-
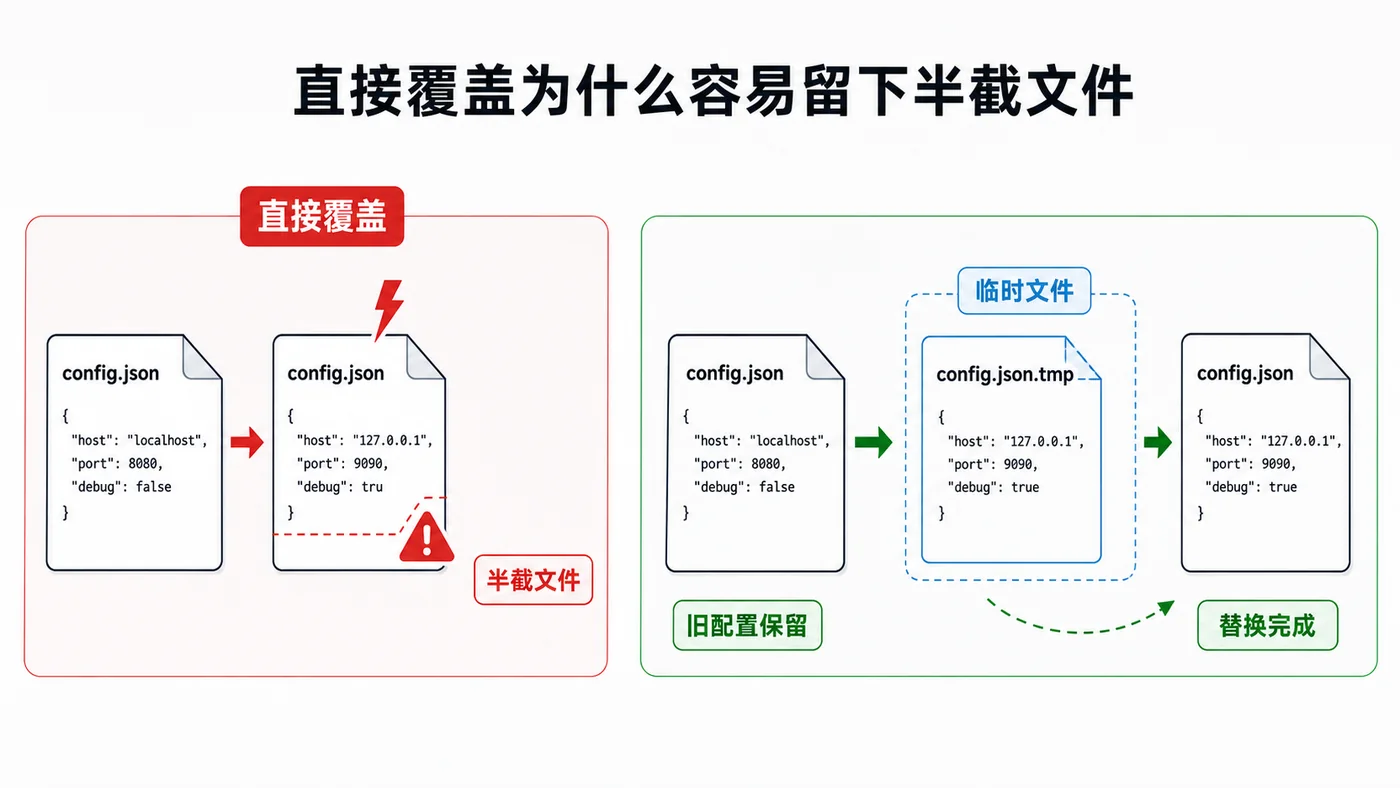
本文用 Python 标准库实现配置文件原子写入:先写临时文件、刷盘校验,再用 os.replace 一步替换目标文件,避免程序中断时留下半截配置。
