是高效可靠的选择;微调需谨慎评估计算成本与泛化风险,通常不建议从零训练。面对千类万人脸数据集(每类10张图像),直接使用DeepFace内置预训练模型提取特征并构建分类器是高效可靠的选择;微调需谨慎评估计算成本与泛化风险,通常不建议从零训练。在实际人脸识别任务中,模型选择的核心逻辑不是“能否微调”,而是“是否值得微调”。DeepFace默认集成的VGG-Fac238 收藏 -
文章 · python教程 | 3星期前 | 工程化 · 性能优化 · 内存分析 · 故障排查 · 生产实践 · Python教程 · Python 故障排查 内存泄漏 rss 性能优化 GC tracemalloc 生产实践 snapshot diff
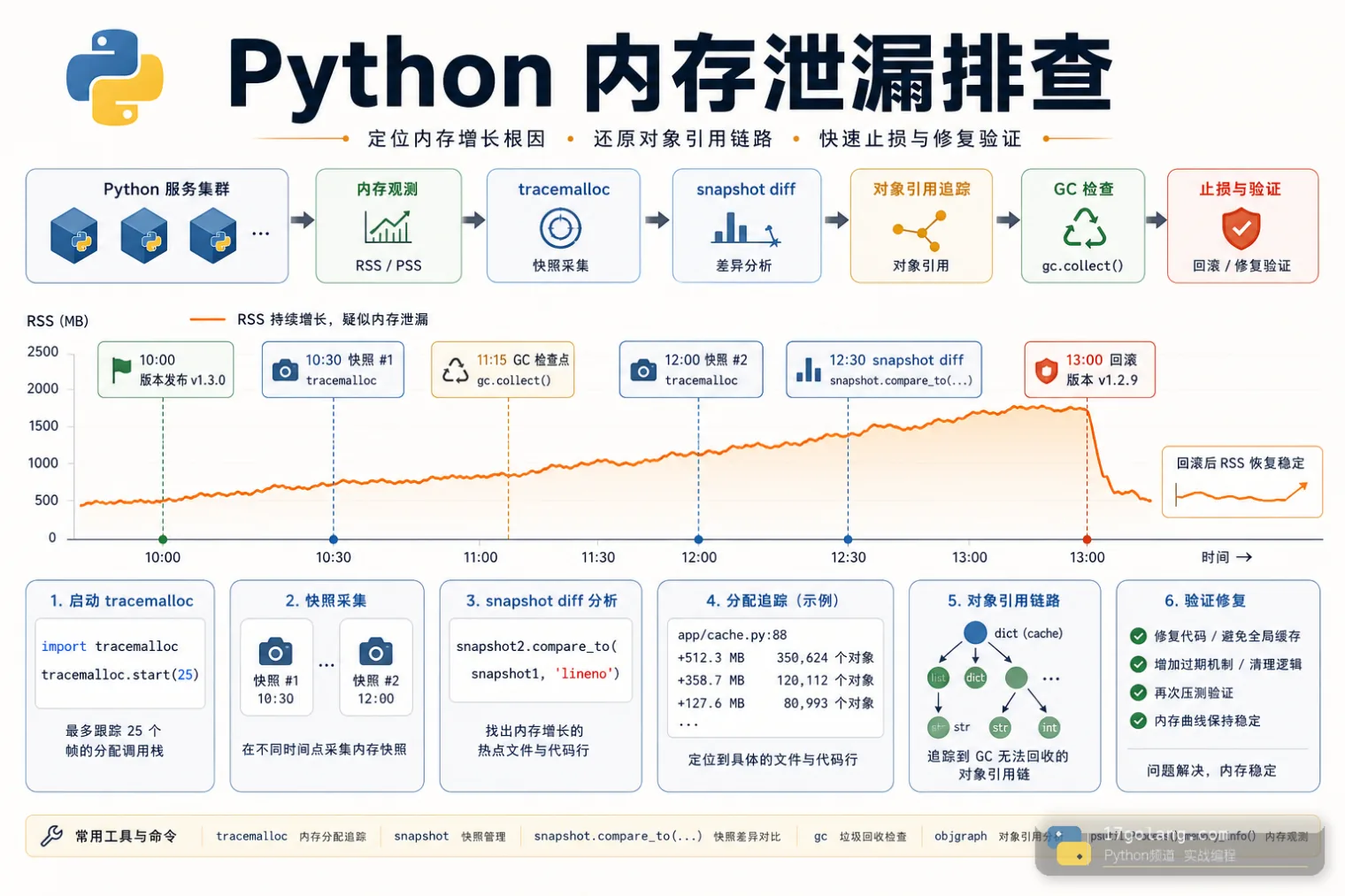 从 Python 服务 RSS 持续增长事故入手,实战讲解 tracemalloc 快照 diff、gc 引用检查、缓存失控定位和上线回归。230 收藏
从 Python 服务 RSS 持续增长事故入手,实战讲解 tracemalloc 快照 diff、gc 引用检查、缓存失控定位和上线回归。230 收藏 -
文章 · python教程 | 1星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory
 本文梳理 Python dataclass 默认值的完整落地流程:先定清字段边界,再识别 list、dict、set 等可变值,用 field(default_factory=...) 生成独立对象,并通过小测试确认实例隔离。228 收藏
