Go语言技术文章
-
 Redis从库默认只读,slave-read-onlyyes是防意外写入的保险栓;设为no后从库可写但导致主从数据不一致,因写命令不回传主库且故障转移会扩散脏数据。464 收藏
Redis从库默认只读,slave-read-onlyyes是防意外写入的保险栓;设为no后从库可写但导致主从数据不一致,因写命令不回传主库且故障转移会扩散脏数据。464 收藏 -
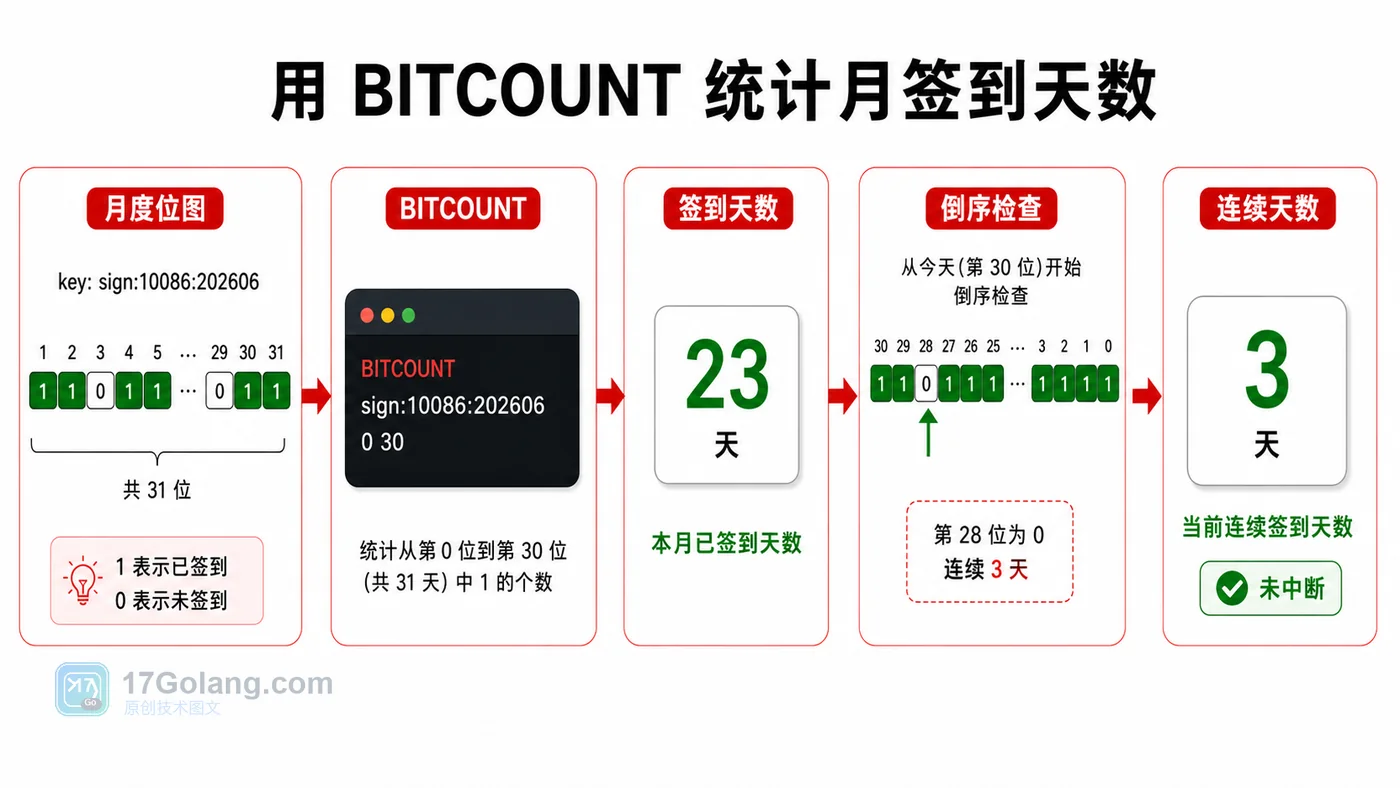 本文用 Redis Bitmap 实现用户签到:用 SETBIT 写入每天状态,用 GETBIT 查询当天是否签到,用 BITCOUNT 快速统计月签到天数,并补充连续签到和键设计建议。464 收藏
本文用 Redis Bitmap 实现用户签到:用 SETBIT 写入每天状态,用 GETBIT 查询当天是否签到,用 BITCOUNT 快速统计月签到天数,并补充连续签到和键设计建议。464 收藏 -
 本文从 Redis 分布式锁偶发并发进入的现场出发,复现旧请求误删新锁的问题,定位锁值缺少身份标记的根因,并用 token 校验方式修复释放锁流程。464 收藏
本文从 Redis 分布式锁偶发并发进入的现场出发,复现旧请求误删新锁的问题,定位锁值缺少身份标记的根因,并用 token 校验方式修复释放锁流程。464 收藏 -
 Redis6+的io-threads应设为2~8,不超过磁盘队列深度的2倍,且必须保持io-threads-do-readsno;它仅加速写入内核页缓存,不加速fsync,设得过多反而加剧IOWAIT和延迟。463 收藏
Redis6+的io-threads应设为2~8,不超过磁盘队列深度的2倍,且必须保持io-threads-do-readsno;它仅加速写入内核页缓存,不加速fsync,设得过多反而加剧IOWAIT和延迟。463 收藏 -
 Redis4.0起,24位lru字段在LFU模式下拆为高16位ldt(分钟级时间戳)和低8位logc(对数计数器),ldt=(time_t/60)&0xFFFF,logc初始为5并用概率递增算法更新。461 收藏
Redis4.0起,24位lru字段在LFU模式下拆为高16位ldt(分钟级时间戳)和低8位logc(对数计数器),ldt=(time_t/60)&0xFFFF,logc初始为5并用概率递增算法更新。461 收藏 -
 集群模式下slave-read-onlyyes无效,因集群协议绕过主从配置;必须用readonly命令开启连接级只读,使从节点响应本主槽读请求。461 收藏
集群模式下slave-read-onlyyes无效,因集群协议绕过主从配置;必须用readonly命令开启连接级只读,使从节点响应本主槽读请求。461 收藏 -
