Go语言技术文章
-
数据库 · MySQL | 20小时前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
 订单列表把渠道、会员等级放进 JSON 后,筛选条件容易变成逐行计算。本文用 MySQL 生成列和索引把 JSON 路径变成可核对的查询字段,同时处理缺失键、空字符串、类型转换和写入成本。351 收藏
订单列表把渠道、会员等级放进 JSON 后,筛选条件容易变成逐行计算。本文用 MySQL 生成列和索引把 JSON 路径变成可核对的查询字段,同时处理缺失键、空字符串、类型转换和写入成本。351 收藏 -
 MySQL 读写分离不是简单把 SELECT 丢到从库。它适合读多写少、查询压力明显大于写入压力的业务,但会带来复制延迟、读己之写、路由规则和故障切换问题。上线前要先确认读写比例、数据一致性要求和回主策略。334 收藏
MySQL 读写分离不是简单把 SELECT 丢到从库。它适合读多写少、查询压力明显大于写入压力的业务,但会带来复制延迟、读己之写、路由规则和故障切换问题。上线前要先确认读写比例、数据一致性要求和回主策略。334 收藏 -
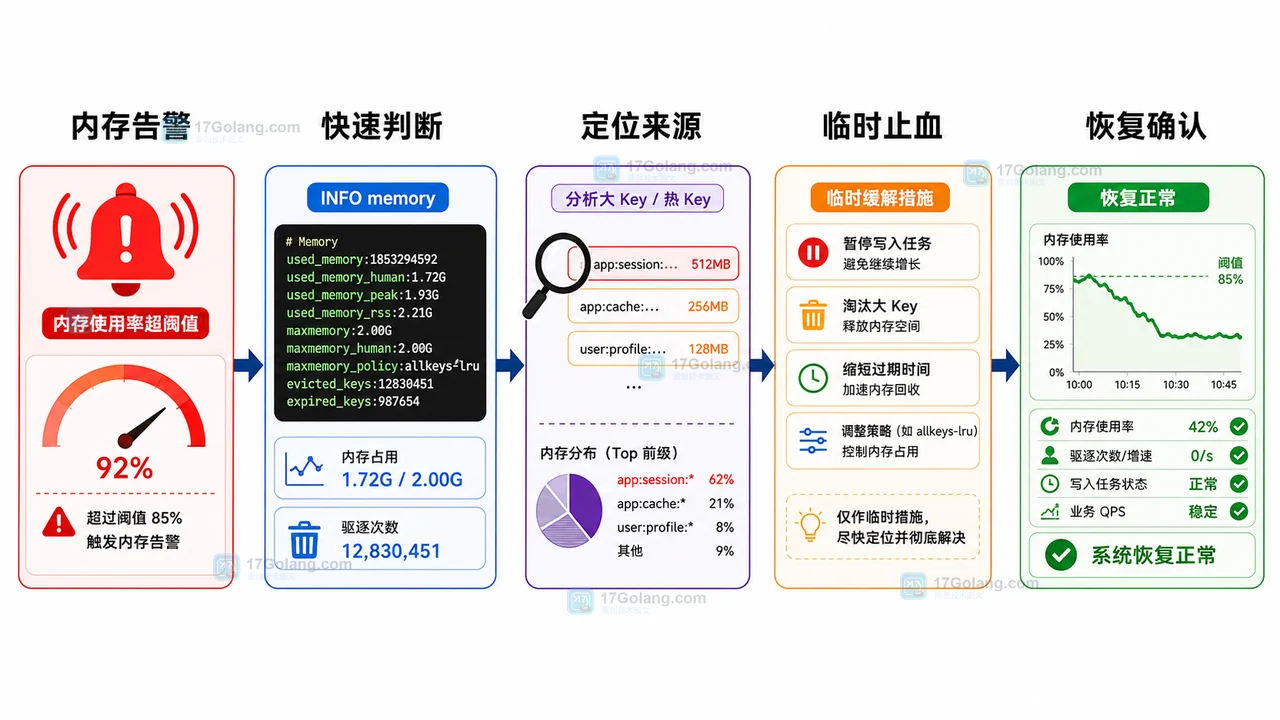 面向线上 Redis 内存告警的运行手册,覆盖触发信号、INFO memory 快速判断、bigkeys 排查、maxmemory 与淘汰策略检查、临时止血、回滚和复盘清单。313 收藏
面向线上 Redis 内存告警的运行手册,覆盖触发信号、INFO memory 快速判断、bigkeys 排查、maxmemory 与淘汰策略检查、临时止血、回滚和复盘清单。313 收藏 -
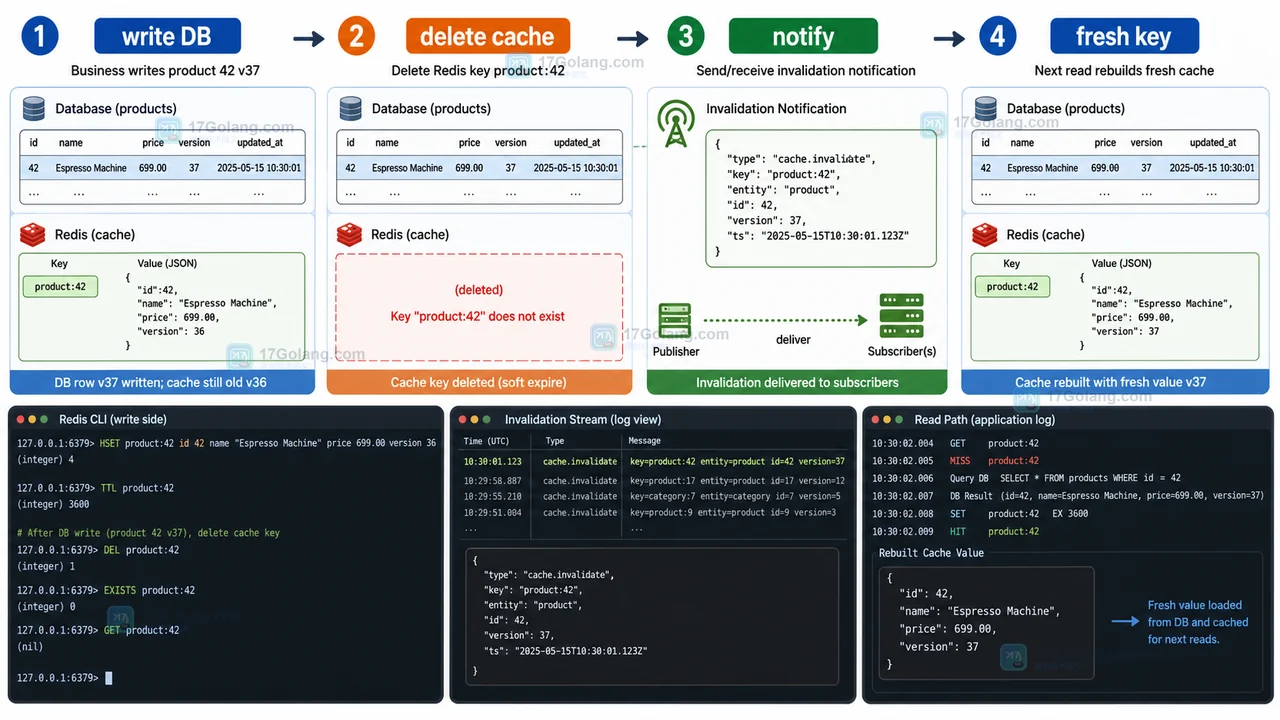 从 Redis 缓存治理趋势出发,分析单一 TTL 的不足,给出软过期、写侧失效通知、新鲜度指标和渐进落地路径,帮助团队在高峰流量下减少脏读窗口。280 收藏
从 Redis 缓存治理趋势出发,分析单一 TTL 的不足,给出软过期、写侧失效通知、新鲜度指标和渐进落地路径,帮助团队在高峰流量下减少脏读窗口。280 收藏 -
数据库 · MySQL | 4天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort
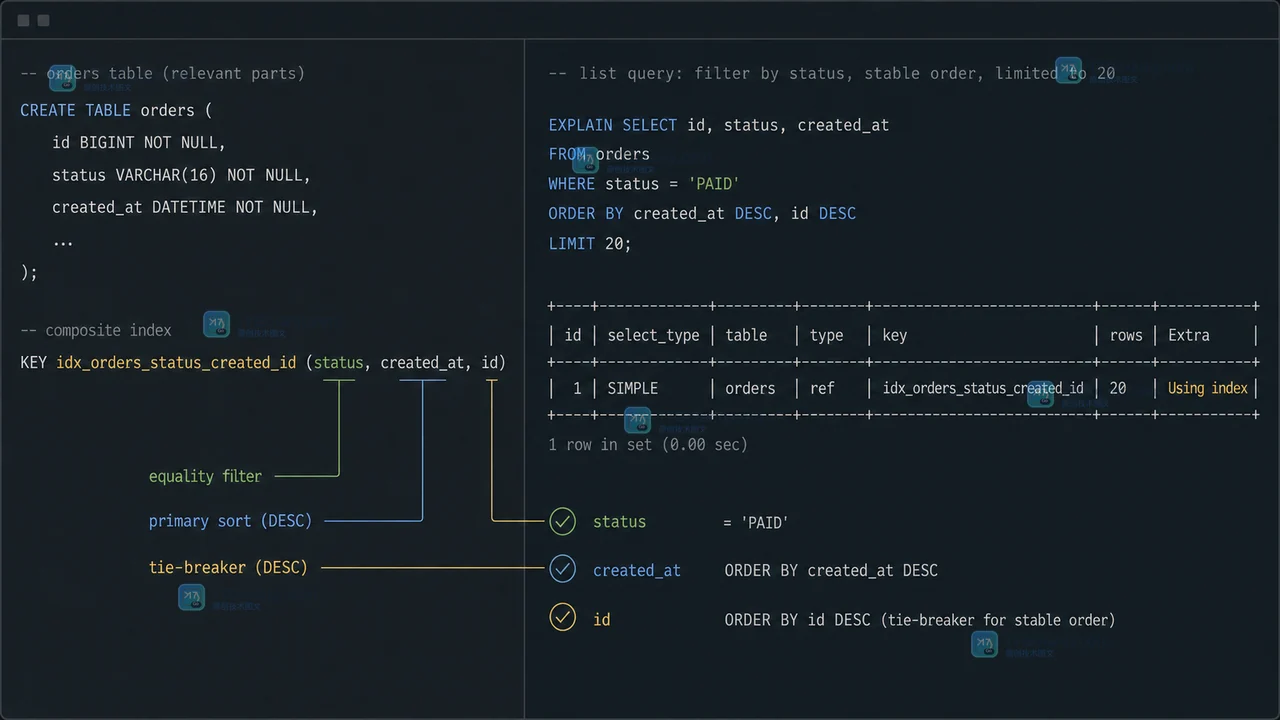 一条只取 20 行的订单查询,EXPLAIN 却可能放弃看似更贴近 WHERE 条件的索引,改走排序索引并在途中筛选。