-

Redis的有序集合(SortedSet)非常适合排行榜应用。1)它可以轻松维护有序列表并按分数排序,2)通过简单命令实现数据的插入、更新、查询和删除,3)但在大规模数据下需优化查询性能和处理实时更新,4)需保证数据一致性和完整性。
-

MySQL的REPLACE()函数有三种常见用法:1.字符串替换,将str中的from_str替换为to_str;2.配合UPDATE语句替换字段中的旧值,如修复错别字或错误域名;3.在SELECT查询中临时替换显示结果而不修改原始数据。此外,REPLACE()还可用于清理多余空格或特殊字符,例如嵌套使用清除换行符和回车符。使用时建议添加WHERE条件避免全表更新,减少数据库压力并防止误操作。
-
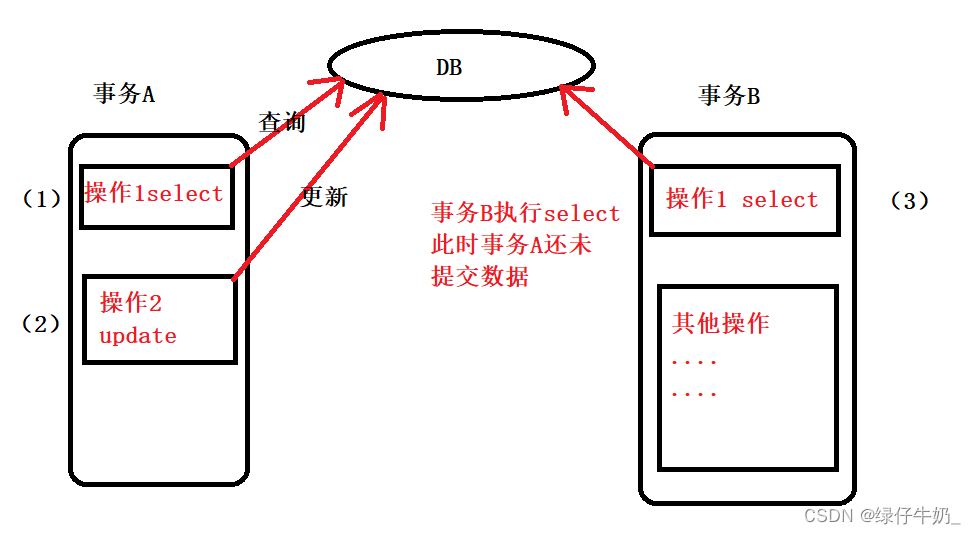
什么是事务
事务就是一组操作的集合,事务将整组操作作为一个整体,共同提交或者共同撤销
这些操作只能同时成功或者同时失败,成功即可提交事务,失败就执行事务回滚
MySQL的事务默认是
-

MySQL中如何表示当前时间?
其实,表达方式还是蛮多的,汇总如下:
Data Type
“Zero” Value
DATE
'0000-00-00'
-

一、数据库设计三范式相关知识说明
1、什么是设计范式?
设计表的依据,按照这三个范式设计出来的表,不会出现数据的冗余。
2、为什么要学习数据库的三个范式?
数据库的设计范式是数据
-
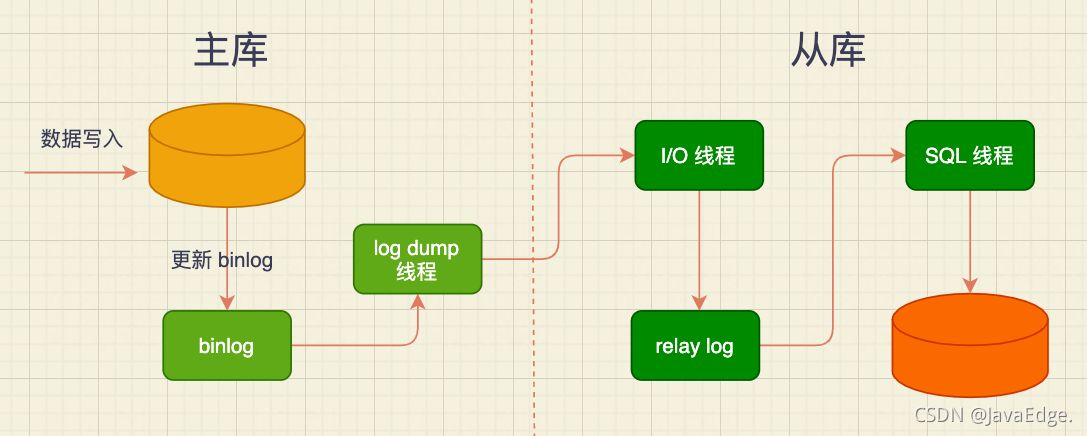
1 主从读写分离
大部分互联网业务都是读多写少,因此优先考虑DB如何支撑更高查询数,首先就需要区分读、写流量,这才方便针对读流量单独扩展,即主从读写分离。
若前端流量突增导致从库
-

