-

使用Redis实现排行榜的核心方案是SortedSet,因为它能自动按分数排序并支持高效范围查询。SortedSet添加、删除、更新元素的时间复杂度为O(logN),获取排名或范围数据同样高效;它支持升序和降序排列,但分数必须为数字,且大数据量可能占用较多内存。其他方案包括List结合手动排序,效率较低;或Hash配合脚本排序,较为复杂。优化性能的方法包括合理设置过期时间、使用pipeline批量操作、避免一次性获取大量数据、监控Redis性能指标,以及采用Redis集群提升并发能力。
-

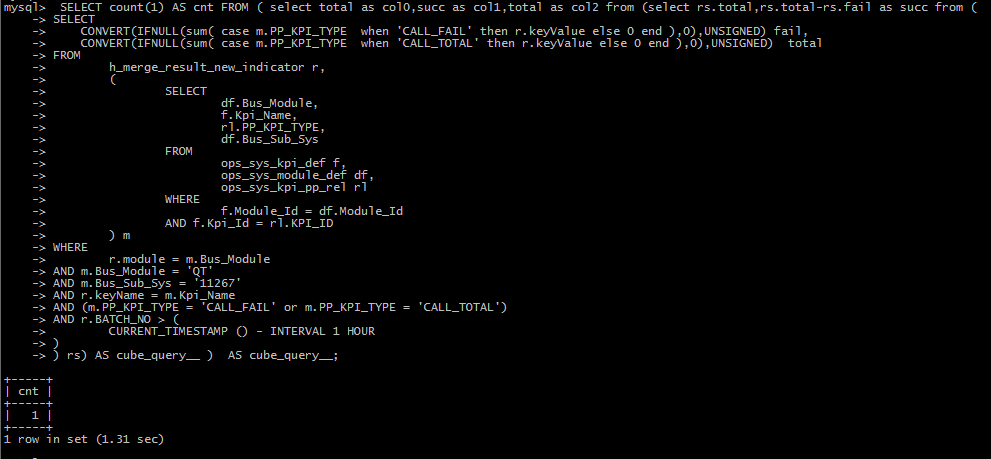
MySQL中可通过PerformanceSchema、SHOWENGINEINNODBSTATUS、pt-deadlock-logger、慢查询日志等工具查看锁竞争情况。1.启用PerformanceSchema需先检查并更新setup_instruments和setup_consumers中的锁相关配置,再通过events_waits_summary_global_by_event_name和events_waits_current表查看锁等待统计和当前事件;2.SHOWENGINEINNODBSTAT
-

MySQL中常见的Join类型包括INNERJOIN、LEFTJOIN、RIGHTJOIN和CROSSJOIN,INNERJOIN性能最佳。INNERJOIN返回两表匹配行,LEFTJOIN返回左表全部记录,RIGHTJOIN返回右表全部记录,CROSSJOIN返回笛卡尔积。Join查询慢的原因主要有:缺少索引导致全表扫描、字段类型不一致无法使用索引、表数据量过大、Join层级或字段过多、驱动表选择不合理。优化方法包括:1.为Join字段加索引,尤其是主键和外键;2.控制Join规模,提前过滤减少数据量;
-

Redis列表在消息队列中的应用可以通过以下优化措施提升性能和可靠性:1.启用持久化机制(AOF或RDB)确保消息不丢失;2.使用BRPOP命令提高消费者的响应性和降低系统负载;3.通过多个列表模拟优先级队列处理不同优先级的消息;4.设置键的过期时间或在消息中加入时间戳管理消息的生命周期;5.利用批量操作减少网络开销,提升系统性能。
-

不能直接用@Primary切换Redis数据源,因其仅指定启动时默认Bean,无法运行时动态路由;需用ThreadLocal持有当前线程的ConnectionFactory,并配合AOP在方法级按需绑定与清理。
-

主从同步断开时repl-backlog溢出会导致全量同步反复触发;需根据写入速率与最大重连时间估算合理大小,动态调整后须同步更新配置文件。
-

这是不需要改源码的方式//user表样例类
case class User1(id: Long, name: String, password: String, imgUrl: String, update_date: String)
object SparkSQLUpdateMySQLOfJDBC {
def main(args: Array[String]): Unit = {
//SparkSession
val s
-

在MySQL通过UPDATE语句更新数据表中的数据。在此,我们将就用六中的student学生表 1. UPDATE基本语法 UPDATE 表名 SET 字段名1=值1[,字段名2 =值2,…] [WHERE 条件表达式]; 在该
-
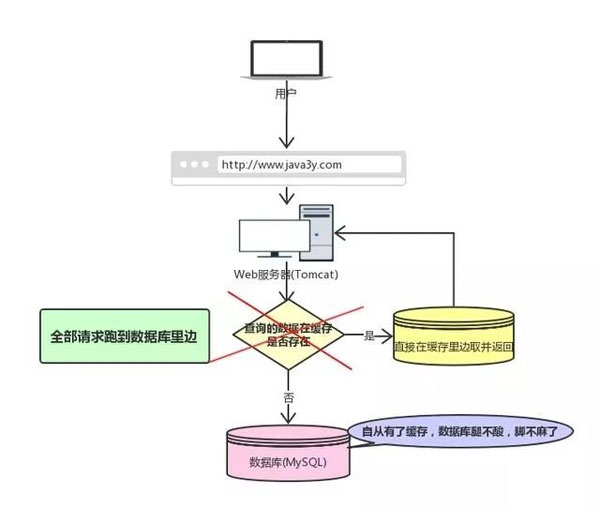
随着系统访问量的提高,复杂度的提升,响应性能成为一个重点的关注点。而缓存的使用成为一个重点。redis 作为缓存中间件的一个佼佼者,成为了面试必问项目。本文分享一下Redis几道常见的
-
索性失效前提
MySQL中我们知道有:
1、如果对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。2、隐式类型转换也会导致同样的放弃走树搜索。
因为类
-
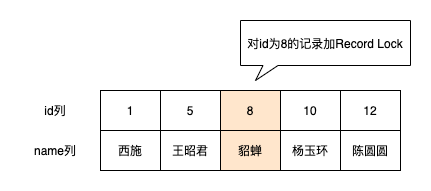
并发场景
最近做了一些分布式事务的项目,对事务的隔离性有了更深的认识,后续写文章聊分布式事务。今天就复盘一下单机事务的隔离性是如何实现的?
隔离的本质就是控制并发,如果SQL语
-