原因是 LIMIT 同时改变了排序、过滤和回表的成本取舍。通过读懂 key、rows 和 Extra,给等值条件与排序字段设计复合索引,再用受控对比核实实际读行,才能避免把 filesort 或某个索引名称当成唯一结论。279 收藏
一条只取 20 行的订单查询,EXPLAIN 却可能放弃看似更贴近 WHERE 条件的索引,改走排序索引并在途中筛选。原因是 LIMIT 同时改变了排序、过滤和回表的成本取舍。通过读懂 key、rows 和 Extra,给等值条件与排序字段设计复合索引,再用受控对比核实实际读行,才能避免把 filesort 或某个索引名称当成唯一结论。279 收藏 -
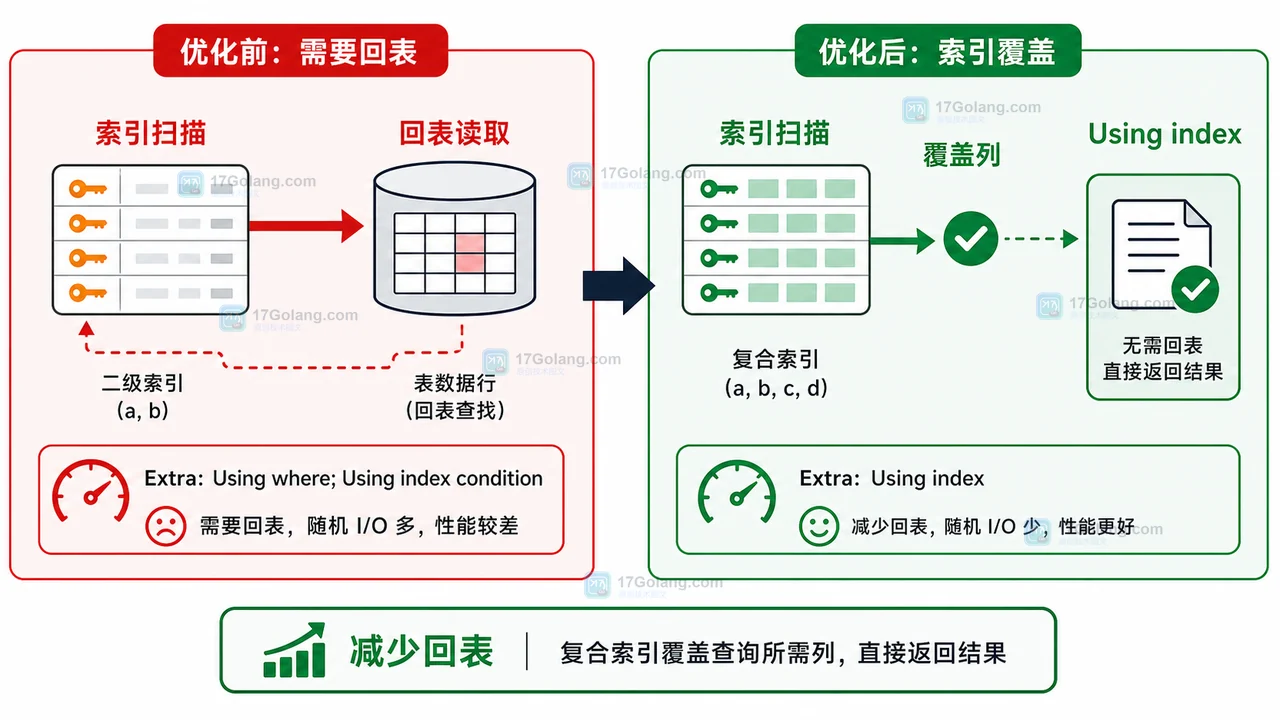 通过一个可复现的小实验,从订单列表慢查询开始,初始化表和数据,添加复合索引,再用 EXPLAIN 检查 Using index,理解覆盖索引的适用边界。276 收藏
通过一个可复现的小实验,从订单列表慢查询开始,初始化表和数据,添加复合索引,再用 EXPLAIN 检查 Using index,理解覆盖索引的适用边界。276 收藏 -
