-

答案是通过init函数结合反射实现自动注册,核心在于初始化阶段扫描类型、提取标签元信息并绑定构造逻辑。利用Go的init机制,在包导入时自动执行注册,将组件名、构造函数及配置标签存入全局映射表;通过reflect.TypeOf解析结构体字段的tag信息,如config、default等,构建配置schema;运行时用reflect.Value.Call调用工厂函数,传入依赖实例实现动态创建与注入;依赖管理通过类型映射维护,确保类型安全;仅导入的组件才会注册,未import则不参与,保证构建确定性;结合//
-

腾讯朱雀大模型平台入口为https://matrix.tencent.com/ai-detect/,用户可直接访问网页版使用文本与图像检测功能,支持文本粘贴、文档上传及AI生成概率分析。
-

分辨率差异导致画面精细度、文字锐利度及细节表现明显不同:1080P(207万像素)与2K(369万像素)相差约78%,2K与4K(829万像素)相差2.25倍,1080P与4K相差300%。
-
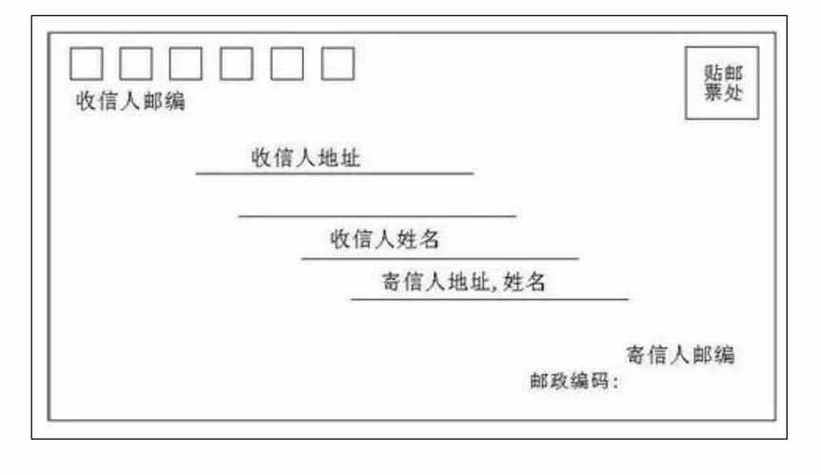
邮编是提高邮件投递效率的关键代码,中国采用六位数字,分别代表省、市、县及投递局,如“100086”中“10”为北京,“00”为中心城区,“8”为海淀区,“6”为投递支局;应正确填写在信封右上角,避免省略或添加符号,并通过官方渠道查询确保准确。
-

余弦相似度适合高维稀疏文本数据。1.通过TF-IDF或CountVectorizer将文本转化为数值向量;2.使用numpy或scipy计算向量间的余弦相似度;3.该方法不依赖文档长度,适用于推荐系统、图像处理、基因分析等场景;4.注意数据预处理、零向量处理及特征工程对结果的影响。
-

本文详细介绍了如何在LaravelEloquent中高效地统计关联模型的特定条件下的数量。通过利用withCount方法及其闭包条件,开发者可以轻松地为每个主模型获取满足特定条件的关联模型计数,避免N+1查询问题,并优化查询性能,从而实现更灵活和精确的数据统计需求。
-

本文详细介绍了在使用FastAPI作为后端API服务、HTMX作为前端增强时,如何解决HTMX直接渲染FastAPI返回的JSON字符串而非其中特定数据的问题。通过引入hx-trigger属性和客户端JavaScript函数,教程演示了如何解析JSON响应、提取所需值并动态更新DOM,从而实现精确的数据展示。
-

本文详细探讨了在Flask模板中迭代处理SQLAlchemy查询结果时,因字符串中隐藏的空白字符导致数据检索不完整的问题。通过分析常见场景,揭示了split(",")操作后可能遗留的空白字符如何影响数据库查询。文章提供了一种简单而有效的解决方案:在模板中使用str.strip()方法清除标签名称的空白,确保SQLAlchemy查询能够准确匹配数据库中的记录,从而实现所有标签的正确显示和样式应用。
-

使用CSS动画结合filter:blur()可实现流畅视觉过渡,如悬停清晰化或淡入效果。通过transition或@keyframes定义模糊到清晰的变化过程,常用于卡片悬停、内容浮现等场景。配合will-change和硬件加速优化性能,避免高值blur在大面积元素滥用,提升交互质感而不影响体验。
-

响应式编程是现代Java业务系统的核心能力,ProjectReactor通过非阻塞、异步和声明式的数据流处理,提升系统吞吐量与资源利用率;其核心类型Flux和Mono结合flatMap、map、zip等操作符,可优雅编排复杂异步逻辑,如用户注册流程中的数据库保存、邮件发送与缓存更新;通过避免block()滥用、合理使用log()调试、管理背压及逐步转变响应式思维,能有效落地于高并发、I/O密集型场景,构建弹性、可伸缩的现代应用。
-

使用logging模块可灵活控制日志级别、输出到多目标、自定义格式并实现集中管理,相比print更专业可控,是Python生产环境必备工具。
-

Go原生net/rpc不支持负载均衡,需结合客户端选节点逻辑与服务端注册发现机制实现;核心是将节点选择前移到客户端,支持轮询、随机、最少连接、加权等策略,并依赖etcd等注册中心实现服务发现与健康探测。
-

Python中使用re.split()可按正则表达式分割字符串1.基本用法:通过定义正则表达式作为分隔符,如re.split(r'\d+',text)可按数字分割字符串2.保留分隔符:利用括号捕获组如re.split(r'(\d+)',text)可将分隔符内容保留在结果中3.多种分隔符:用|组合多个规则或字符类如re.split(r',|\s|:',text)可同时按逗号、空格、冒号分割4.注意事项:需处理分隔符在首尾导致的空字符串问题、考虑性能影响以及正则贪婪匹配可能带来的分割错误。
-

卡片翻转不顺畅的根源在于未开启硬件加速、transition未写在默认状态及perspective位置错误;需为父容器设preserve-3d与perspective,翻转元素加backface-visibility:hidden和will-change:transform,并确保transform-origin:center、结构扁平、使用自然贝塞尔曲线。
-

通过面向接口编程和依赖注入,将具体实现解耦,OrderProcessor依赖NotificationService接口而非具体类,新增SMSNotification等实现无需修改原有代码,提升可维护性与扩展性。