-

MySQL性能优化需从安装配置、索引及查询优化、监控与调优三个方面入手。1.安装后需根据服务器配置调整my.cnf文件,例如innodb_buffer_pool_size参数,并关闭query_cache_size;2.创建合适的索引,避免索引过多,并优化查询语句,例如使用EXPLAIN命令分析执行计划;3.利用MySQL自带监控工具(SHOWPROCESSLIST,SHOWSTATUS)监控数据库运行状况,定期备份和整理数据库。通过这些步骤,持续优化,才能提升MySQL数据库性能。
-

MySQL中文乱码可以通过修改字符集解决。1.修改数据库字符集:ALTERDATABASEmydatabaseCHARACTERSETutf8mb4COLLATEutf8mb4_unicode_ci;2.修改表字符集:ALTERTABLEmytableCONVERTTOCHARACTERSETutf8mb4COLLATEutf8mb4_unicode_ci;3.设置连接字符集:SETNAMES'utf8mb4';4.设置客户端字符集:mysql-uusername-p--default-character
-

<p>在MySQL中,AS关键字用于给列或表创建临时名称,即别名。1)给列创建别名,如SELECTprice*quantityAStotal_priceFROMorder_items,使结果更易读。2)给表创建别名,如SELECTo.order_id,c.customer_nameFROMordersASoJOINcustomersAScONo.customer_id=c.customer_id,简化多表查询。</p>
-

要设置MySQL性能监控,首先启用慢查询日志,在配置文件中设置slow_query_log、slow_query_log_file和long_query_time;其次使用SHOWSTATUS和SHOWPROCESSLIST实时查看数据库状态;最后引入第三方工具如Prometheus+Grafana或PMM进行可视化监控。核心指标包括:1.查询性能(QPS、慢查询数量、缓冲池命中率);2.资源使用(CPU、内存、磁盘IO);3.连接与线程状态(连接数、Threads_running);4.锁与事务问题(表
-

主键是表中唯一标识每条记录的列或列组合,其作用包括保证数据唯一性和提升表性能。1)主键必须唯一且不含NULL值。2)选择自增整数作为主键可提高查询效率。3)避免使用易变字段或过长字符串作为主键,以防性能下降。4)复合主键适用于某些场景,但维护和查询较复杂。
-

MySQL中的事务特性用ACID表示,分别是原子性、一致性、隔离性和持久性。1.原子性确保事务内的操作全部成功或失败。2.一致性保证事务前后数据库状态一致。3.隔离性防止事务间相互影响。4.持久性确保事务提交后数据永久保存。
-

Redis的有序集合(SortedSet)非常适合排行榜应用。1)它可以轻松维护有序列表并按分数排序,2)通过简单命令实现数据的插入、更新、查询和删除,3)但在大规模数据下需优化查询性能和处理实时更新,4)需保证数据一致性和完整性。
-

电脑是否安装了MySQL可以通过五种方法全面排查:1.通过命令行检查MySQL服务,2.查看MySQL安装目录,3.使用MySQL命令行工具,4.检查环境变量,5.通过注册表(Windows)或包管理器(Linux)检查。每种方法都有其独特的优势和适用场景,确保全面排查MySQL的安装情况。
-

MySQL实现数据校验主要通过约束和触发器两种方式。1.约束提供声明式校验,包括NOTNULL、UNIQUE、PRIMARYKEY、FOREIGNKEY和CHECK,适用于简单高效的数据校验场景;2.触发器则通过事件自动执行SQL代码,支持复杂逻辑判断和跨表校验,如插入前检查客户ID是否存在。选择时需考虑:1.校验复杂性,简单规则用约束,复杂逻辑用触发器;2.性能方面,约束更高效;3.可维护性上,约束更优;4.灵活性上,触发器更强。两者可结合使用以兼顾性能与灵活性。
-

Redis内存占用过高可以通过以下步骤优化:1.设置maxmemory参数控制内存使用量;2.选择合适的内存回收策略,如volatile-lru或allkeys-lru;3.使用EXPIRE命令设置键的过期时间;4.选择合适的数据结构,如使用Hash类型存储小对象;5.调整持久化配置,选择RDB或AOF;6.实施分片(Sharding)技术。这些方法结合使用,可以有效降低Redis的内存占用,提升系统性能。
-