-
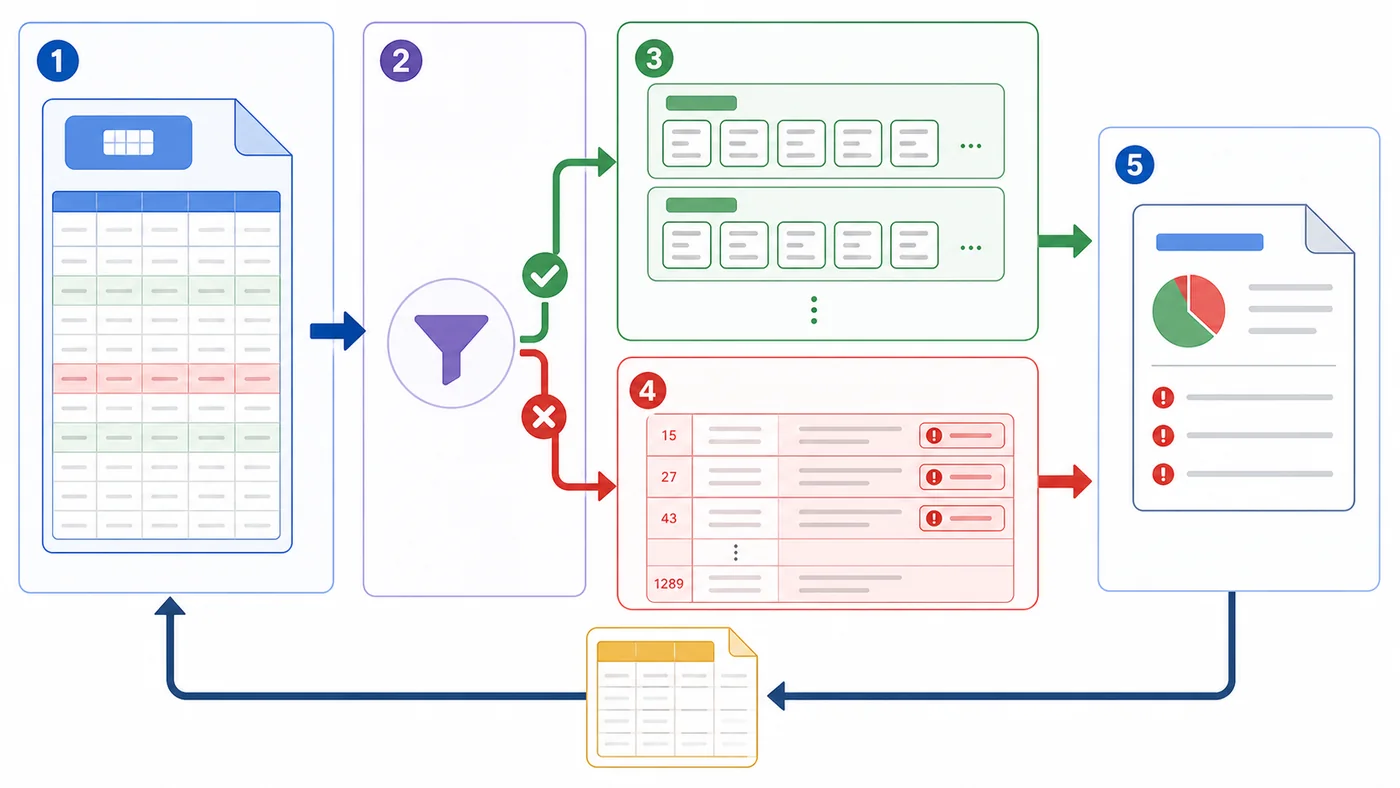
本文用用户 CSV 导入场景,演示如何边读边校验、按批次写入、收集错误行并生成失败明细,避免一次性读入和半成功数据污染。
-

