-

RedisCluster集群的节点规划与部署需要至少3个主节点和建议的3个从节点,确保高可用性和可扩展性。1)节点数量:至少3主3从。2)硬件资源:每个节点至少8GB内存。3)网络拓扑:节点应部署在同一数据中心或低延迟网络。4)部署步骤包括安装Redis、配置Redis、启动节点、创建集群和验证状态。
-

主键和唯一键在MySQL中均用于保证数据唯一性,但存在关键区别。主键必须唯一且非空,每个表仅能有一个主键,并自动创建聚集索引;而唯一键允许NULL值,一个表可有多个唯一键,通常创建非聚集索引。1.主键用于唯一标识记录,不能为空,适合使用自增整数或稳定无业务意义的字段;2.唯一键用于确保字段唯一性,允许空值,适用于用户名、邮箱等场景;3.主键影响数据存储结构,查询效率更高,而唯一键作为二级索引,查询需回表,性能略差。选择时应优先考虑主键的稳定性与简洁性,避免使用易变或复杂格式的字段。
-

Redis的有序集合(SortedSet)非常适合排行榜应用。1)它可以轻松维护有序列表并按分数排序,2)通过简单命令实现数据的插入、更新、查询和删除,3)但在大规模数据下需优化查询性能和处理实时更新,4)需保证数据一致性和完整性。
-

使用布隆过滤器防护缓存穿透是因为它能快速判断元素是否可能存在,拦截不存在的请求,保护数据库。Redis布隆过滤器通过低内存占用高效判断元素存在性,成功拦截无效请求,减轻数据库压力。尽管存在误判率,但这种误判在缓存穿透防护中是可接受的。
-

Redis集群通过主从复制、故障转移和一致性哈希保障数据一致性。优化方法包括:1.调整网络配置,提升网络性能;2.合理的数据分片策略,均衡负载;3.采用读写分离,提升读性能和降低主节点压力。
-

常用的Redis性能监控工具包括Redis自带的INFO命令、慢查询日志、RedisInsight、Prometheus和Grafana组合以及Redis-benchmark。1.INFO命令适合快速诊断问题,但数据粒度较粗。2.慢查询日志有助于优化性能,但配置需谨慎。3.RedisInsight提供直观的监控和分析功能,但需考虑资源消耗。4.Prometheus和Grafana组合适用于大规模集群监控和长期趋势分析,部署复杂。5.Redis-benchmark用于测试性能极限,需结合实际业务场景分析。
-

MySQL值得学习,因为它广泛应用于企业和项目中,能提升数据操作能力和职业竞争力。学习步骤包括:1.创建数据库和表,如CREATEDATABASElibrary_system;CREATETABLEbooks;2.掌握CRUD操作,如INSERT,SELECT,UPDATE,DELETE;3.优化查询性能,使用索引,如CREATEINDEXidx_authorONbooks(author);4.理解事务和锁,保证数据一致性,如STARTTRANSACTION;COMMIT;LOCKTABLES;5.学习高
-

Redis和Elasticsearch组合可以实现数据的高效交互和协同应用。1.Redis用于存储需要实时更新和访问的数据,如电商平台的购物车。2.Elasticsearch用于存储和搜索需要复杂查询和分析的数据,如商品信息。3.通过消息队列如Kafka同步数据,确保两者数据一致性。4.利用Redis发布订阅功能实现数据实时推送和同步。
-

处理MySQL导入SQL文件时,如果没有表被创建或导入失败,可以通过以下步骤解决:1.检查并转换文件格式,使用dos2unix工具;2.确保MySQL用户有足够权限,使用SHOWGRANTSFORCURRENT_USER;命令;3.检查SQL文件中语句顺序,先创建表再插入数据;4.使用mysql命令行工具的--verbose选项查看详细错误信息;5.临时增加max_allowed_packet值,SETGLOBALmax_allowed_packet=10010241024;6.调整SQL模式,SETsq
-

Redis和Elasticsearch组合可以实现数据的高效交互和协同应用。1.Redis用于存储需要实时更新和访问的数据,如电商平台的购物车。2.Elasticsearch用于存储和搜索需要复杂查询和分析的数据,如商品信息。3.通过消息队列如Kafka同步数据,确保两者数据一致性。4.利用Redis发布订阅功能实现数据实时推送和同步。
-

