Go语言技术文章
-
数据库 · MySQL | 2天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows
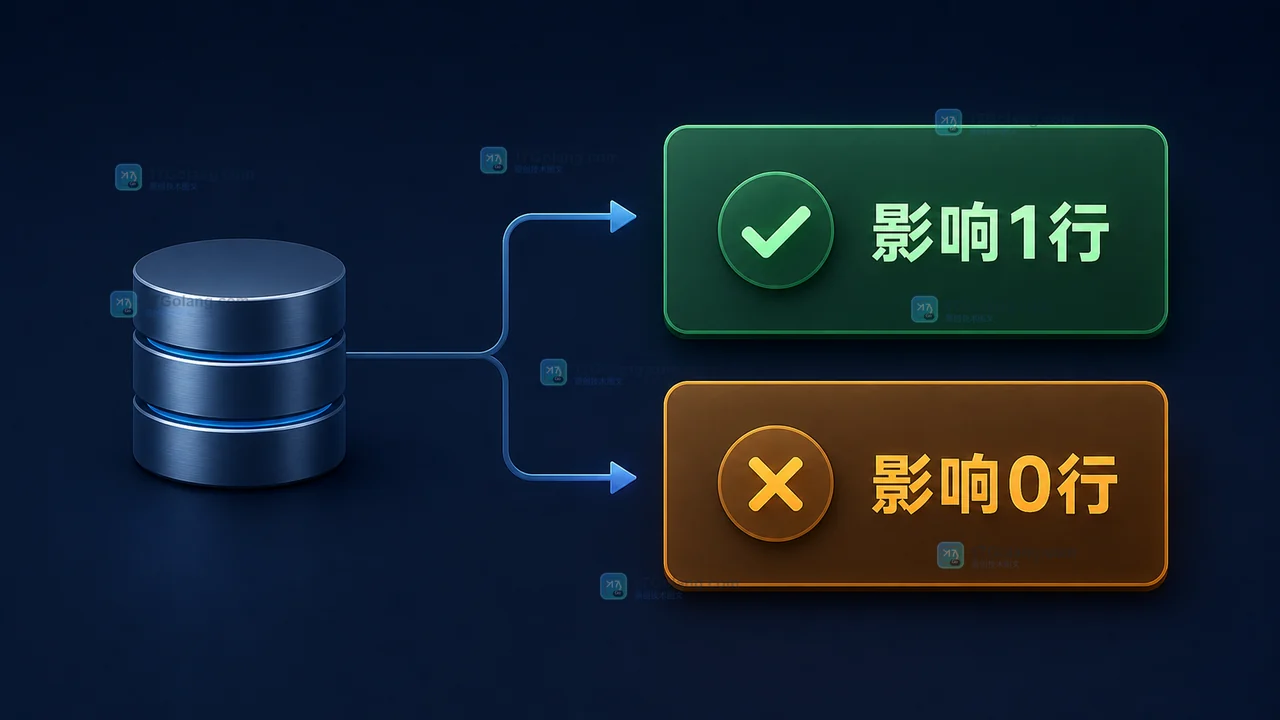 用一条带库存条件的 UPDATE 实现最小扣库存接口,避免先查后改造成超卖;同时说明受影响行、事务边界与死锁重试。470 收藏
用一条带库存条件的 UPDATE 实现最小扣库存接口,避免先查后改造成超卖;同时说明受影响行、事务边界与死锁重试。470 收藏 -
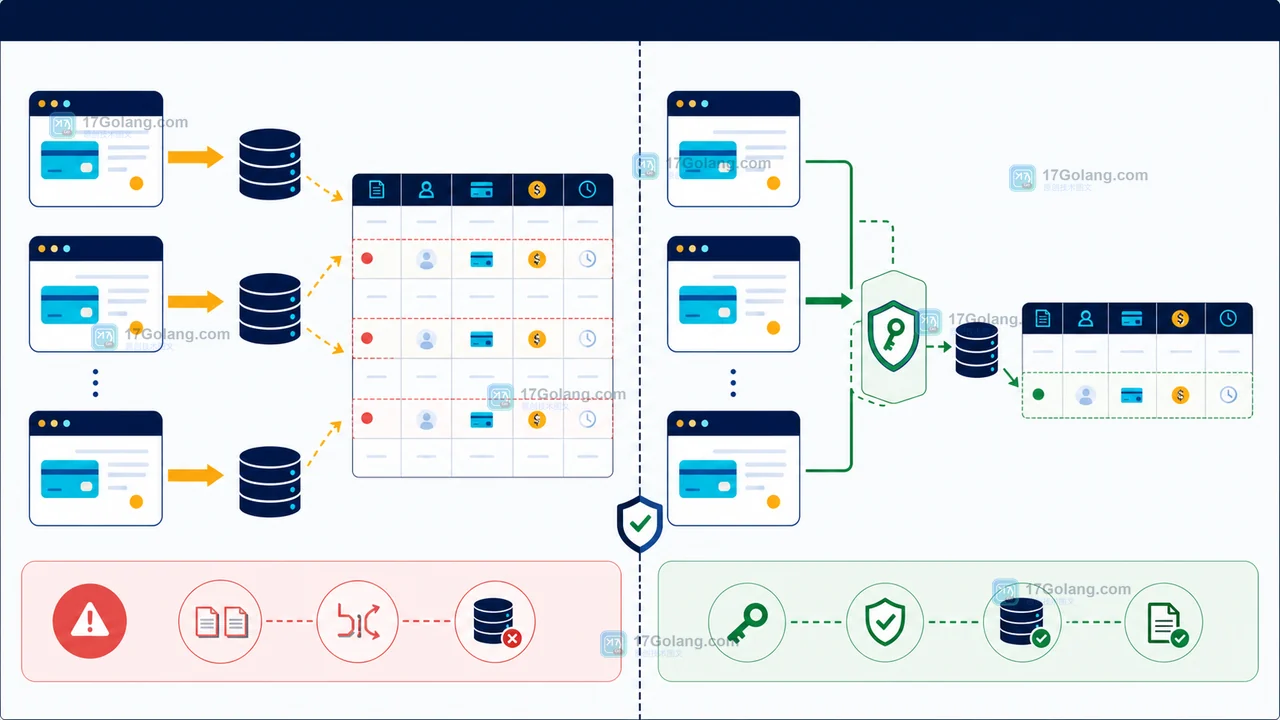 重复点击、网络重试和消息重复投递都会让写入接口面对同一业务请求多次到达。本文说明如何用幂等键和唯一索引建立数据库边界,并比较重复时返回既有结果与更新既有记录的取舍。421 收藏
重复点击、网络重试和消息重复投递都会让写入接口面对同一业务请求多次到达。本文说明如何用幂等键和唯一索引建立数据库边界,并比较重复时返回既有结果与更新既有记录的取舍。421 收藏 -