细枝末节/* 从指定表中按条件查询指定字段信息 */
SELECT
字段名
FROM
表名
WHERE
条件执行顺序SELECT
name
FROM
mytable
WHERE
id > 10;查询age小于30的用户idSELECT
id
FROM
mytable
WHERE
a
-
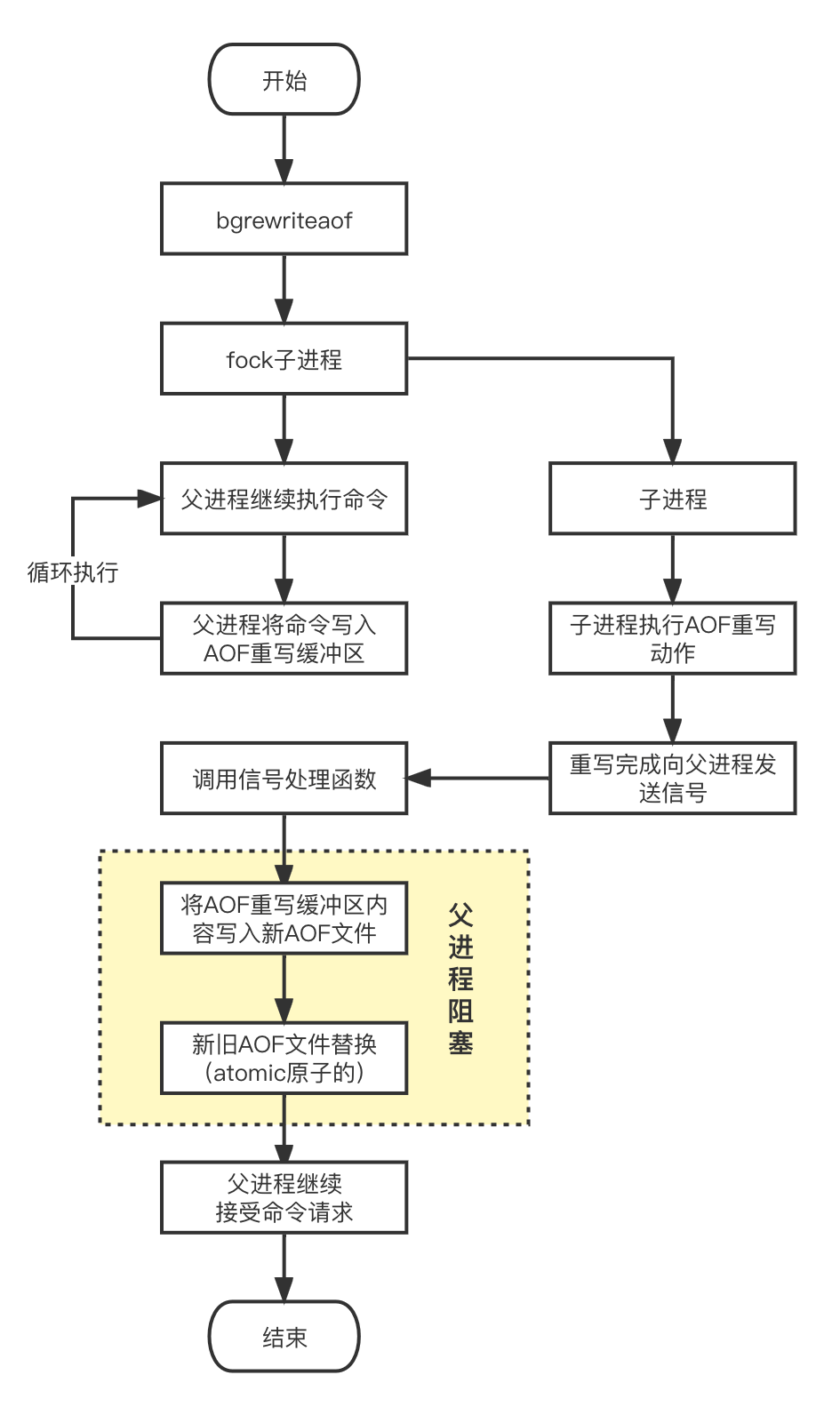
1.RDB持久化
首先,RDB持久化方式会产生一个经过压缩的二进制文件,Redis服务器在启动之初,通过这个文件可以还原数据库的状态。那么我们接下来看下RDB文件是如何实现保存和载入的。
1.1
-

此后会针对数据库索引出一系列的文章,敬请期待前言—学习索引几大理由高薪程序员必备知识,无论去哪里面试,数据库的索引优化是必考知识工作必备,无论任何系统都要和数据库打交道,
-

通过 Spring 框架如何进行JDBC操作呢?[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nUiCZnSc-1600675300070)(https://imgkr.cn-bj.ufileos.c...]Spring 整合 JDBC 的方式添加依赖编写配