本文梳理 Python dataclass 默认值的完整落地流程:先定清字段边界,再识别 list、dict、set 等可变值,用 field(default_factory=...) 生成独立对象,并通过小测试确认实例隔离。228 收藏 -
 yagmail是专为Gmail设计的Python库,简化SMTP邮件发送。通过pipinstallyagmail安装后,可使用应用专用密码登录:yag=yagmail.SMTP('your_email@gmail.com','your_password'),调用send方法发送文本邮件。支持带附件、图片内联和HTML内容,contents可传字符串或列表,包含文件路径自动处理。可通过cc添加抄送。推荐使用yagmail.register()将密码保存至系统密钥环,避免明文泄露。适用于日志提醒、报表发送等自213 收藏
yagmail是专为Gmail设计的Python库,简化SMTP邮件发送。通过pipinstallyagmail安装后,可使用应用专用密码登录:yag=yagmail.SMTP('your_email@gmail.com','your_password'),调用send方法发送文本邮件。支持带附件、图片内联和HTML内容,contents可传字符串或列表,包含文件路径自动处理。可通过cc添加抄送。推荐使用yagmail.register()将密码保存至系统密钥环,避免明文泄露。适用于日志提醒、报表发送等自213 收藏 -
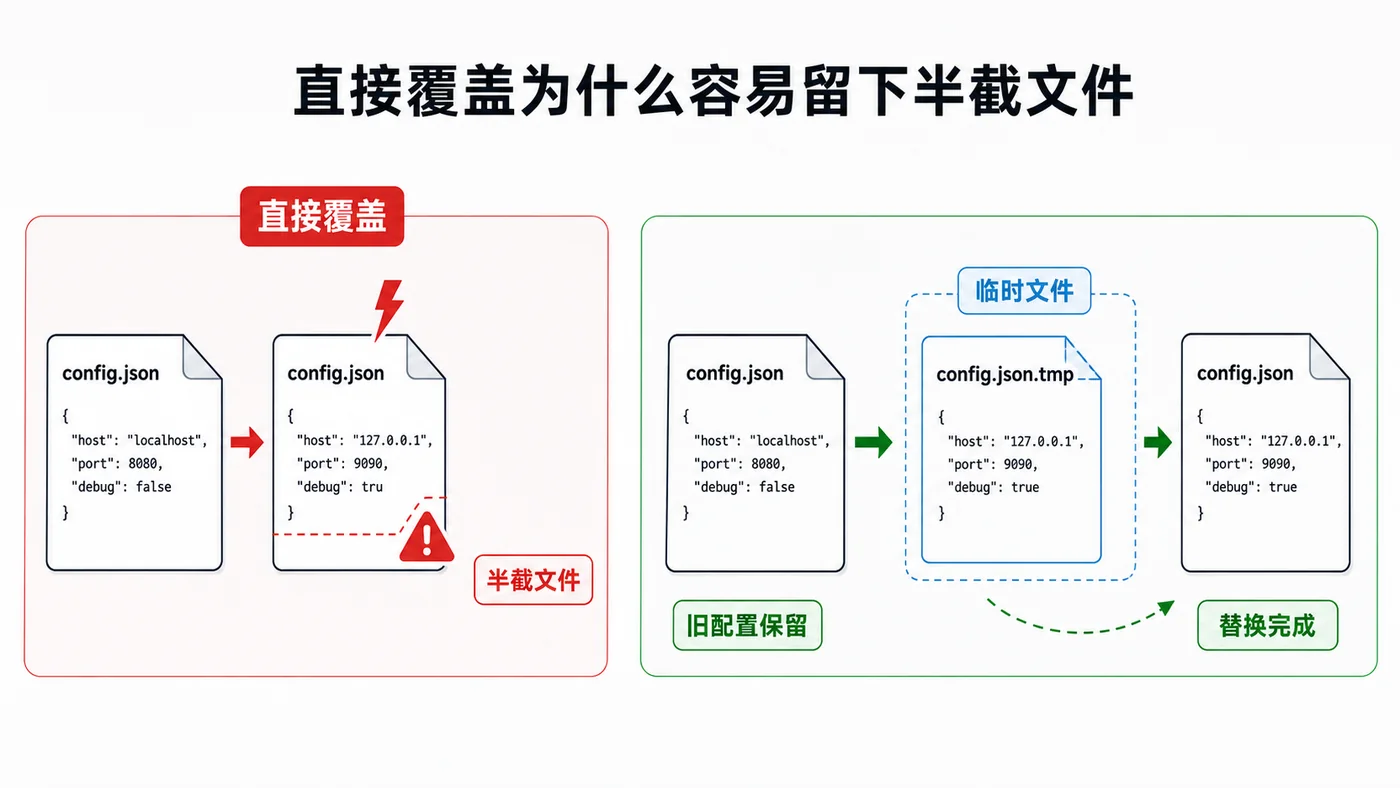 本文用 Python 标准库实现配置文件原子写入:先写临时文件、刷盘校验,再用 os.replace 一步替换目标文件,避免程序中断时留下半截配置。209 收藏
本文用 Python 标准库实现配置文件原子写入:先写临时文件、刷盘校验,再用 os.replace 一步替换目标文件,避免程序中断时留下半截配置。209 收藏 -
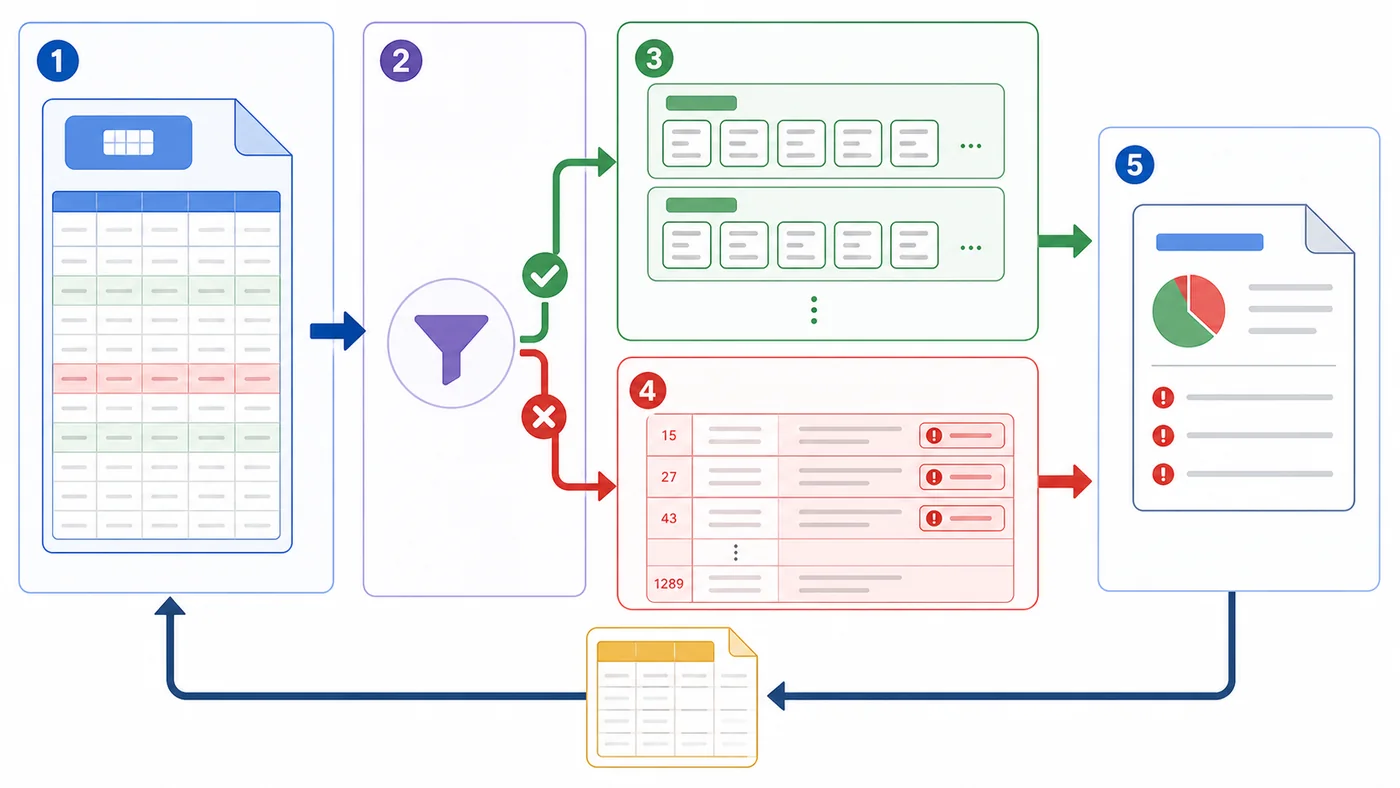 本文用用户 CSV 导入场景,演示如何边读边校验、按批次写入、收集错误行并生成失败明细,避免一次性读入和半成功数据污染。204 收藏
本文用用户 CSV 导入场景,演示如何边读边校验、按批次写入、收集错误行并生成失败明细,避免一次性读入和半成功数据污染。204 收藏 -
 asyncio.run()无法直接捕获create_task启动的任务异常,需在任务内处理或通过await、gather(return_exceptions=True)、task.exception()显式获取;retrying不支持异步。196 收藏
asyncio.run()无法直接捕获create_task启动的任务异常,需在任务内处理或通过await、gather(return_exceptions=True)、task.exception()显式获取;retrying不支持异步。196 收藏 -
 本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如Overtake(v1))必然为真,从而实现确定性行为推理。本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如`Overtake(v1)`)必然为真,从而实现确定性行为推理。在自动驾驶或形式化安全推理场景中,仅满足约束是不够的——我们需要196 收藏