asyncio.run()无法直接捕获create_task启动的任务异常,需在任务内处理或通过await、gather(return_exceptions=True)、task.exception()显式获取;retrying不支持异步。
-

本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如Overtake(v1))必然为真,从而实现确定性行为推理。本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如`Overtake(v1)`)必然为真,从而实现确定性行为推理。在自动驾驶或形式化安全推理场景中,仅满足约束是不够的——我们需要
-
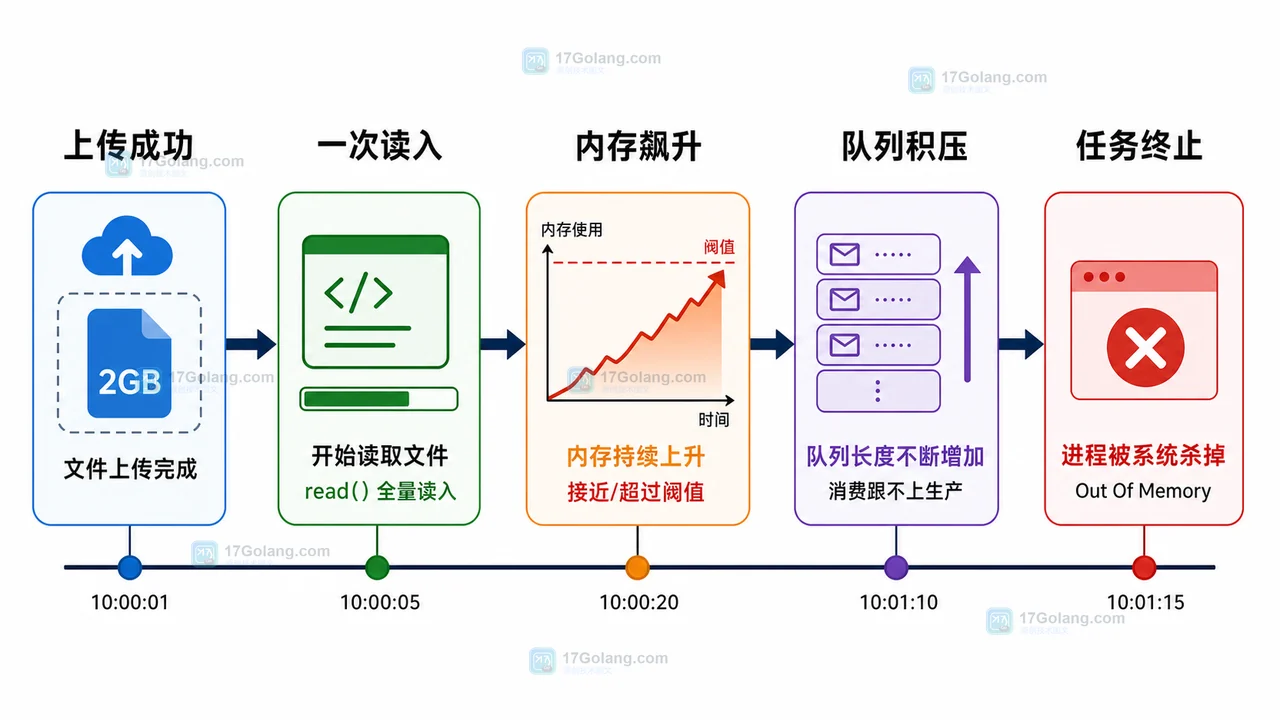
复盘一次 Python 大文件导入导致内存飙升的问题,按影响面、时间线、触发条件、根因、修复动作和防复发清单讲清 read() 一次读入与分块迭代的差异。
-

嵌套字典是轻量级Trie实现,用dict键存字符、值为子节点,以'END'标记单词结尾;需注意键类型、终止标识设计、避免可变默认参数、空字符串处理及重叠前缀路径复用。
-