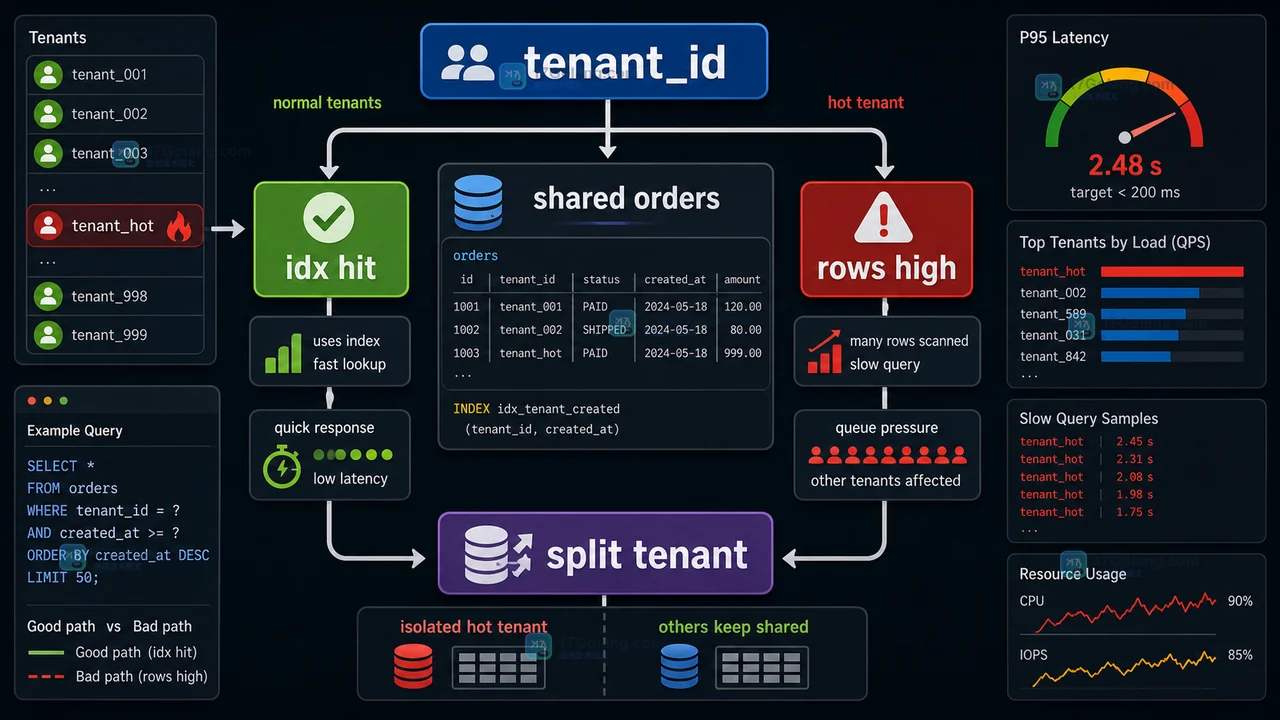 MySQL 多租户订单表变慢时,先用 tenant_id 领头的联合索引稳住常见查询;当热点租户持续拉高 rows、慢日志和队列等待,再考虑租户路由、冷热分流或独立分片。259 收藏
MySQL 多租户订单表变慢时,先用 tenant_id 领头的联合索引稳住常见查询;当热点租户持续拉高 rows、慢日志和队列等待,再考虑租户路由、冷热分流或独立分片。259 收藏 -
数据库 · Redis | 2天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT
 商品详情页把库存、价格和活动状态合成一次 MGET 后,在 Redis Cluster 里突然报 CROSSSLOT,根因往往不是客户端,而是同一业务实体的 Key 没有落到同一个槽位。本文用 CLUSTER KEYSLOT、Hash Tag 和迁移期检查拆出一条可复查的修复路径。259 收藏
商品详情页把库存、价格和活动状态合成一次 MGET 后,在 Redis Cluster 里突然报 CROSSSLOT,根因往往不是客户端,而是同一业务实体的 Key 没有落到同一个槽位。本文用 CLUSTER KEYSLOT、Hash Tag 和迁移期检查拆出一条可复查的修复路径。259 收藏 -