必须分片,因单keyGEOADD底层ZSET会导致查询O(logN+M)延迟、RDB/AOFfork超时、无法水平扩展;应按Geohash前4-5位分key,查时用邻区算法并发查最多9个key并合并去重排序。
-

MySQL单表数据量,建议不要超过2000W行,否则会对性能有较大影响。最近接手了一个项目,单表数据超7000W行,一条简单的查询语句等了50多分钟都没出结果,实在是难受,最终,我们决定用分区
-

事件可以指定单次或以一定的间隔执行 SQL 代码。通常是将复杂的 SQL 语句使用存储过程封装好,然后周期性地调用存储过程完成一定的任务。
事件无需建立服务端连接,而是通过一个独立的事
-
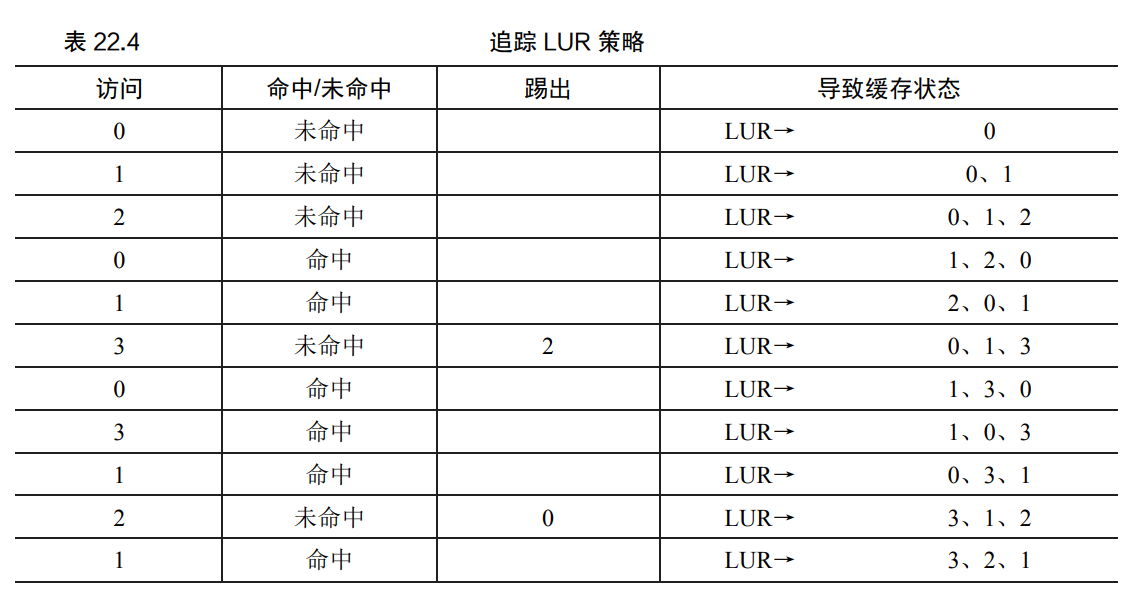
1 概述
在操作系统的页面管理中,内存会维护一部分数据以备进程使用,但是由于内存的大小必然是远远小于硬盘的,当某些进程访问到内存中没有的数据时,必然需要从硬盘中读进内存,所以
-
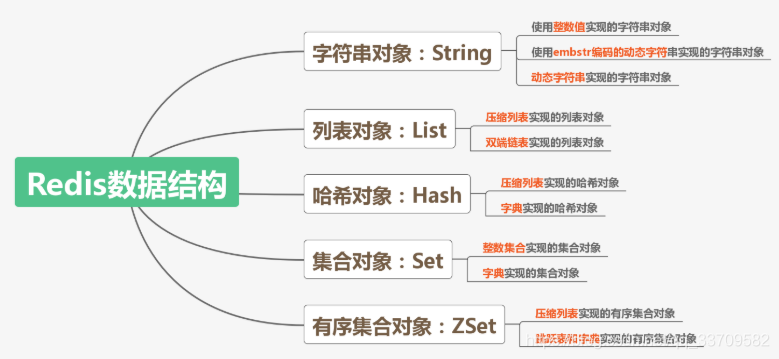
老规矩,先抛结论后验证
string:有点像java的hashMap,存的时候什么key,取的时候也什么key,常用于做缓存,保存用户信息、查询列表等;
hash:这个有点像hashMap的value又套了个hashMap,下文有举