递归函数测试最常漏掉的三个边界是0、1、负值;出错常因边界未处理,如factorial(n)未处理n==0或n<0导致栈溢出或错误结果。
-
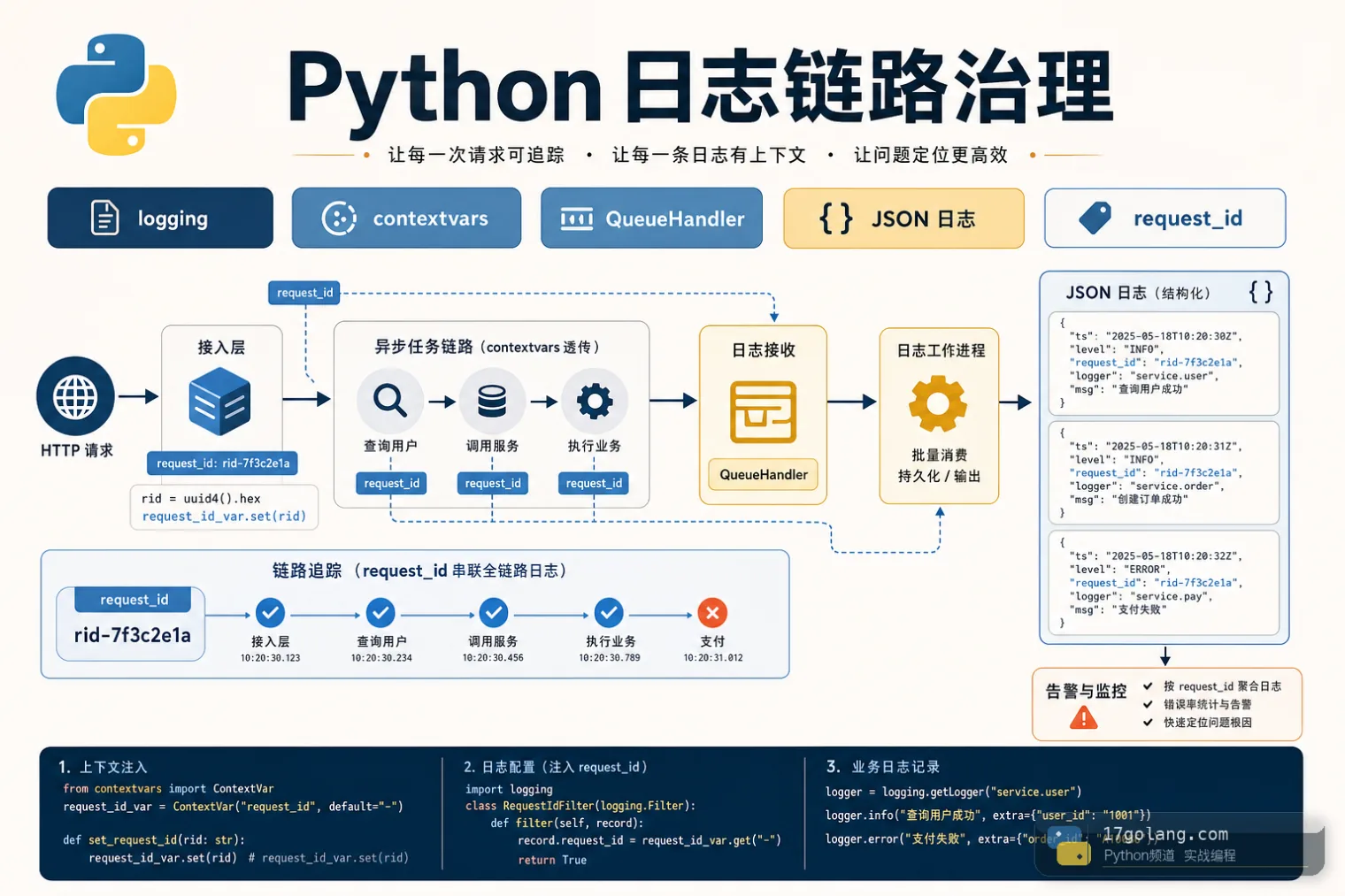
从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。
-

本文介绍如何对位于分段线性3D路径上的点进行精确的距离插值——关键在于识别问题本质为1D参数化插值,而非错误地使用3D空间插值(如griddata),从而避免NaN输出并提升计算效率与精度。本文介绍如何对位于分段线性3D路径上的点进行精确的距离插值——关键在于识别问题本质为1D参数化插值,而非错误地使用3D空间插值(如`griddata`),从而避免NaN输出并提升计算效率与精度。在处理沿3D曲线分布的数据时,一个常见误区是将路径点视为不规则三维散点,并直
-

HuberLoss默认delta=1.0易导致退化为MSE,需根据数据误差尺度(如四分位数)显式设置delta,并区分使用tf.keras.losses.Huber(Loss类)与tf.losses.Huber(函数),编译模型时必须用前者并指定reduction。
-

答案是使用Python解决LeetCode题目需理解题意并按函数签名实现逻辑,常用双指针、哈希表、滑动窗口、DFS/BFS和动态规划等算法,结合数据结构优化解法,通过手动测试用例和平台验证调试,建议分类刷题、总结模板并学习优质解答以提升效率。
-