 Redis 7.0 起,EXPIRE 可用 NX、XX、GT、LT 为过期时间加条件。NX 只给没有 TTL 的 key 首次设置过期,XX 只更新已有 TTL 的 key,GT 只允许延长,LT 只允许缩短。它们互斥;TTL 返回 -1 表示 key 存在但没有过期时间,-2 表示 key 不存在。把条件写清楚,才能避免续期任务意外把缓存窗口改乱。250 收藏
Redis 7.0 起,EXPIRE 可用 NX、XX、GT、LT 为过期时间加条件。NX 只给没有 TTL 的 key 首次设置过期,XX 只更新已有 TTL 的 key,GT 只允许延长,LT 只允许缩短。它们互斥;TTL 返回 -1 表示 key 存在但没有过期时间,-2 表示 key 不存在。把条件写清楚,才能避免续期任务意外把缓存窗口改乱。250 收藏 -
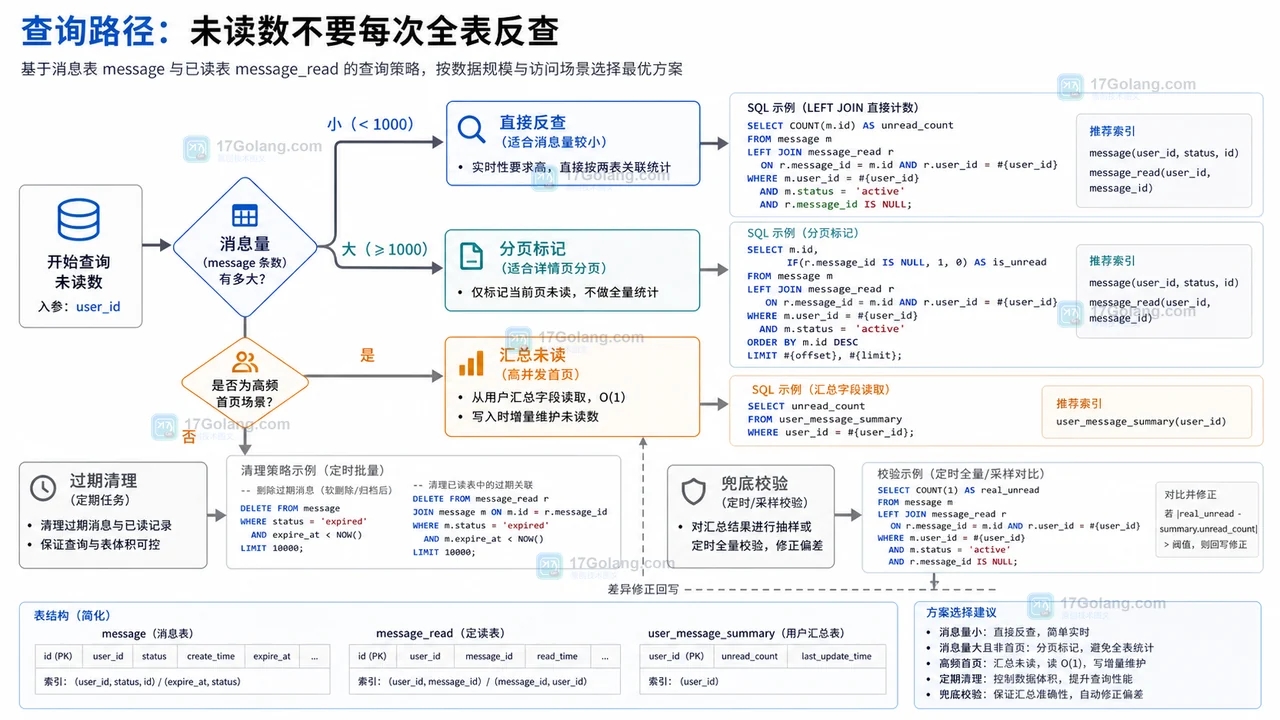 本文按数据生命周期说明 MySQL 消息已读表设计:消息如何产生,已读记录如何去重写入,未读数如何查询,重复点击和并发如何处理,以及历史数据如何清理。243 收藏
本文按数据生命周期说明 MySQL 消息已读表设计:消息如何产生,已读记录如何去重写入,未读数如何查询,重复点击和并发如何处理,以及历史数据如何清理。243 收藏 -
