-

要实现的功能是根据用户购买过得商品进行推荐(猜你喜欢)数据库结构:标签表label,商品标签关联表goods_label,商品表goods,商品sku表goods_sku,订单表order,订单商品快照表order_goods实现原理:根
-

最近几天一直在纠结于一个大数据批量导入的问题,经过几天思考,发现基于小数据情况,原本的数据结构设计是没有问题的,但是在大量数据导入,问题就很大了。我之前一直在强调“程序=
-

原文
游标
MySQL检索操作返回一组称为结果集的行。这组返回的行都是与SQL语句相匹配的行(零行或多行)。使用简单的SELECT语句,例如,没有办法得到第一行、下一行或前10行,也不存在每次
-

1.最左前缀原则在MySQL数据库中,联合索引遵守最左前缀原则,联合索引中,在进行数据检索时从索引的最左端开始匹配。联合索引有多个列,对于多列索引,查询过滤条件的字段,必须顺序的包含索引中的字段,一旦跳过某个字段,则索引后面的字段就会失效。如果过滤条件中没有使用联合索引中的第一个字段,则这个索引不会被使用到。#创建联合索引CREATEINDEXidx_name_age_tnameONstudent(`name`,age,tea_name);#执行如下查询,因为过滤条件中有联合索引的name,age因此用到
-

索引定义MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。除了数据
-
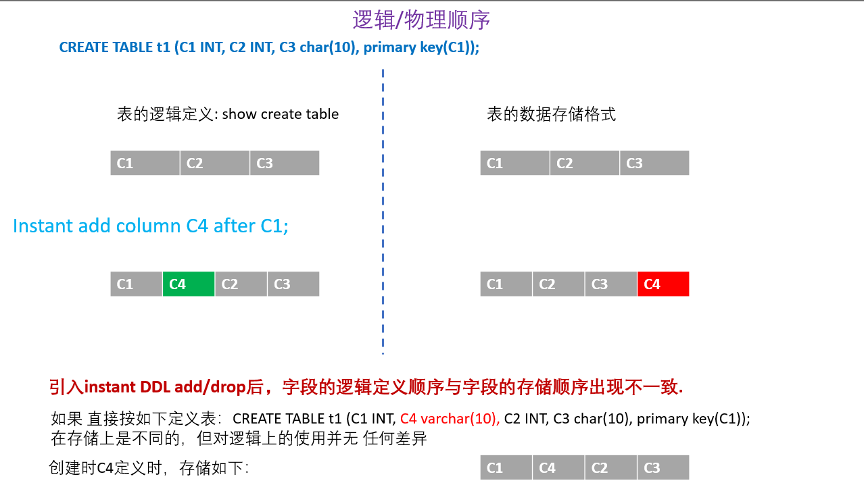
MySQL 8.0.29 引入了 instant add/drop column 功能,支持在任意位置添加 column, drop column 也不需要表数据的任何形式的移动, 只需要修改表的元数据就可以完成 add/drop column,所以 instant add/drop column 的操
-

MySQL数据库和Go语言是两种非常流行的开源技术,它们广泛应用于各种规模的企业和互联网应用中。然而,在大数据时代,如何在MySQL数据库和Go语言中实现数据密度极限成为了一个挑战。本文将介绍如何使用MySQL和Go语言来优化数据密度,从而提高系统的性能和效率。一、MySQL数据库的数据密度优化分区表在MySQL数据库中使用分区表是一种优化数据密度的有效方法
-

如何使用MySQL数据库进行异常检测和修复?引言:MySQL是一个非常常用的关系型数据库管理系统,在各种应用领域都得到了广泛的应用。然而,随着数据量的增大和业务复杂度的提高,数据异常问题也变得越来越常见。本文将介绍如何使用MySQL数据库进行异常检测和修复,以保证数据的完整性和一致性。一、异常检测数据一致性检查数据一致性是保证数据正确性的重要方面。在MySQ
-

实际上,CASE语句具有IF-THEN-ELSE语句的功能。它的语法如下:CASEWHENcondition_1THEN {...statementstoexecutewhencondition_1isTRUE...}[WHENcondition_2THEN {...statementstoexecutewhencondition_2isTRUE...}][WHENcondition_nTHEN {...statementstoexecut
-

为了表示金钱,我们需要使用Decimal(TotalDigitsinteger,DigitsAfterDecimalinteger)方法。假设我们需要显示值345.66。为此,计算有多少位可用。值345.66,一共有5位,小数点后2位,即66。我们可以借助MySQL的Decimal()方法来表示相同的内容。这是准确的表示。DECIMAL(5,2)让我们首先创建一个表,并为我们的示例考虑相同的上述表示-mysql>createtableMoneyRepresentation->(->Mon
-

SQL中MINUS的用法及具体代码示例在SQL中,MINUS是一种用于在两个结果集之间执行差集操作的运算符。它用于从第一个结果集中删除与第二个结果集中相同的行。MINUS操作符返回的结果集将包含仅存在于第一个结果集中的行。下面通过具体的代码示例来演示MINUS的用法:假设有两个表-"table1"和"table2",它们的结构如下:表名:table1字段
-

MySQL查询多个单号的最新状态在给定情况下,需要查询A...
-

Mysql如何分组并行展示查询结果如何在Mysql...
-

如何高效统计一天数据量,分5分钟为一个区间MySQL中,我们经常需要按时间段统计数据量。本文将详细介绍一种...
-

MySQL...