-

编写并部署自动化Redis数据备份脚本的步骤如下:1.使用Python编写脚本,利用redis、os和datetime库进行备份。2.使用cron作业定时执行脚本,或使用Airflow进行更高级的部署。3.实现轮换备份机制,保留最近的N个备份文件以节省存储空间。
-

MySQL的查询缓存已废弃,是否还值得使用取决于版本和业务场景。1.查询缓存可缓存SELECT语句及其结果,提升读多写少场景的性能;2.但一旦表有写入操作,相关缓存会被清空,高并发写入时易引发性能问题;3.MySQL5.7.20开始标记为废弃,8.0彻底移除,建议使用Redis等外部缓存替代;4.启用时需配置query_cache_type和query_cache_size参数,并合理控制内存大小;5.可通过Qcache_hits、Com_select、Qcache_inserts等状态变量判断缓存命中情
-

MySQL备份数据的常用方式包括逻辑备份和物理热备。一、mysqldump是最常见的逻辑备份工具,适合中小型数据库,通过导出SQL文件实现备份与恢复,但恢复速度慢且需停止写入以保证一致性;二、XtraBackup是支持在线备份的物理热备工具,适用于大数据量且不能停机的场景,通过复制数据文件并应用日志确保一致性,但操作较复杂且需权限配置;三、定期自动备份可通过crontab定时执行脚本,结合压缩、保留策略及异地存储提升可靠性;四、其他工具如MySQLEnterpriseBackup支持增量备份与加密,myd
-

Redis通过单线程架构下的原子性操作保证并发安全性,涉及多key或读写操作时可使用事务或Lua脚本确保原子性。1.Pipeline批量操作减少网络往返提升吞吐量;2.Lua脚本在服务端执行复杂逻辑,保障操作原子性;3.数据分片将数据分散存储至多个实例提升性能;4.Redis集群提供自动分片与故障转移增强可用性;5.合理选择数据结构如集合、有序集合优化不同场景性能。可通过监控QPS、延迟、连接数、内存等指标了解运行状态并及时优化。
-

Redis内存占用过高可以通过以下步骤优化:1.设置maxmemory参数控制内存使用量;2.选择合适的内存回收策略,如volatile-lru或allkeys-lru;3.使用EXPIRE命令设置键的过期时间;4.选择合适的数据结构,如使用Hash类型存储小对象;5.调整持久化配置,选择RDB或AOF;6.实施分片(Sharding)技术。这些方法结合使用,可以有效降低Redis的内存占用,提升系统性能。
-

要查看MySQL表结构信息,可通过三种方法实现。1.SHOW语句:执行SHOWCREATETABLEyour_table_name;可查看建表语句,包含字段类型、索引、约束等;执行SHOWCOLUMNSFROMyour_table_name;可查看字段名、类型、是否允许NULL、Key、Default值、Extra信息。2.DESCRIBE语句:执行DESCRIBEusers;或DESCusers;可快速获取字段名、类型、是否允许NULL、Key、Default值、Extra信息,但不显示外键约束。3.i
-

在MySQL中,插入数据的方式分为单条插入和批量插入。1.单条插入适用于需要立即反馈和数据量少的场景,使用INSERTINTO语句实现。2.批量插入适合处理大量数据,方法包括使用INSERTINTO...VALUES语句和LOADDATA语句,后者更高效。3.性能优化建议包括使用事务处理、管理索引和分批处理,以提升批量插入的效率。
-

MySQL能通过分区裁剪和并行查询提升性能。1.分区裁剪使查询仅扫描必要分区,可通过EXPLAIN输出的partitions列确认,若显示具体分区则表示生效;2.并行查询利用多核CPU加速处理,需MySQL8.0+、InnoDB引擎及满足查询类型与资源条件;3.分区裁剪失效常见于无分区键条件、使用函数表达式、OR条件复杂、数据类型不匹配或动态SQL;4.优化并行查询包括设置max_parallel_degree、简化查询、使用索引和定期分析表。
-

HLL在处理大数据量统计时的使用技巧包括:1.合并多个HLL以统计多个数据源的UV;2.定期清理HLL数据以确保统计准确性;3.结合其他数据结构使用以获取更多详情。HLL是一种概率性数据结构,适用于需要近似值而非精确值的统计场景。
-

<p>新手需要掌握MySQL基础命令,因为这些命令是操作数据库的基本工具,帮助理解数据库原理,提高工作效率。具体包括:1.连接MySQL服务器:mysql-uusername-p;2.创建数据库和表:CREATEDATABASEmy_database;USEmy_database;CREATETABLEusers(idINTAUTO_INCREMENTPRIMARYKEY,nameVARCHAR(100)NOTNULL,emailVARCHAR(100)NOTNULLUNIQUE);3.插入数
-

从 MySQL 8.4 直方图统计信息入手,讲清数据分布倾斜如何影响优化器行数估算,以及如何创建、验证和回滚 histogram。
-
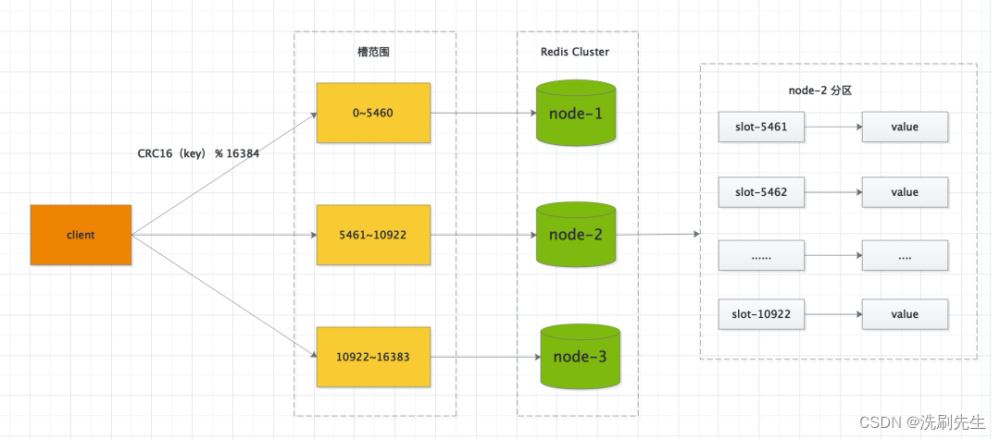
Redis 作为一门主流技术,应用场景非常多,很多大中小厂面试都列为重点考察内容
前几天有星球小伙伴学习时,遇到下面几个问题,来咨询 Tom哥
考虑到这些问题比较高频,工作中经常会遇到,
-

1. JDBC超时设置
connectTimeout:表示等待和MySQL数据库建立socket链接的超时时间,默认值0,表示不设置超时,单位毫秒,建议30000
socketTimeout:表示客户端和MySQL数据库建立socket后,读写socket时的等
-

误区一:过多的数据列
MySQL 存储引擎的 API 是按照行缓冲区方式从服务端和存储引擎复制数据。服务端将缓冲区数据解码成数据列。然而,将行缓冲区的格式转换为数据行数据结构的列可能会
-

这个问题是微信群中网友关于MySQL权限的讨论,有这么一个业务需求(下面是他的原话):
因为MySQL的很多功能都依赖主键,我想用zabbix用户,来监控业务数据库的所有表,是否都建立了主键。