本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如Overtake(v1))必然为真,从而实现确定性行为推理。本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如`Overtake(v1)`)必然为真,从而实现确定性行为推理。在自动驾驶或形式化安全推理场景中,仅满足约束是不够的——我们需要196 收藏 -
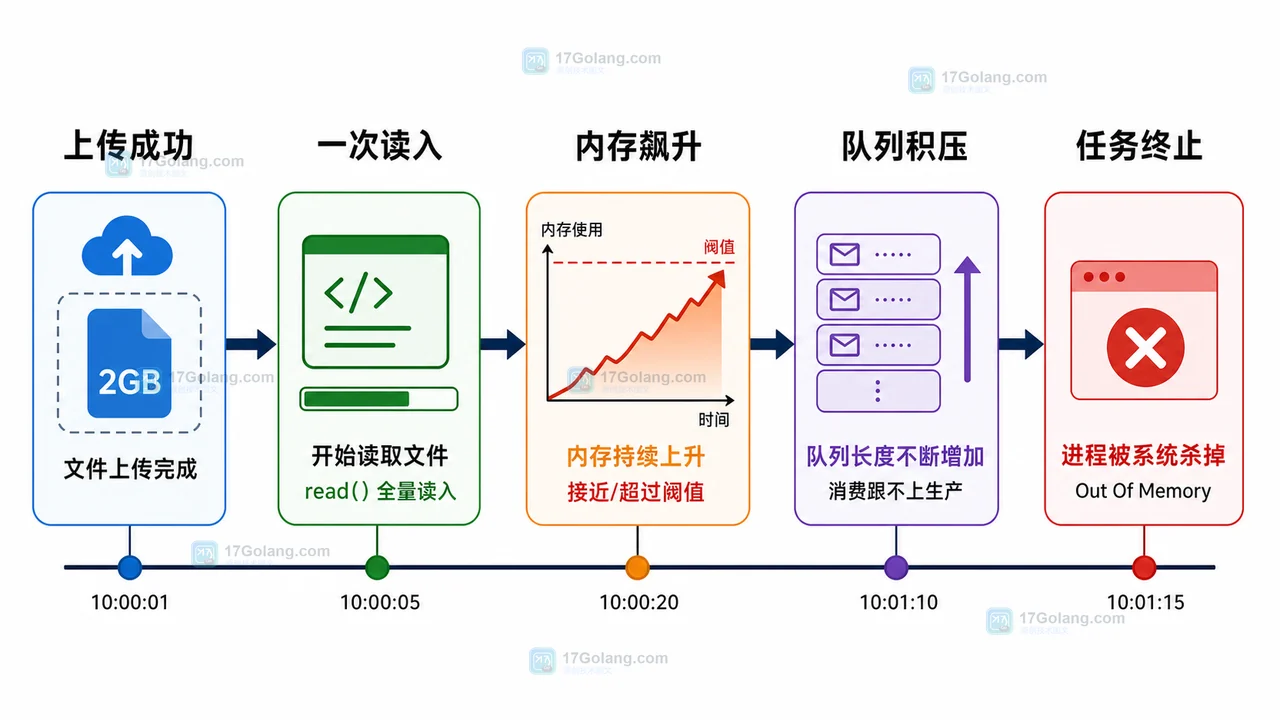 复盘一次 Python 大文件导入导致内存飙升的问题,按影响面、时间线、触发条件、根因、修复动作和防复发清单讲清 read() 一次读入与分块迭代的差异。196 收藏
复盘一次 Python 大文件导入导致内存飙升的问题,按影响面、时间线、触发条件、根因、修复动作和防复发清单讲清 read() 一次读入与分块迭代的差异。196 收藏 -
 嵌套字典是轻量级Trie实现,用dict键存字符、值为子节点,以'END'标记单词结尾;需注意键类型、终止标识设计、避免可变默认参数、空字符串处理及重叠前缀路径复用。192 收藏
嵌套字典是轻量级Trie实现,用dict键存字符、值为子节点,以'END'标记单词结尾;需注意键类型、终止标识设计、避免可变默认参数、空字符串处理及重叠前缀路径复用。192 收藏