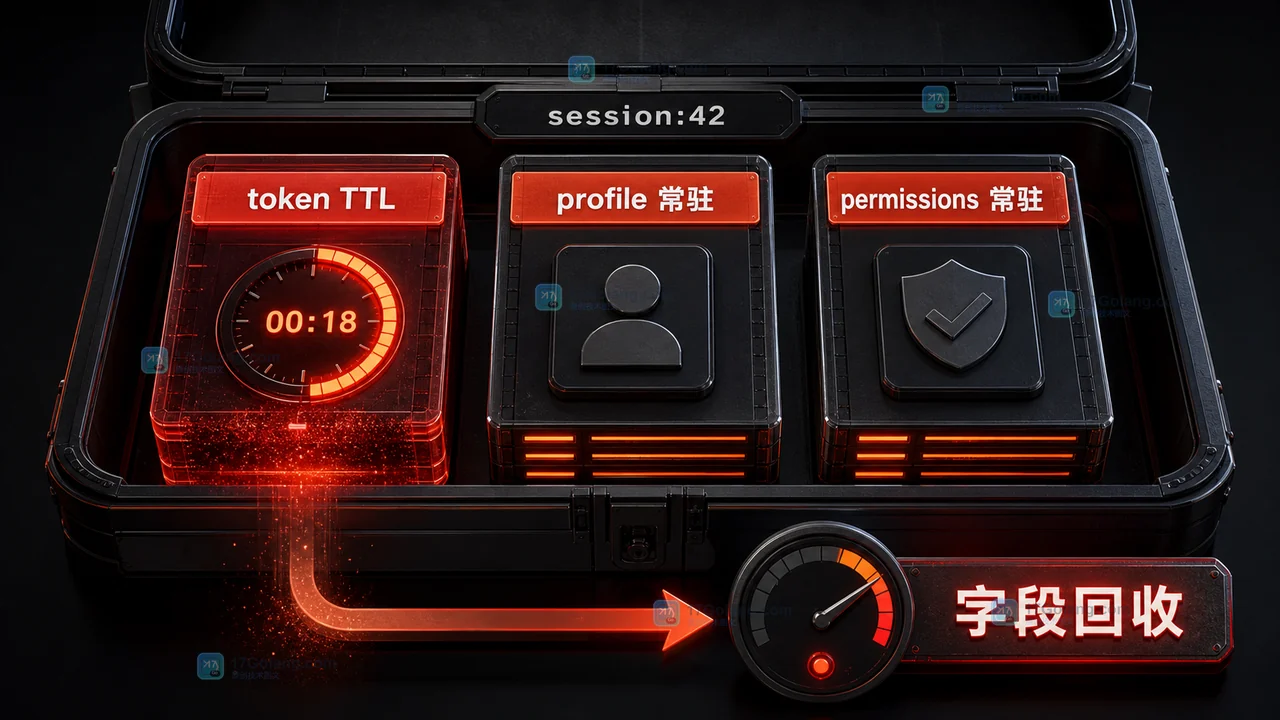 Redis 7.4 起支持给 Hash 的单个字段设置 TTL。本文用会话 token 场景说明 HEXPIRE、HTTL、条件更新和兼容检查,避免为了一个短期字段让整条 Hash 一起过期。366 收藏
Redis 7.4 起支持给 Hash 的单个字段设置 TTL。本文用会话 token 场景说明 HEXPIRE、HTTL、条件更新和兼容检查,避免为了一个短期字段让整条 Hash 一起过期。366 收藏 -
数据库 · Redis | 1天前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计
 Redis 被直接暴露在公网,靠一个密码或 protected-mode 都不够。更稳妥的方案是让端口只对可信应用网络开放,再用 ACL 分配最小命令和 key 权限、启用所需的传输保护并保留配置审计。本文按 Redis 官方安全文档梳理风险和可验证的检查顺序。364 收藏
Redis 被直接暴露在公网,靠一个密码或 protected-mode 都不够。更稳妥的方案是让端口只对可信应用网络开放,再用 ACL 分配最小命令和 key 权限、启用所需的传输保护并保留配置审计。本文按 Redis 官方安全文档梳理风险和可验证的检查顺序。364 收藏 -