数据库 · MySQL | 3星期前 | MySQL · InnoDB · 性能排查 · 故障复盘 · 长事务 · mysql PURGE 长事务 Undo history list length 写入延迟
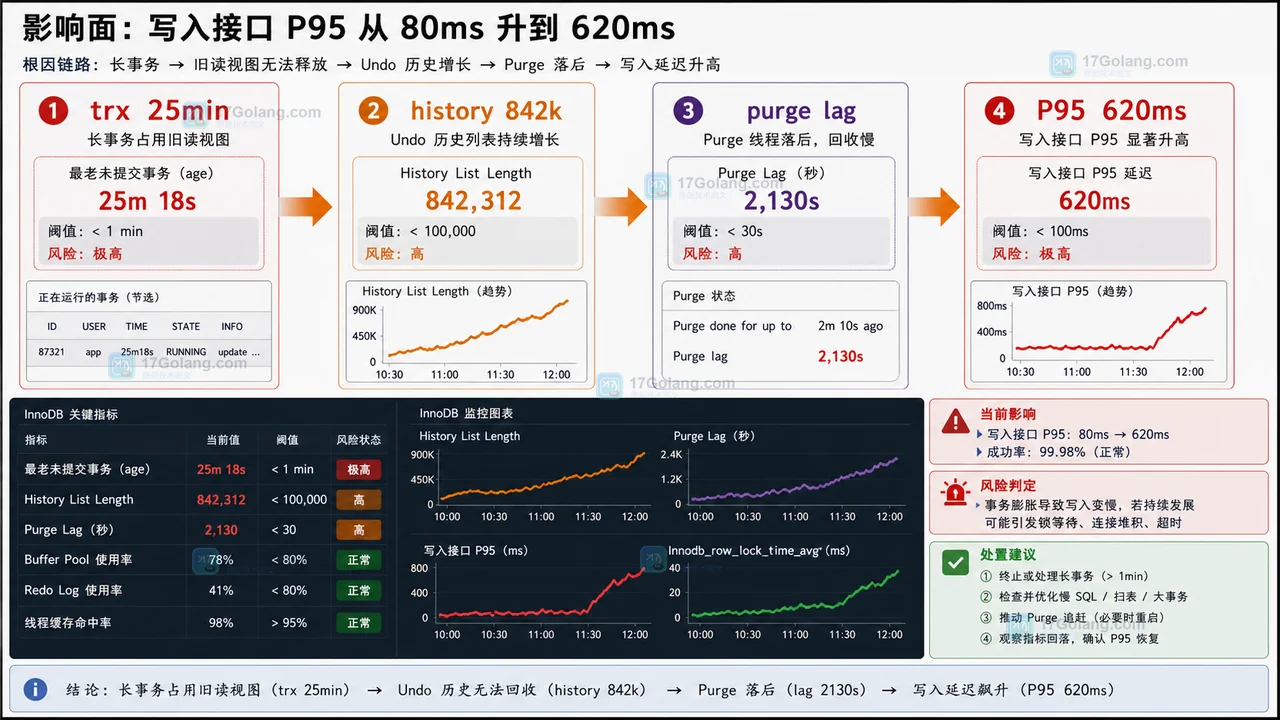 复盘一次 MySQL 写入延迟突然升高的问题:从影响面和时间线入手,通过 innodb_trx、history list length 和 purge 状态定位长事务拖住 undo 清理,并给出修复和防复发清单。242 收藏
复盘一次 MySQL 写入延迟突然升高的问题:从影响面和时间线入手,通过 innodb_trx、history list length 和 purge 状态定位长事务拖住 undo 清理,并给出修复和防复发清单。242 收藏 -
数据库 · MySQL | 1天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移