前言:
在日常使用数据库的过程中,难免会遇到需要修改账号密码的情景,比如密码太简单需要修改、密码过期需要修改、忘记密码需要修改等。本篇文章将会介绍需要修改密码的场景及修改
-
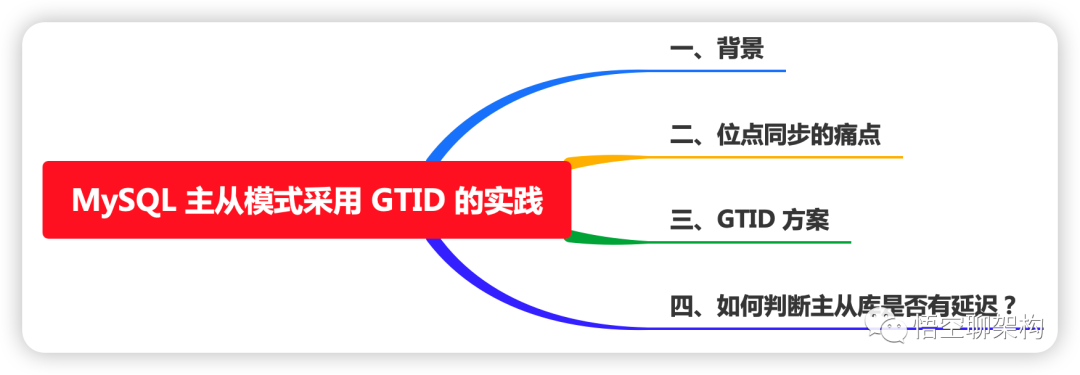
你好,我是悟空。本文主要内容如下:一、背景为了保证高可用,之前在测试环境部署了一套 MySQL 双主模式,当一个主库服务出现异常,可以将流量切到另外一个主库,两个主库之间相互同步
-

全文索引全文索引可以用来查找正文中的中文,只有在mysql 5.7.6之后,才能使用到检索功能,因为在mysql5.7.6之后,加入了中文分词器,比如“今天天气真好!”会被切割为“今天”,“天气”很
-

在InnoDB内存结构中,对每个含有自增长的表都有一个自增长计数器,当进行插入操作时,这个计数器会被初始化,执行如下语句得到计数器的值:select max(auto_inc_col) from t for update插入操作会依据
-

mysql 静默恢复备份文件步骤如下:1、新建一个 mysql -uroot -proot -hlocalhost --database=db1 < db1.sql2、回到终端执行:nohup sh mysqlimport.sh &脚本便会切换到后台执行导入,此时可以使用 tail -f nohup.log
-
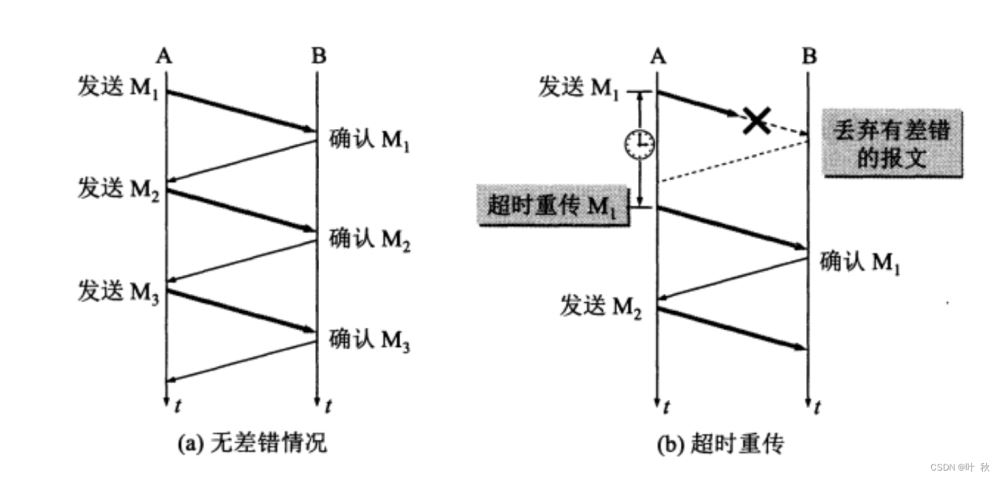
如何在redis中防止消息丢失
前言
在项目中,由于网络问题,我们很难保证生产者发送的消息能100%到达消息队列服务器,也就是说有消息丢失的可能性,因 此,生产者就必须具有消息丢失检测和
-

参考:Specifying limit and offset in Django QuerySet wont work-StackOverflowdjango官方文档Use a subset of Python’s array-slicing syntax to limit your QuerySet to a certain number of results. This is the equivalent of SQL’s LIMIT and OFFSET clau
-

下载MariaDB数据库测试: 当前虚拟机是否可以正确的链接外网.命令:[root@localhost src]# yum install mariadb-server 安装mariadb数据库
[root@localhost src]# yum clean all 清空已安装文件 如果下载失败之
-

摘要:墨天轮数据库周刊第19期发布啦,每周1次推送本周数据库相关热门资讯、精选文章、干货文档。本周分享GBASE适配鲲鹏; 疫情激活COBOL语言;TiDB数据库的未来;Oracle与double write;MySQL8.0 窗