Redis哨兵模式不支持自动伸缩,其核心能力仅限于监控存活、触发故障转移和提供主节点地址;它不参与节点增删、数据分片或路由更新。
-

哨兵选主按slave-priority、复制偏移量、RunID三步筛选:优先过滤priority为0的节点;再比对offset,越大越优;最后按RunID字典序升序取首个。
-
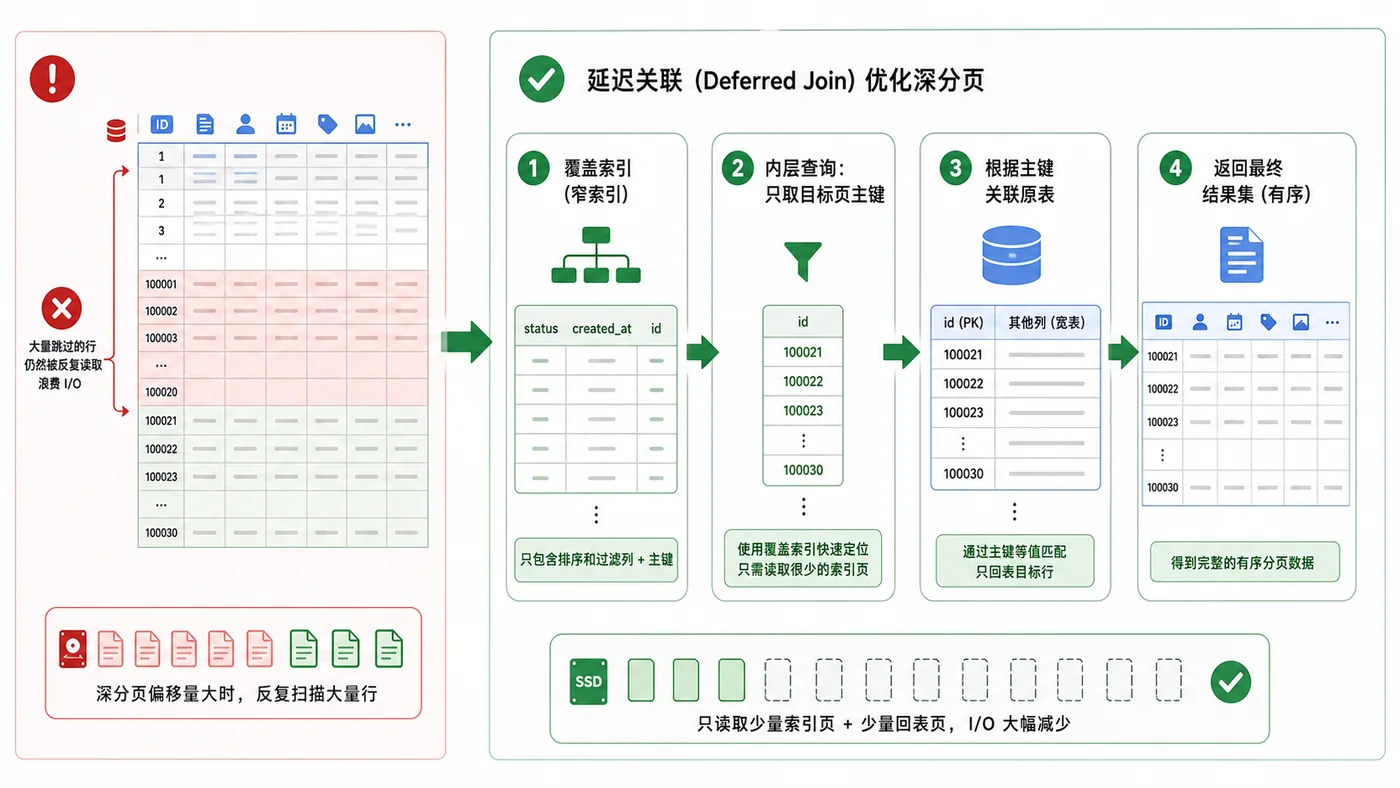
本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。
-

本文转载自微信公众号「后端技术指南针」,作者大白斯基。转载本文请联系后端技术指南针公众号。
跳跃链表及其应用是非常热门的问题,深入了解其中奥秘大有裨益,不吹了,快开始品尝
-

1、Mysql数据库开启binlog模式
注意:Mysql容器,此处Mysql版本为5.7
#进入容器
docker exec -it mysql /bin/bash
#进入配置目录
cd /etc/mysql/mysql.conf.d
#修改配置文件
vi mysqld.cnf
(1) 修改mysqld.cnf配置文件,添加