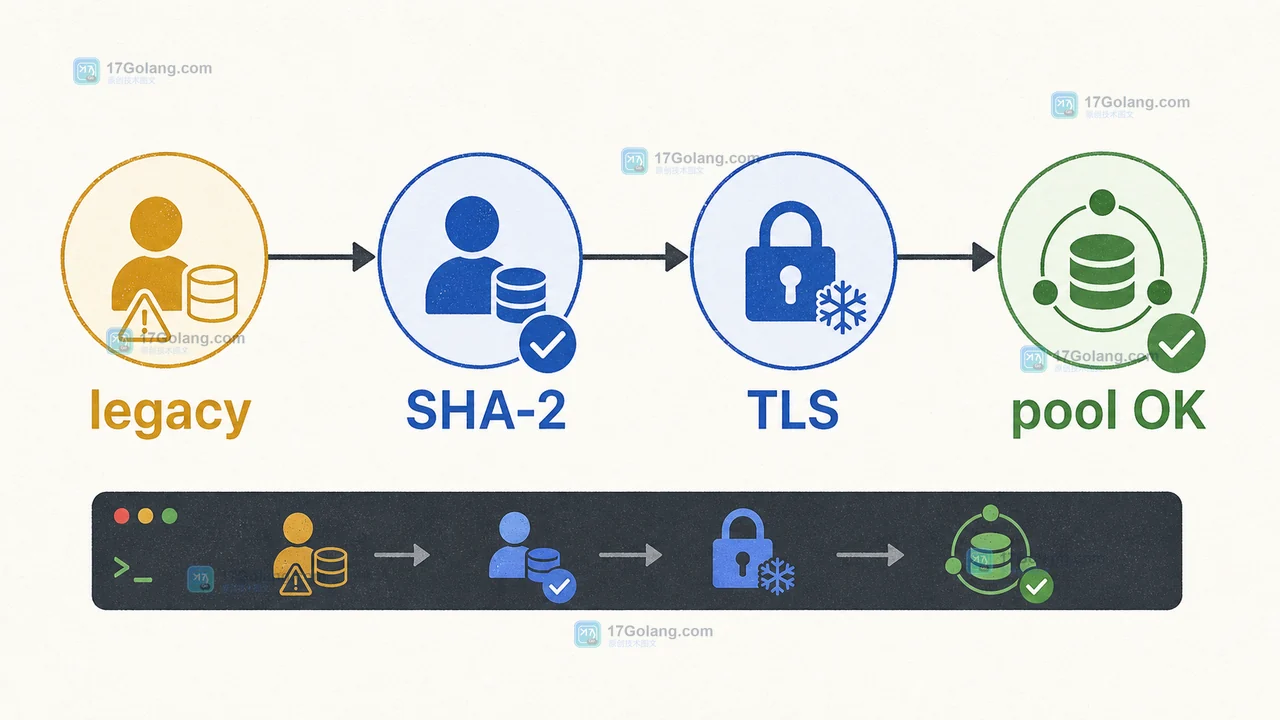 MySQL 8.4 默认不再启用 mysql_native_password,老应用可能在发版后出现账号认证失败。本文用账号盘点、灰度改造、TLS 连通性检查和回退边界,讲清迁移到 caching_sha2_password 的可靠做法。236 收藏
MySQL 8.4 默认不再启用 mysql_native_password,老应用可能在发版后出现账号认证失败。本文用账号盘点、灰度改造、TLS 连通性检查和回退边界,讲清迁移到 caching_sha2_password 的可靠做法。236 收藏 -
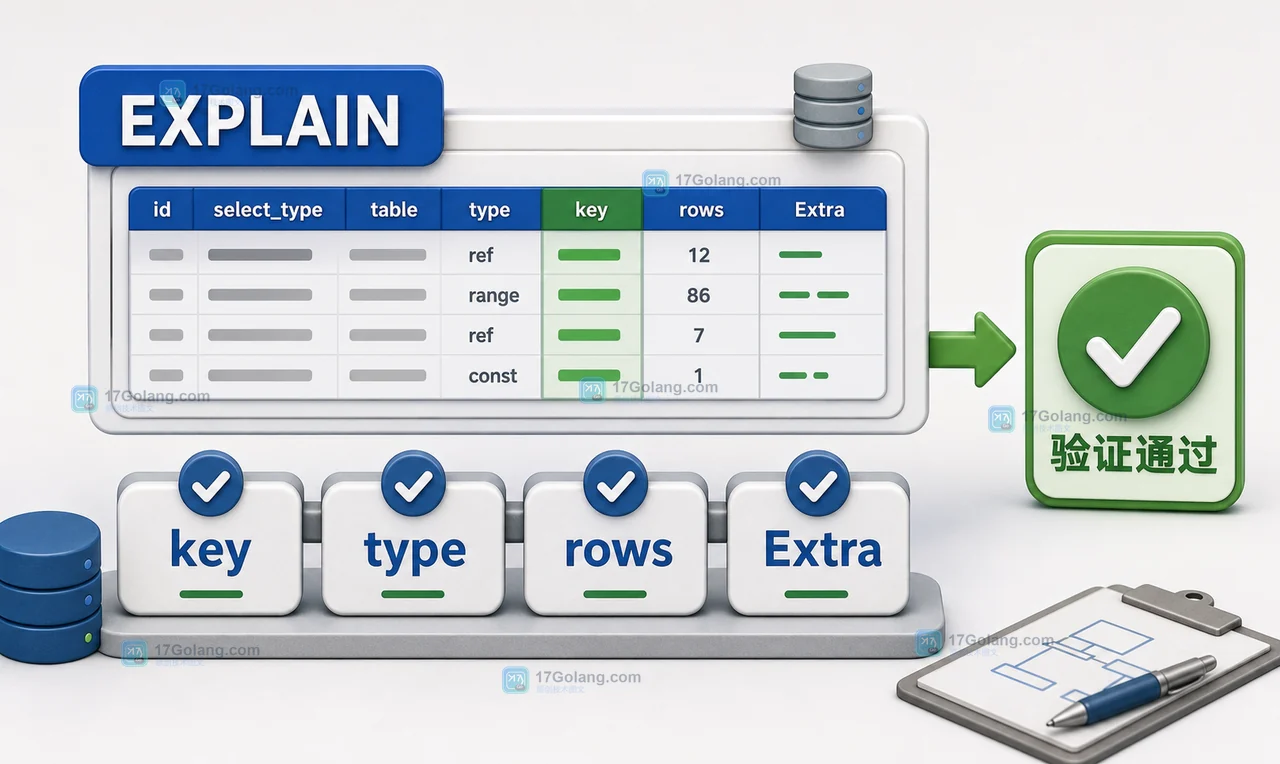 MySQL 查询不走索引,常见原因不是索引不存在,而是 SQL 写法让优化器难以利用索引。函数包列、隐式类型转换、范围过宽和联合索引顺序不匹配,都应该用 EXPLAIN 验证后再改写。189 收藏
MySQL 查询不走索引,常见原因不是索引不存在,而是 SQL 写法让优化器难以利用索引。函数包列、隐式类型转换、范围过宽和联合索引顺序不匹配,都应该用 EXPLAIN 验证后再改写。189 收藏 -
 线上 Redis 里堆积了过期业务前缀或历史缓存时,不能直接用 KEYS 和 DEL 硬删。用 SCAN 分批遍历、先记录样本、按速率提交 UNLINK,并保留停止开关和统计结果,能把清理风险压到可控范围。183 收藏