Flask默认日志不写入文件是因为开发服务器仅输出到stderr且未配置文件handler;生产环境日志更易被WSGI接管或丢弃。常见问题包括basicConfig失效、日志仅显示在终端、重启后文件为空及多进程错乱。根本原因是app.logger是独立实例,不继承rootlogger配置,且Flask启动时已添加StreamHandler,basicConfig仅在root无handler时生效;同时若未显式设置日志级别,WARNING以下消息会被过滤。可靠写法是直接为app.logger添加Rotati
-

shutil.copytree默认要求目标目录不存在,否则抛FileExistsError;Python3.8+可用dirs_exist_ok=True跳过该错误,仅覆盖同名文件,不清理目标中多余内容。
-

Safety仅扫描requirements.txt中的直接依赖,不递归分析子依赖或锁定文件,也不检测逻辑漏洞;需加--full-report才显示CVE编号等完整信息。
-
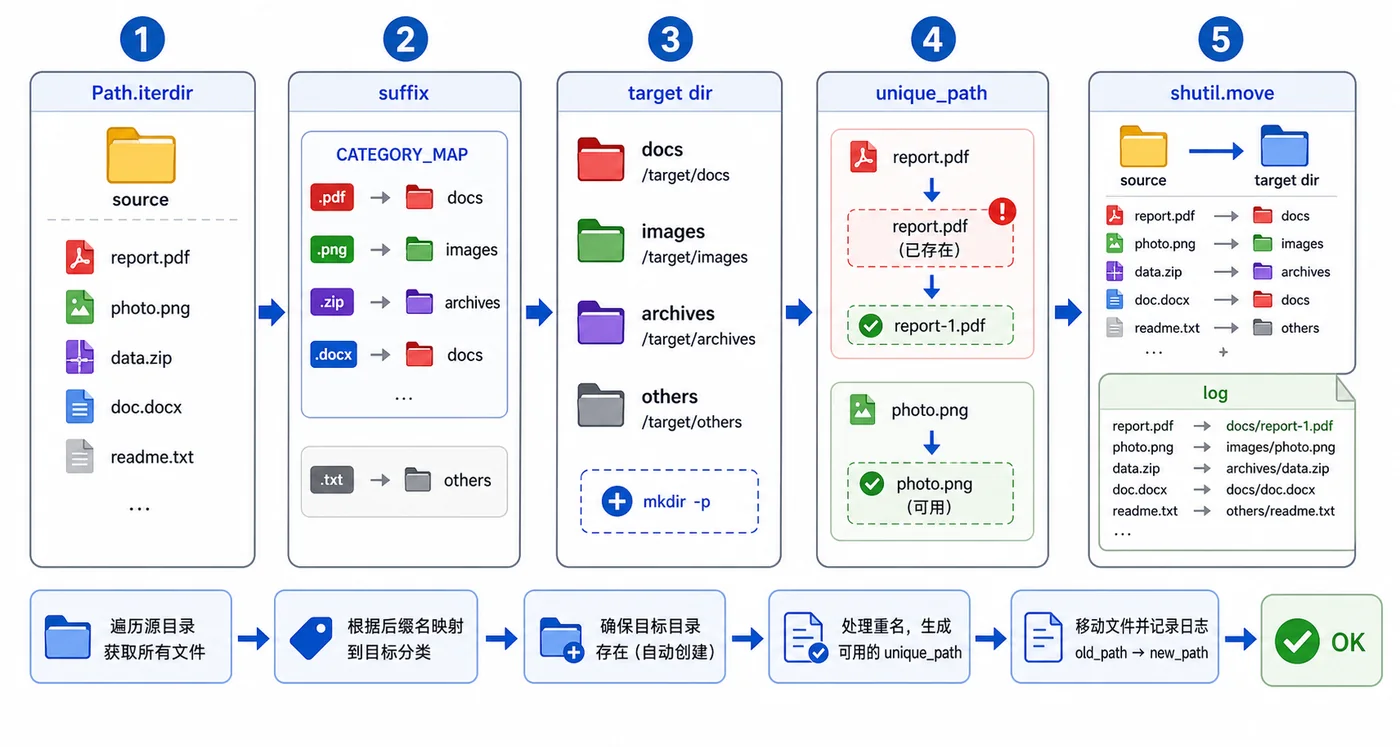
用下载目录整理场景演示 Python pathlib 的实用写法:扫描文件、按扩展名创建分类目录、处理同名冲突、移动文件并记录日志,让批量文件整理脚本更稳。