数据库 · MySQL | 20小时前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort
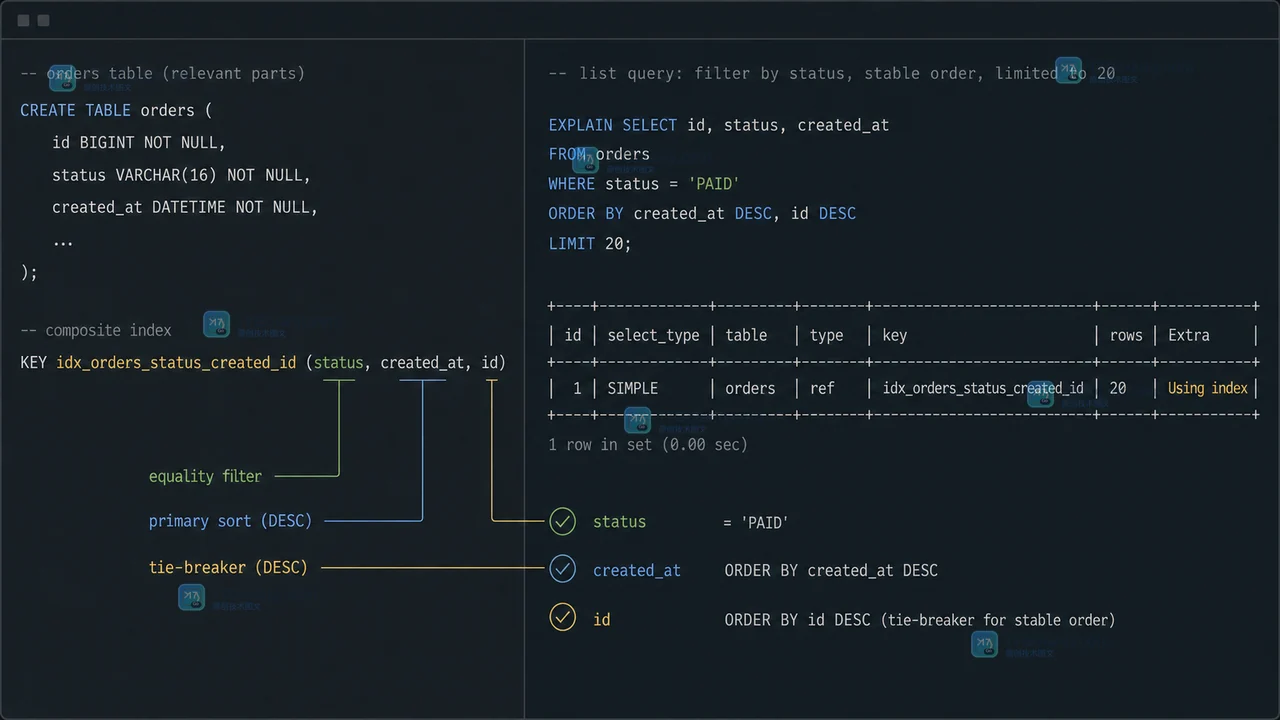 一条只取 20 行的订单查询,EXPLAIN 却可能放弃看似更贴近 WHERE 条件的索引,改走排序索引并在途中筛选。原因是 LIMIT 同时改变了排序、过滤和回表的成本取舍。通过读懂 key、rows 和 Extra,给等值条件与排序字段设计复合索引,再用受控对比核实实际读行,才能避免把 filesort 或某个索引名称当成唯一结论。279 收藏
一条只取 20 行的订单查询,EXPLAIN 却可能放弃看似更贴近 WHERE 条件的索引,改走排序索引并在途中筛选。原因是 LIMIT 同时改变了排序、过滤和回表的成本取舍。通过读懂 key、rows 和 Extra,给等值条件与排序字段设计复合索引,再用受控对比核实实际读行,才能避免把 filesort 或某个索引名称当成唯一结论。279 收藏 -