线上 Redis 里堆积了过期业务前缀或历史缓存时,不能直接用 KEYS 和 DEL 硬删。用 SCAN 分批遍历、先记录样本、按速率提交 UNLINK,并保留停止开关和统计结果,能把清理风险压到可控范围。183 收藏 -
数据库 · Redis | 3星期前 | Redis · 缓存治理 · Keyspace Notifications · 过期事件 · redis Pub/Sub Keyspace Notifications 过期事件 缓存监听 补偿任务
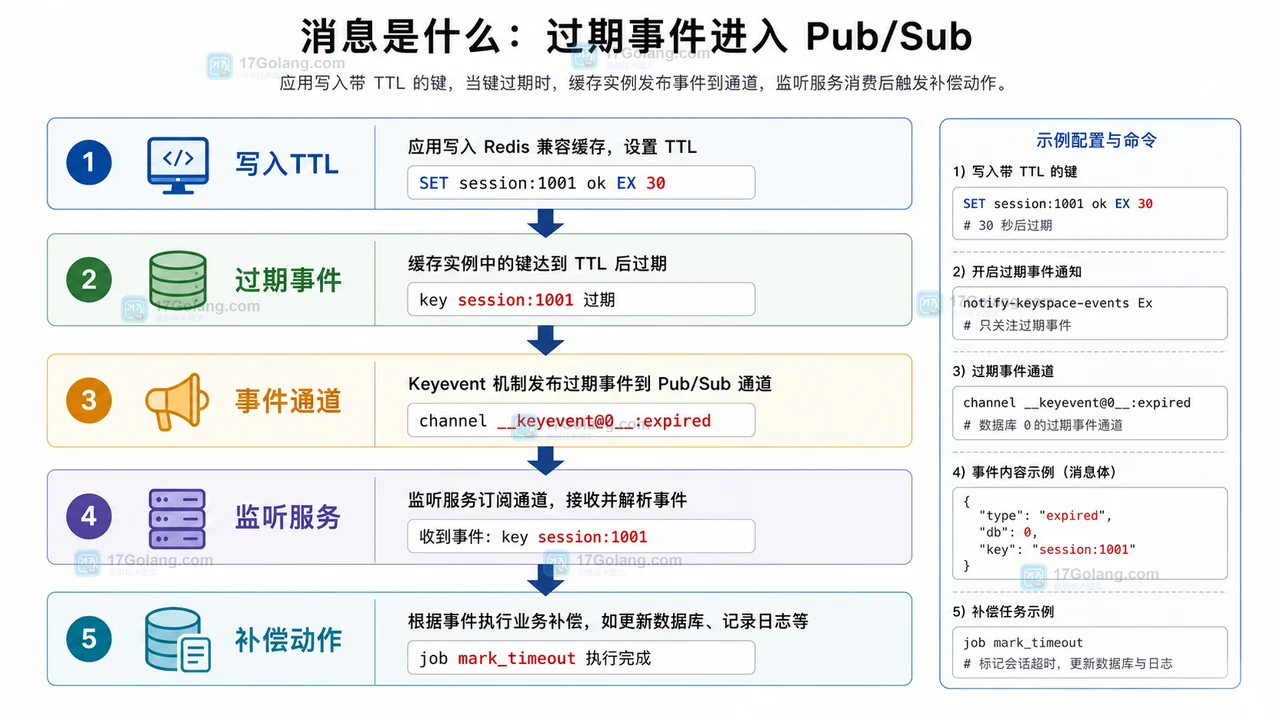 本文用 Redis Keyspace Notifications 演示如何监听过期 Key,配置 notify-keyspace-events,接收 __keyevent@0__:expired 事件,并说明事件通知的丢失风险与补扫兜底做法。181 收藏
本文用 Redis Keyspace Notifications 演示如何监听过期 Key,配置 notify-keyspace-events,接收 __keyevent@0__:expired 事件,并说明事件通知的丢失风险与补扫兜底做法。181 收藏