人工智能技术文章
-
 大模型流式输出不能把每个分片当成完整 JSON。用缓冲区、完成事件、事务与请求幂等键,把半截内容和重试写入挡在数据库之外。186 收藏
大模型流式输出不能把每个分片当成完整 JSON。用缓冲区、完成事件、事务与请求幂等键,把半截内容和重试写入挡在数据库之外。186 收藏 -
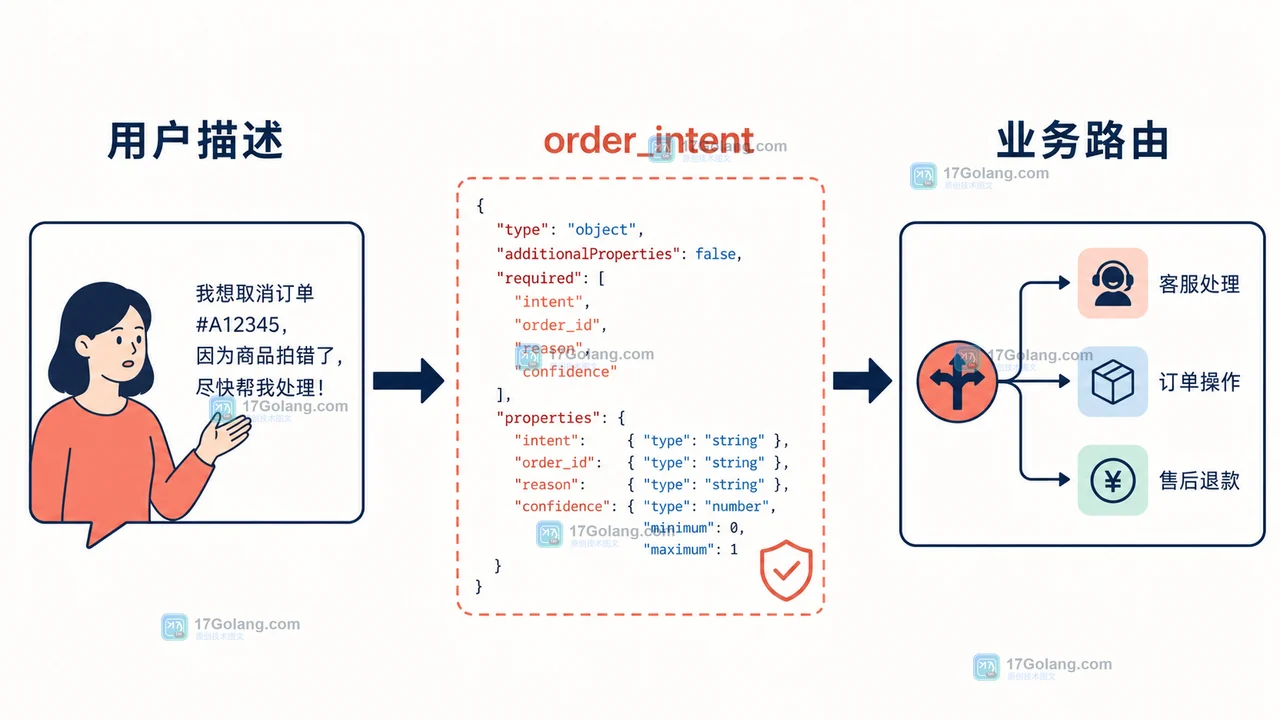 订单咨询一多,最难受的不是模型答得不通顺,而是下游拿到的字段时有时无。用 JSON Schema 约束输出、在服务端再做一次校验,并给拒答和缺字段留出口,能把自然语言解析变成可观察、可验收的业务步骤。333 收藏
订单咨询一多,最难受的不是模型答得不通顺,而是下游拿到的字段时有时无。用 JSON Schema 约束输出、在服务端再做一次校验,并给拒答和缺字段留出口,能把自然语言解析变成可观察、可验收的业务步骤。333 收藏 -
 客服回复提示词改了两句话,结果结构化字段合格率下降,才发现线上没有记录每条回答来自哪个版本。本文用样本对照、灰度比例、输出门禁和请求标识建立可回退的提示词发布流程。419 收藏