 Redis 7.0 起,EXPIRE 可用 NX、XX、GT、LT 为过期时间加条件。NX 只给没有 TTL 的 key 首次设置过期,XX 只更新已有 TTL 的 key,GT 只允许延长,LT 只允许缩短。它们互斥;TTL 返回 -1 表示 key 存在但没有过期时间,-2 表示 key 不存在。把条件写清楚,才能避免续期任务意外把缓存窗口改乱。250 收藏
Redis 7.0 起,EXPIRE 可用 NX、XX、GT、LT 为过期时间加条件。NX 只给没有 TTL 的 key 首次设置过期,XX 只更新已有 TTL 的 key,GT 只允许延长,LT 只允许缩短。它们互斥;TTL 返回 -1 表示 key 存在但没有过期时间,-2 表示 key 不存在。把条件写清楚,才能避免续期任务意外把缓存窗口改乱。250 收藏 -
数据库 · MySQL | 54分钟前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT
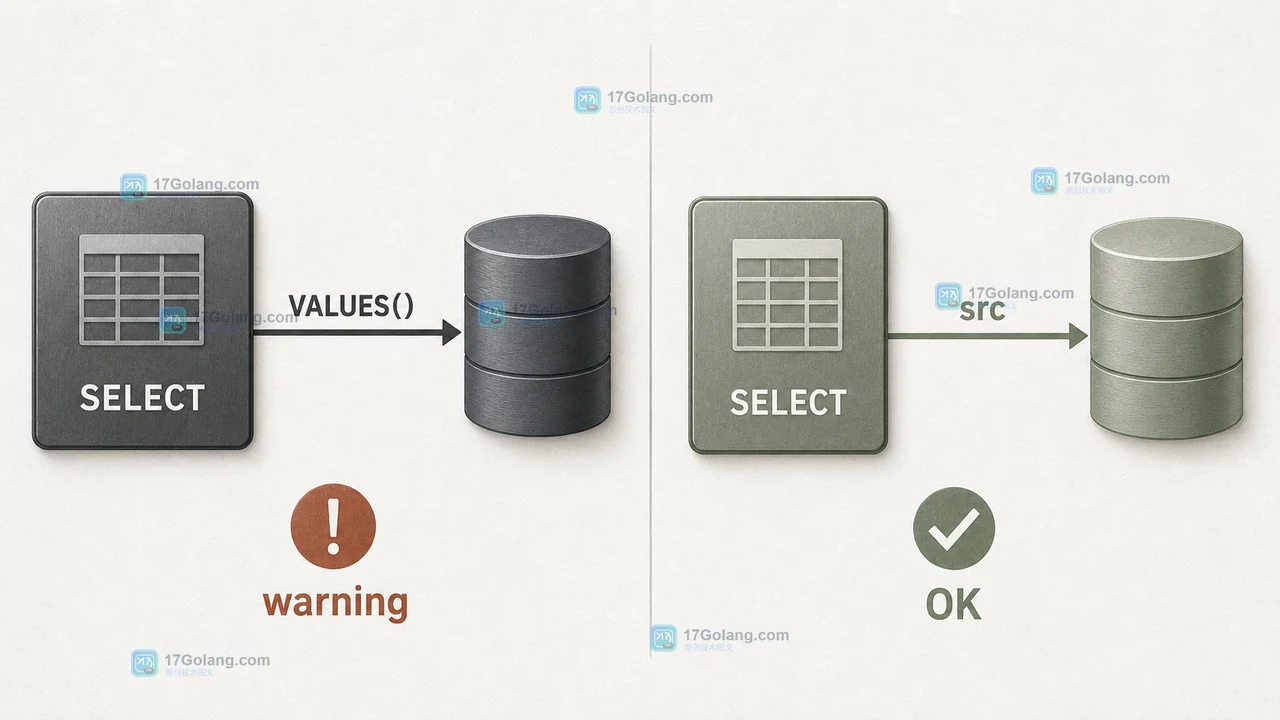 MySQL 已将 ON DUPLICATE KEY UPDATE 中用 VALUES() 读取新行字段的写法标记为弃用。本文从库存快照写入场景出发,给出行别名 AS new 的最小改写、INSERT ... SELECT 的不同处理方式,以及上线前应核对的兼容边界。117 收藏
MySQL 已将 ON DUPLICATE KEY UPDATE 中用 VALUES() 读取新行字段的写法标记为弃用。本文从库存快照写入场景出发,给出行别名 AS new 的最小改写、INSERT ... SELECT 的不同处理方式,以及上线前应核对的兼容边界。117 收藏 -
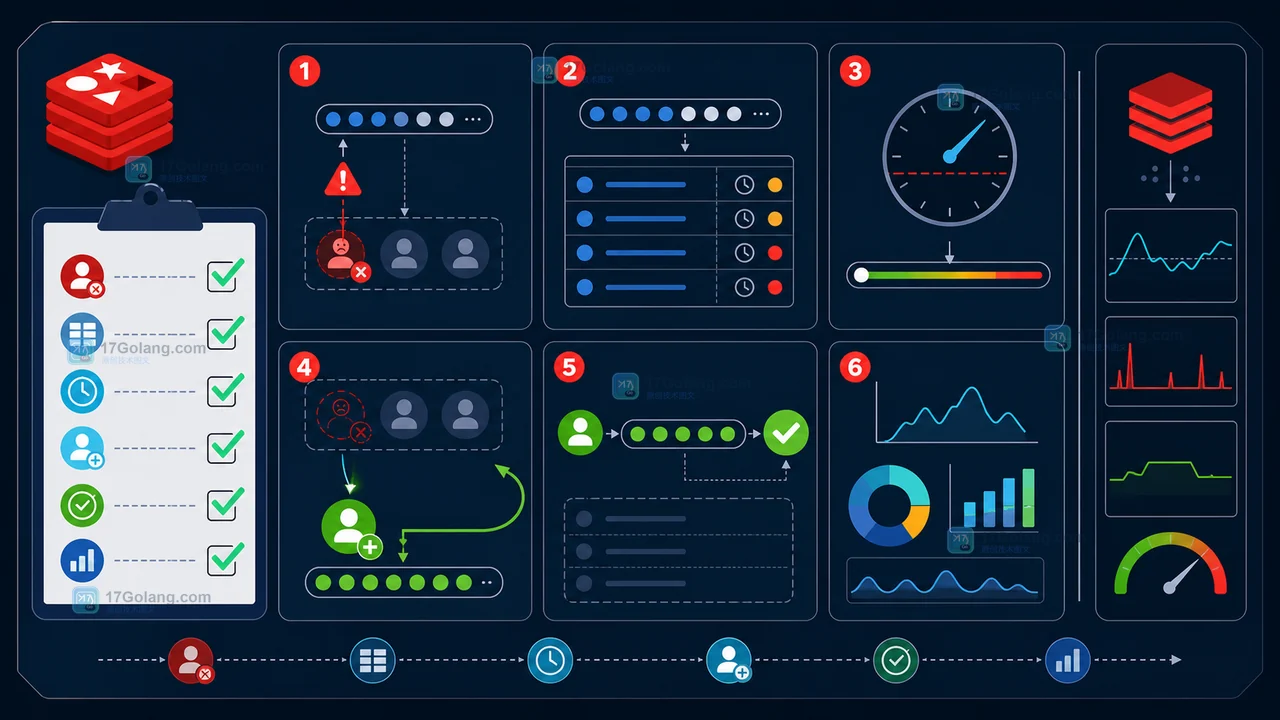 Redis Streams 消费者在确认消息前宕机时,消息会留在待确认列表。本文说明如何通过 XAUTOCLAIM 有节制地接管超时消息,并监控重试与清理结果。110 收藏
Redis Streams 消费者在确认消息前宕机时,消息会留在待确认列表。本文说明如何通过 XAUTOCLAIM 有节制地接管超时消息,并监控重试与清理结果。110 收藏