-

PHP+MySQL:读取用户收藏内容在一个网站的“用户收藏”功能中,需要从三个数据表中读取用户收藏的文章或商品...
-

GORm数据库操作中的“未知列”异常在使用GORm时,有时会遇到“Error1054(42S22):Unknowncolumn'created_at'in'field...
-
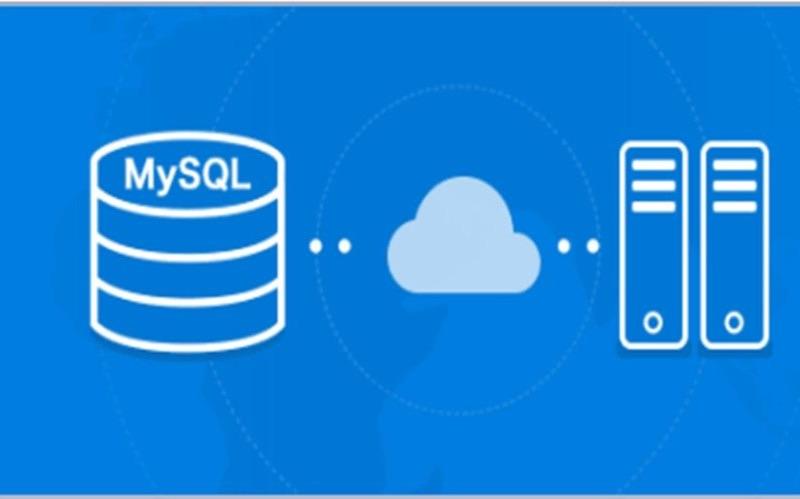
MySQL远程连接:从入门到放弃(误)再到精通很多朋友在安装完MySQL后,都会遇到远程连接的问题。这篇文章不是教你简单的“如何连接”,而是深入探讨这个看似简单的问题背后隐藏的那些坑,以及如何优雅地解决它们,最终达到“精通”的境界(当然,精通是个持续学习的过程)。目的:让你彻底理解MySQL远程连接的原理,并掌握各种场景下的最佳实践,避免掉进常见的陷阱。读完这篇文章,你将能独立解决各种远程连接难题,甚至能对MySQL的安全配置有更深入的理解。概览:我们会从MySQL的配置入手,
-

本文介绍了使用Python脚本强化密码策略并定期更换密码的方法。步骤如下:1.使用Python的random和string模块生成符合复杂度要求的随机密码;2.使用subprocess模块调用系统命令(如Linux的passwd命令)更改密码,避免直接硬编码密码;3.使用crontab或任务计划程序定期执行脚本。该脚本需谨慎处理错误并添加日志,定期更新以应对安全漏洞,多层次安全防护才能保障系统安全。
-

Redis和RabbitMQ在性能和联合应用场景中各有优势。1.Redis在数据读写上表现出色,延迟低至微秒级,适合高并发场景。2.RabbitMQ专注于消息传递,延迟在毫秒级,支持多队列和消费者模型。3.联合应用中,Redis可用于数据存储,RabbitMQ处理异步任务,提升系统响应速度和可靠性。
-

如何在MySQL中创建数据库并设置不同的字符集编码?使用CREATEDATABASE命令并指定CHARACTERSET和COLLATE选项即可。1)创建命令示例:CREATEDATABASEmydbCHARACTERSETutf8mb4COLLATEutf8mb4_unicode_ci。2)选择utf8mb4支持扩展字符。3)对于日文数据,可用utf8和utf8_bin排序规则:CREATEDATABASEjpdbCHARACTERSETutf8COLLATEutf8_bin。
-

存储过程是一组预编译的SQL语句集合,适合封装频繁执行且逻辑复杂的数据库操作。1.它能减少网络传输,提升性能和代码复用性;2.支持输入、输出及双向参数,适用于事务处理、批量插入、复杂查询等场景;3.创建时需修改结束符并使用BEGIN...END包裹逻辑;4.调用时通过CALL语句传参执行;5.优势包括提升安全性、统一业务逻辑、优化性能;6.常用于数据清洗、报表生成、流程事务及定时任务;7.使用时需注意调试困难、版本控制不便、迁移成本高及过度依赖问题;8.建议将核心一致性逻辑放在存储过程中,而复杂逻辑保留在
-

检测和优化Redis的网络带宽瓶颈可以通过以下步骤:1.使用INFO命令监控网络流量,计算每分钟的输入输出字节数;2.使用PING命令测量延迟;3.优化方法包括启用数据压缩、使用批量操作、优化网络配置、数据分片和使用Redis协议优化。通过这些措施,可以有效提升Redis的性能。
-

MySQL中常见的Join类型包括INNERJOIN、LEFTJOIN、RIGHTJOIN和CROSSJOIN,INNERJOIN性能最佳。INNERJOIN返回两表匹配行,LEFTJOIN返回左表全部记录,RIGHTJOIN返回右表全部记录,CROSSJOIN返回笛卡尔积。Join查询慢的原因主要有:缺少索引导致全表扫描、字段类型不一致无法使用索引、表数据量过大、Join层级或字段过多、驱动表选择不合理。优化方法包括:1.为Join字段加索引,尤其是主键和外键;2.控制Join规模,提前过滤减少数据量;
-

内存淘汰不会触发invalidation消息,因其是后台异步驱逐,不走命令执行路径,tracking模块无法感知;只有DEL、SET、EXPIRE等显式变更命令才会触发。
-

EXPLAIN:查看SQL语句的执行计划
EXPLAIN命令可以帮助我们深入了解MySQL基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采
-

在之前的博客中,我写了一系列的文章,比较系统的学习了 MySQL 的事务、隔离级别、加锁流程以及死锁,我自认为对常见 SQL 语句的加锁原理已经掌握的足够了,但看到热心网友在评论中提出
-
锁分类
MySQL的中锁按照范围主要分为表锁、行锁和页面锁。其中myisam存储引擎只支持表锁,InnoDB不仅仅支持行锁,在一定程度上也支持表锁。按照行为可以分为共享锁(读锁)、排他锁(写锁)和意
-
前言:在数据库开发过程中我们经常会使用分页,核心技术是使用用limit start, count分页语句进行数据的读取。
一、MySQL分页起点越大查询速度越慢
直接用limit start, count分页语句,表示从第st
-

一 前言
在Redis的使用过程中,我们经常会遇到BigKey(下文将其称为“大key”)及HotKey(下文将其称为“热key”)。大Key与热Key如果未能及时发现并进行处理,很可能会使服务性