客服回复提示词改了两句话,结果结构化字段合格率下降,才发现线上没有记录每条回答来自哪个版本。本文用样本对照、灰度比例、输出门禁和请求标识建立可回退的提示词发布流程。419 收藏 -
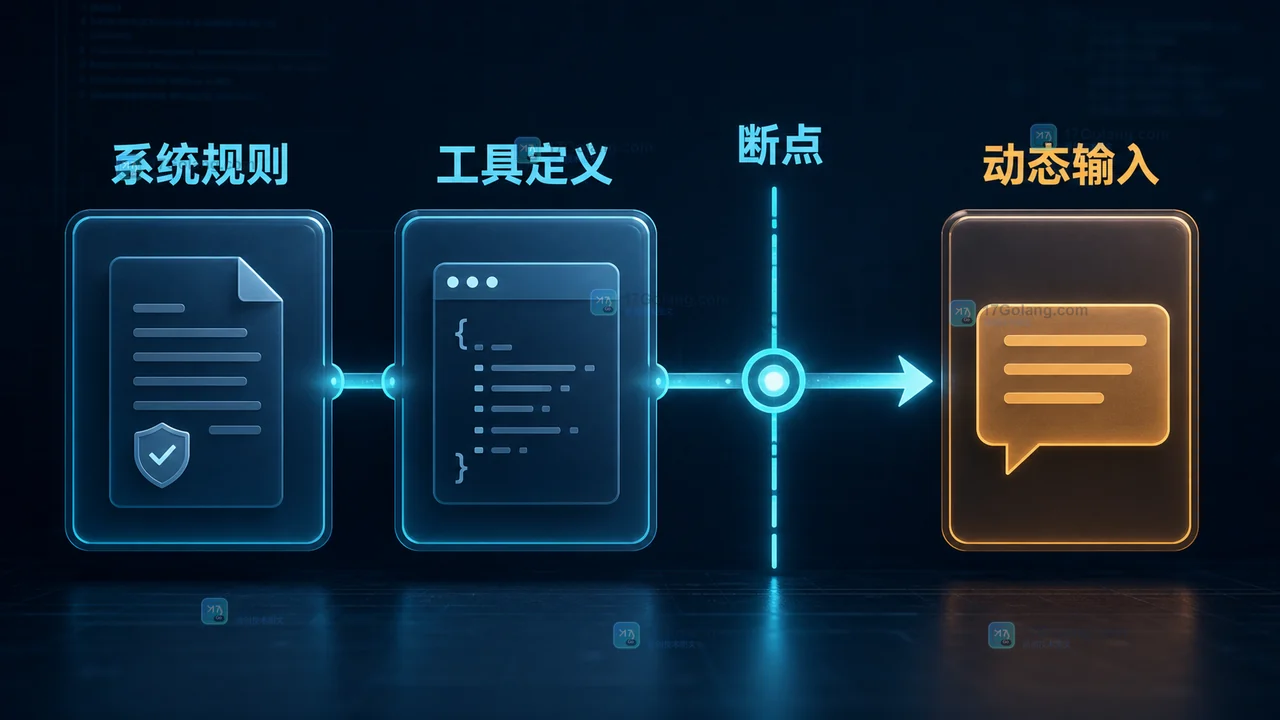 同一套 Claude API 请求看起来没有改,缓存却一直 miss,常见原因不是缓存没打开,而是断点之前混入了动态内容。本文用静态前缀、工具定义和 usage 字段梳理一套最小核对方法。280 收藏
同一套 Claude API 请求看起来没有改,缓存却一直 miss,常见原因不是缓存没打开,而是断点之前混入了动态内容。本文用静态前缀、工具定义和 usage 字段梳理一套最小核对方法。280 收藏 -
科技周边 · 人工智能 | 1天前 | 异步任务 · 人工智能 · jsonl · AI工程化 · Batch API · 结果对账 · JSONL 大模型批量任务 OpenAI Batch API custom_id AI 离线处理 结果对账
