-

Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,常被用作数据库、缓存和消息队列等。它支持多种数据结构,包括字符串、哈希表、列表、集合和有序集合。以下是 Redis 的一些
-

PHP 异步编程: 手把手教你实现 co 与 Koa - 后端 - 掘金PHP异步编程: 手把手教你实现co与Koa 前言 ...
Shell 助力开发效率提升 - 工具资源 - 掘金本文主要来源于小组内部的一个小的分享, 这里整理成一
-

关于MySQL的二进制日志(binlog),我们都知道二进制日志(binlog)非常重要,尤其当你需要point to point灾难恢复的时侯,所以我们要对其进行备份。关于二进制日志(binlog)的备份,可以基于flush log
-

开篇
在我们的生产环境中,有一个模糊检索的文档框,但是当数据量级别上去之后,频繁对数据库造成压力,所以想使用Full Text全文索引进行优化 下面是一个总结的简单案例
一个简单的DEMO
假设我们
-

一、自增值保存在哪儿?不同的引擎对于自增值的保存策略不同1.MyISAM引擎的自增值保存在数据文件中2.InnoDB引擎的自增值,在MySQL5.7及之前的版本,自增值保存在内存里,并没有持
-
函数 是指一段可以直接被另一段程序调用的程序或代码。 也就意味着,这一段程序或代码在MySQL中已经给我们提供了,我们要做的就是在合适的业务场景调用对应的函数完成对应的业务需求即
-

MySQL是目前企业级最常用的开源关系型数据库管理系统,在数据管理系统中,数据的完整性是至关重要的。完整性是指数据的准确性和完整性,确保没有无效或重复数据,并且数据在数据库中的约束条件中受到保护。本文将介绍MySQL实现数据的完整性保障技巧。主键约束主键是表中唯一标识每个记录的一列或一组列。MySQL中可以通过使用PRIMARYKEY关键字定义主键。主键保
-

随着互联网技术的不断发展,数据存储和处理成为了每个企业都必须面对的问题。MySQL数据库和Go语言作为常用的数据库和编程语言,如何进行数据的外部高速存储,更是亟需解决的问题。本文将介绍如何使用MySQL数据库和Go语言实现数据的外部高速存储。一、MySQL数据库的优势和不足MySQL是一款关系型数据库管理系统,是互联网企业中使用率最高的数据库之一。它被广泛应
-

Yes,MySQLwillupdatethevalue,ifitisupdatedinaview,inthebasetableaswellasinitsassociatedviews.ToillustrateitwearetakingtheexampleoftableStudent_infohavingthefollowingdata−mysql>Select*fromstudent_info;+------+---------+------------+------------+|id
-

如何使用MySQL数据库进行推荐系统任务?随着互联网的发展,推荐系统成为了各大平台不可或缺的一环。而数据库作为推荐系统的重要组成部分,承担着存储和管理用户和物品数据的重要任务。本文将介绍如何使用MySQL数据库来实现推荐系统任务,并给出相应的代码示例。首先,我们需要创建用户和物品两个主要的数据表。用户表用于存储用户的特征信息,物品表用于存储物品的特征信息。以
-

Redis在Rust语言项目中的应用指南一、介绍Redis是一个开源的内存数据结构存储系统,它支持多种数据类型的存储和操作。它可以作为缓存、数据库或消息中间件使用。Rust是一种安全且高效的系统编程语言,与Redis非常搭配。本文将介绍Redis在Rust语言项目中的应用指南,并提供一些代码示例。二、Rust和Redis的集成在Rust项目中使用Redis,
-
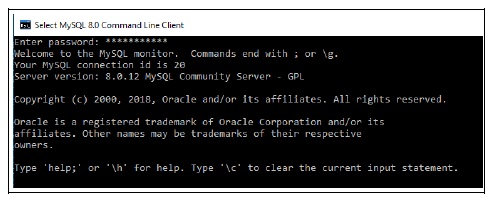
当我们创建表但忘记选择数据库时,可能会出现错误#1046。让我们说我们已经按照下面所示启动了MySQL−在输入正确的密码后,上述窗口将打开。现在创建一个没有选择任何数据库。这将显示一个错误−mysql>CREATEtableTblUni->(->idint,->Namevarchar(100)->);错误1046(3D000):未选择数据库以下屏幕截图显示了相同的错误-现在,选择任何数据库来消除上述错误。首先我们先来看看有多少数据库在SHOW命令的帮助
-

MySQL中的LIMIT关键字可以指定输出中返回的记录数。LIMIT子句限制要返回的行数。可以通过以下示例来理解-示例mysql>Select*fromStudent_info;+------+---------+------------+------------+|id |Name |Address |Subject |+------+---------+------------+------------+| 1
-

解决Oracle提示乱码问题的方法总结在使用Oracle数据库时,经常会遇到数据存储或查询过程中出现乱码的情况,这给数据操作和结果展示带来了困扰。造成乱码问题的主要原因是数据库字符集与客户端字符集不匹配,或者数据存储时未指定正确的字符集。要解决Oracle提示乱码问题,我们可以采取以下方法:确定数据库字符集:首先要了解数据库的字符集设置,可以通过查询数据库的
-

OracleNVL函数常见问题及解决方案Oracle数据库是广泛使用的关系型数据库系统,在数据处理过程中经常需要处理空值的情况。为了应对空值带来的问题,Oracle提供了NVL函数来处理空值。本文将介绍NVL函数的常见问题及解决方案,并提供具体的代码示例。问题一:NVL函数用法不当NVL函数的基本语法是:NVL(expr1,default_value)其