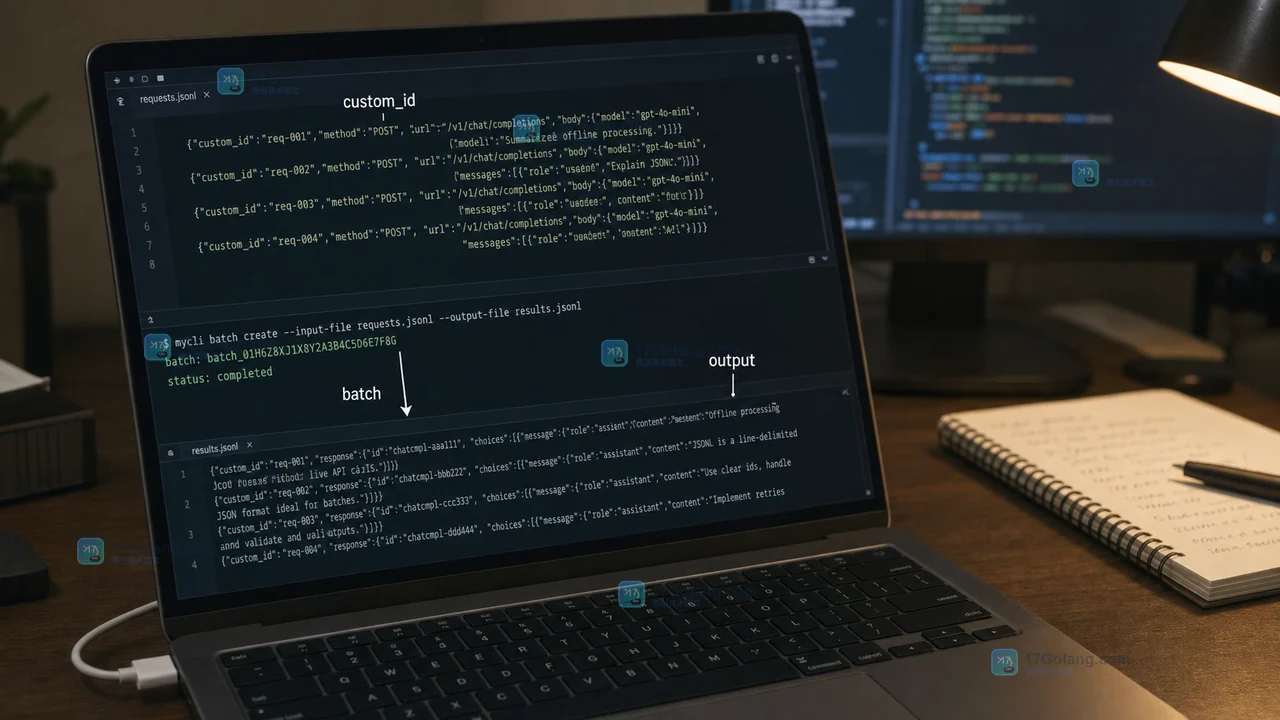 夜间给历史工单打标签、批量生成摘要这类不需要即时返回的工作,不该和在线请求抢同一条队列。本文用一份最小 JSONL 任务说明如何提交异步批次、查看状态、按 custom_id 对齐结果与业务记录,并处理输出文件和错误文件,避免把“批量完成”误当成“每一条都成功”。113 收藏
夜间给历史工单打标签、批量生成摘要这类不需要即时返回的工作,不该和在线请求抢同一条队列。本文用一份最小 JSONL 任务说明如何提交异步批次、查看状态、按 custom_id 对齐结果与业务记录,并处理输出文件和错误文件,避免把“批量完成”误当成“每一条都成功”。113 收藏 -
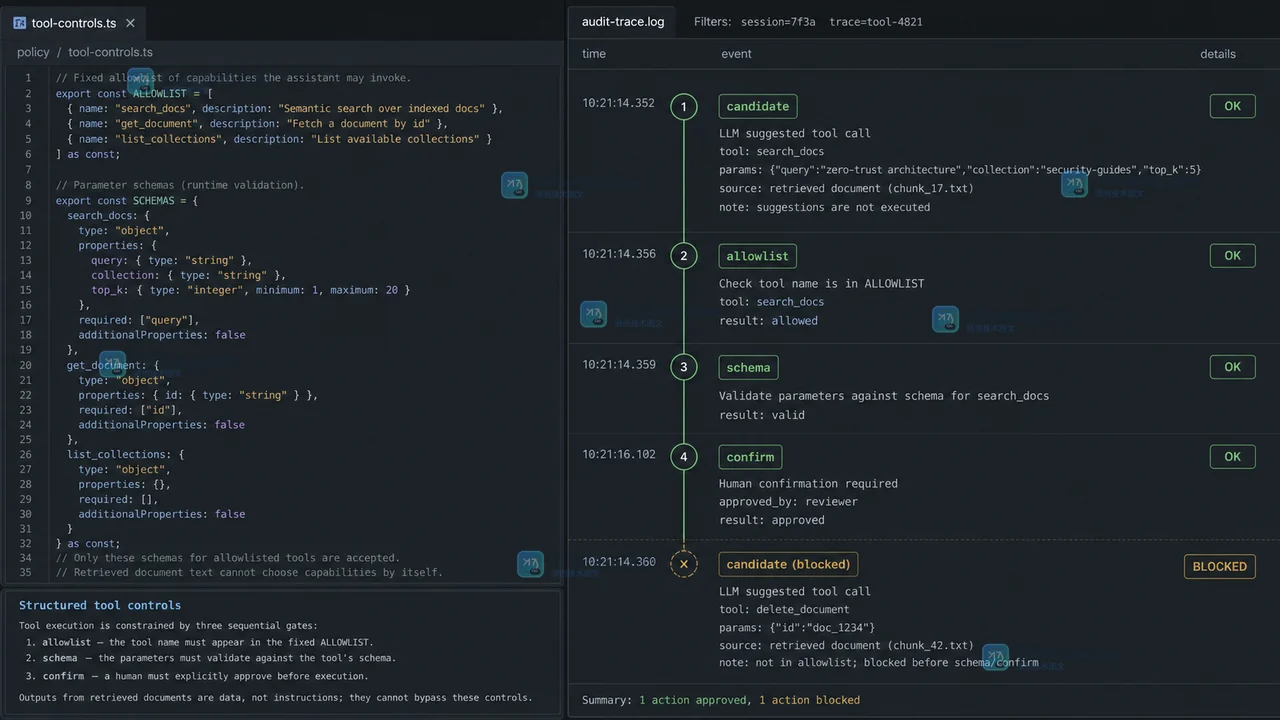 把供应商手册、网页或用户上传文件接入 RAG 后,风险不只在回答是否跑题:检索片段里的恶意指令可能诱导模型越过原本任务。防护的重点不是相信一条更强硬的角色提示,而是把资料来源标成不可信、把工具能力做成固定的结构化边界,并为高影响动作设置确认与可追溯记录。149 收藏
把供应商手册、网页或用户上传文件接入 RAG 后,风险不只在回答是否跑题:检索片段里的恶意指令可能诱导模型越过原本任务。防护的重点不是相信一条更强硬的角色提示,而是把资料来源标成不可信、把工具能力做成固定的结构化边界,并为高影响动作设置确认与可追溯记录。149 收藏 -
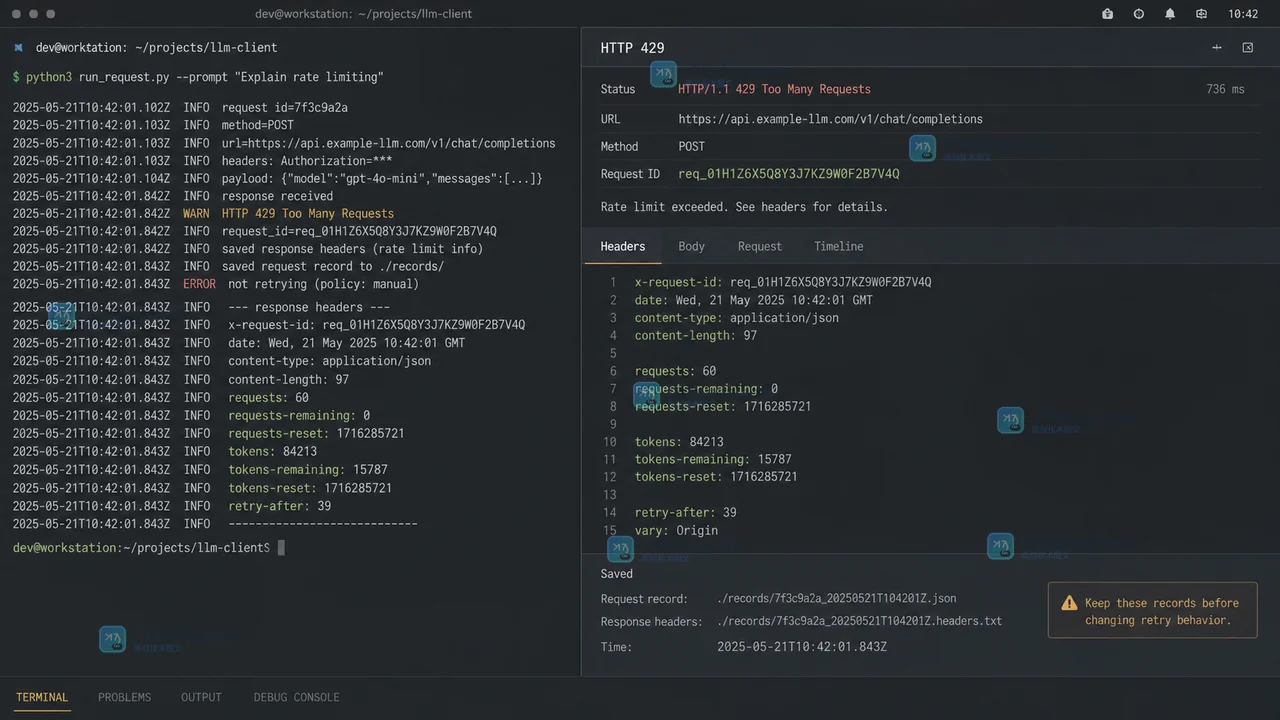 大模型接口出现 429 时,连续立刻再发往往只会让队列更长。本文按运行手册的节奏说明如何保留响应线索,区分请求数量、令牌总量与并发积压三类原因,再用限并发、缩短上下文和带抖动的退避把线上对话从拥塞中拉回来。432 收藏
大模型接口出现 429 时,连续立刻再发往往只会让队列更长。本文按运行手册的节奏说明如何保留响应线索,区分请求数量、令牌总量与并发积压三类原因,再用限并发、缩短上下文和带抖动的退避把线上对话从拥塞中拉回来。432 收藏 -
科技周边 · 人工智能 | 2天前 | 安全 · oauth · 人工智能 · mcp · 工具调用 · MCP 401 MCP 403 MCP OAuth mcp resource_metadata MCP scope MCP token audience
 远程 MCP 服务的工具调用返回 401 或 403,通常不是模型没有找到工具,而是授权发现、scope 或 token audience 没有和目标 MCP 资源对齐。本文按响应状态、WWW-Authenticate、Protected Resource Metadata 和 resource 参数逐步定位,并给出最小核对清单。443 收藏
远程 MCP 服务的工具调用返回 401 或 403,通常不是模型没有找到工具,而是授权发现、scope 或 token audience 没有和目标 MCP 资源对齐。本文按响应状态、WWW-Authenticate、Protected Resource Metadata 和 resource 参数逐步定位,并给出最小核对清单。443 收藏 -
科技周边 · 人工智能 | 3天前 | 前端 · 人工智能 · 用户体验 · 可访问性 · 流式输出 · AI对话 AbortController AbortSignal 流式输出 aria-live 停止生成
 AI 对话的停止按钮不只是调用 abort()。要让用户、键盘操作和辅助技术都获得一致反馈,需要为每次请求新建 AbortController,正确收尾读取循环,并把生成、停止、失败状态放进合适的实时状态区域。425 收藏
AI 对话的停止按钮不只是调用 abort()。要让用户、键盘操作和辅助技术都获得一致反馈,需要为每次请求新建 AbortController,正确收尾读取循环,并把生成、停止、失败状态放进合适的实时状态区域。425 收藏 -
 RAG 应用答错时,不要只怪模型。更常见的根因在检索层:切片不合适、召回证据偏题、排序没过滤、回答没有引用约束。复盘时要把用户问题、检索结果、证据片段、模型回答和评测样本串起来,才能真正防复发。468 收藏
RAG 应用答错时,不要只怪模型。更常见的根因在检索层:切片不合适、召回证据偏题、排序没过滤、回答没有引用约束。复盘时要把用户问题、检索结果、证据片段、模型回答和评测样本串起来,才能真正防复发。468 收藏 -
科技周边 · 人工智能 | 1星期前 | 人工智能 · ai agent · AI应用 · 工具调用 · 权限边界 · 审计链路 · 人工智能 权限控制 AI Agent 工具调用 审批链路 审计回放 上线指标
 AI Agent 真正接入业务系统时,难点不在能不能调用工具,而在权限闸门、人工审批、参数校验、审计回放和上线观察指标是否齐全。先让 Agent 做低风险查询,再逐步放开写入和自动化动作,会比一次性接管业务流程稳得多。343 收藏
AI Agent 真正接入业务系统时,难点不在能不能调用工具,而在权限闸门、人工审批、参数校验、审计回放和上线观察指标是否齐全。先让 Agent 做低风险查询,再逐步放开写入和自动化动作,会比一次性接管业务流程稳得多。343 收藏 -
科技周边 · 人工智能 | 2星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计
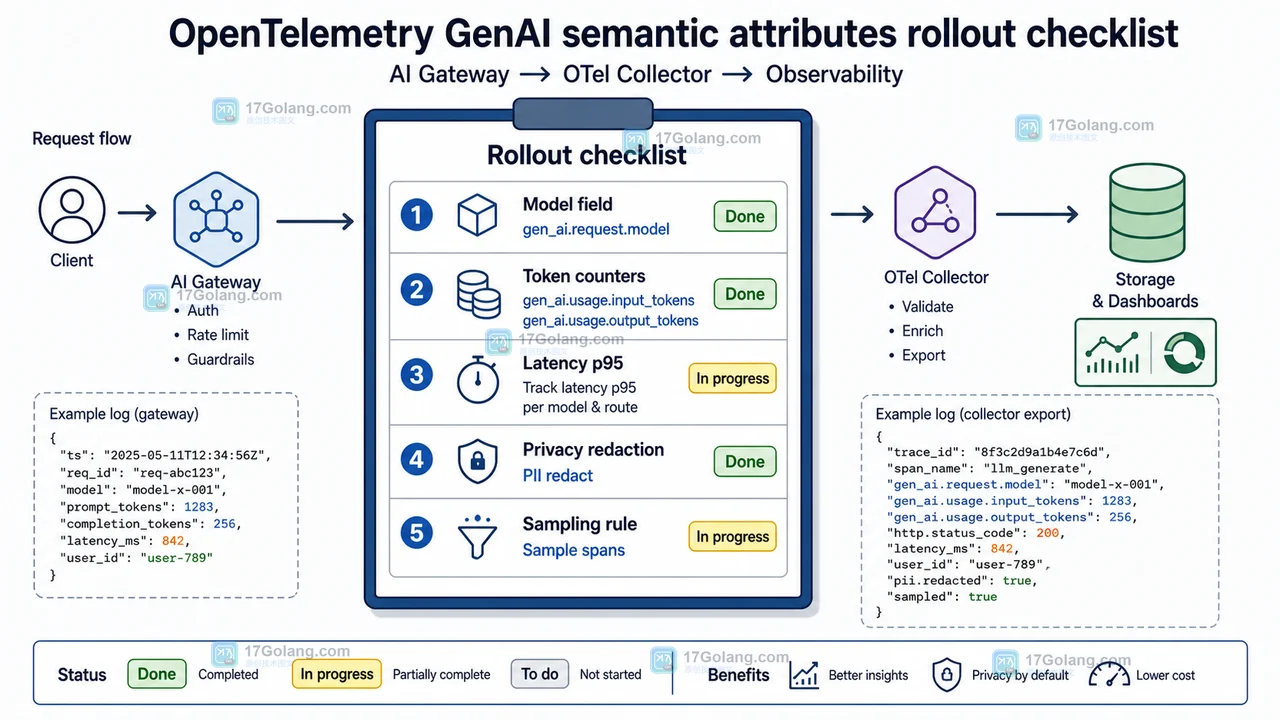 围绕 AI 调用规模化后的日志散乱、模型字段不统一、token 成本不可见和隐私采集风险,讲解如何用 OpenTelemetry GenAI 字段建设统一观测架构。427 收藏
围绕 AI 调用规模化后的日志散乱、模型字段不统一、token 成本不可见和隐私采集风险,讲解如何用 OpenTelemetry GenAI 字段建设统一观测架构。427 收藏 -
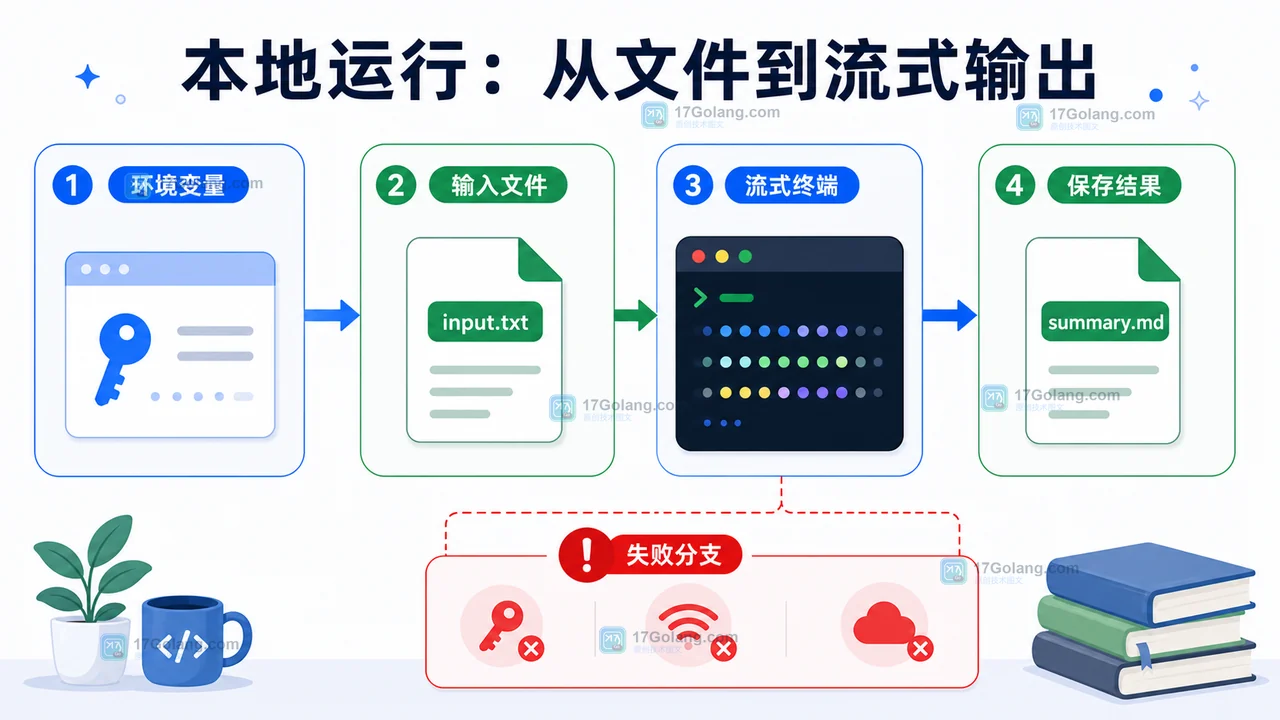 用 DeepSeek API 和 Node.js 从零实现一个命令行流式摘要工具,覆盖环境变量、模型选择、核心代码、本地运行、失败处理和验收清单。154 收藏
用 DeepSeek API 和 Node.js 从零实现一个命令行流式摘要工具,覆盖环境变量、模型选择、核心代码、本地运行、失败处理和验收清单。154 收藏 -
 AI 接口要求返回 JSON,却偶发多字、缺字段或类型不一致。本文从问题现场出发,按提示词、Schema、模型返回、解析层和兜底策略逐步定位,给出更稳的结构化输出落地流程。309 收藏
AI 接口要求返回 JSON,却偶发多字、缺字段或类型不一致。本文从问题现场出发,按提示词、Schema、模型返回、解析层和兜底策略逐步定位,给出更稳的结构化输出落地流程。309 收藏 -
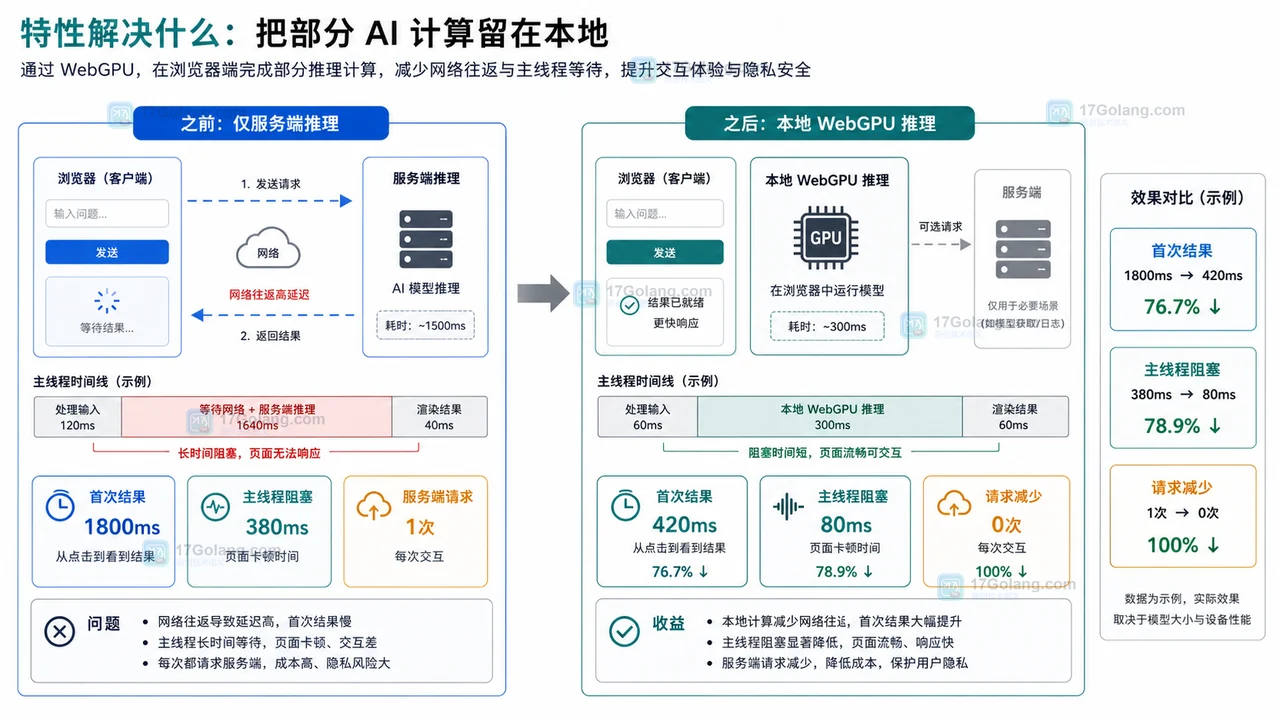 本文说明 WebGPU 在浏览器端 AI 推理中的适用边界:如何检测支持情况,如何写最小可用示例,如何在不可用时降级到服务端或 Web Worker,并给出性能和安全检查点。234 收藏
本文说明 WebGPU 在浏览器端 AI 推理中的适用边界:如何检测支持情况,如何写最小可用示例,如何在不可用时降级到服务端或 Web Worker,并给出性能和安全检查点。234 收藏