 应先检查是否连接泄露,再调整maxclients:通过redis-cliclientlist确认连接是否持续增长,修复Jedis未close问题;若确需扩容,须同步调高系统ulimit-n并重启Redis。460 收藏
应先检查是否连接泄露,再调整maxclients:通过redis-cliclientlist确认连接是否持续增长,修复Jedis未close问题;若确需扩容,须同步调高系统ulimit-n并重启Redis。460 收藏 -
 必须同时排除RedisAutoConfiguration和RedisRepositoriesAutoConfiguration,否则因后者依赖redisTemplate而启动失败;exclude参数需传入Class数组,配置文件中须正确书写全限定名并避免缩进错误,且需清理残留Redis属性和手动Bean。459 收藏
必须同时排除RedisAutoConfiguration和RedisRepositoriesAutoConfiguration,否则因后者依赖redisTemplate而启动失败;exclude参数需传入Class数组,配置文件中须正确书写全限定名并避免缩进错误,且需清理残留Redis属性和手动Bean。459 收藏 -
 RedisCluster默认不支持传统Pub/Sub跨节点广播,因频道按slot分片且gossip协议不传播订阅状态,SUBSCRIBE仅在本地节点生效;根本原因在于集群设计只负责数据分片,不实现消息路由。459 收藏
RedisCluster默认不支持传统Pub/Sub跨节点广播,因频道按slot分片且gossip协议不传播订阅状态,SUBSCRIBE仅在本地节点生效;根本原因在于集群设计只负责数据分片,不实现消息路由。459 收藏 -
 Pub/Sub频道命名必须带租户前缀,采用三段式结构{租户标识}:{业务域}:{实体ID},禁用裸频道和通配符泛订阅;ACL需按前缀精确控制,显式授权+subscribe/+publish;TLS与消息体加密必须同时启用;Pub/Sub不可替代可靠队列,应改用Stream或List。457 收藏
Pub/Sub频道命名必须带租户前缀,采用三段式结构{租户标识}:{业务域}:{实体ID},禁用裸频道和通配符泛订阅;ACL需按前缀精确控制,显式授权+subscribe/+publish;TLS与消息体加密必须同时启用;Pub/Sub不可替代可靠队列,应改用Stream或List。457 收藏 -
 Redis碎片率超1.5时响应变慢甚至雪崩,根本原因是jemalloc在不连续空闲块中反复查找合适内存块,导致分配延迟升高、CPU波动、GC压力上升并可能引发级联雪崩。457 收藏
Redis碎片率超1.5时响应变慢甚至雪崩,根本原因是jemalloc在不连续空闲块中反复查找合适内存块,导致分配延迟升高、CPU波动、GC压力上升并可能引发级联雪崩。457 收藏 -
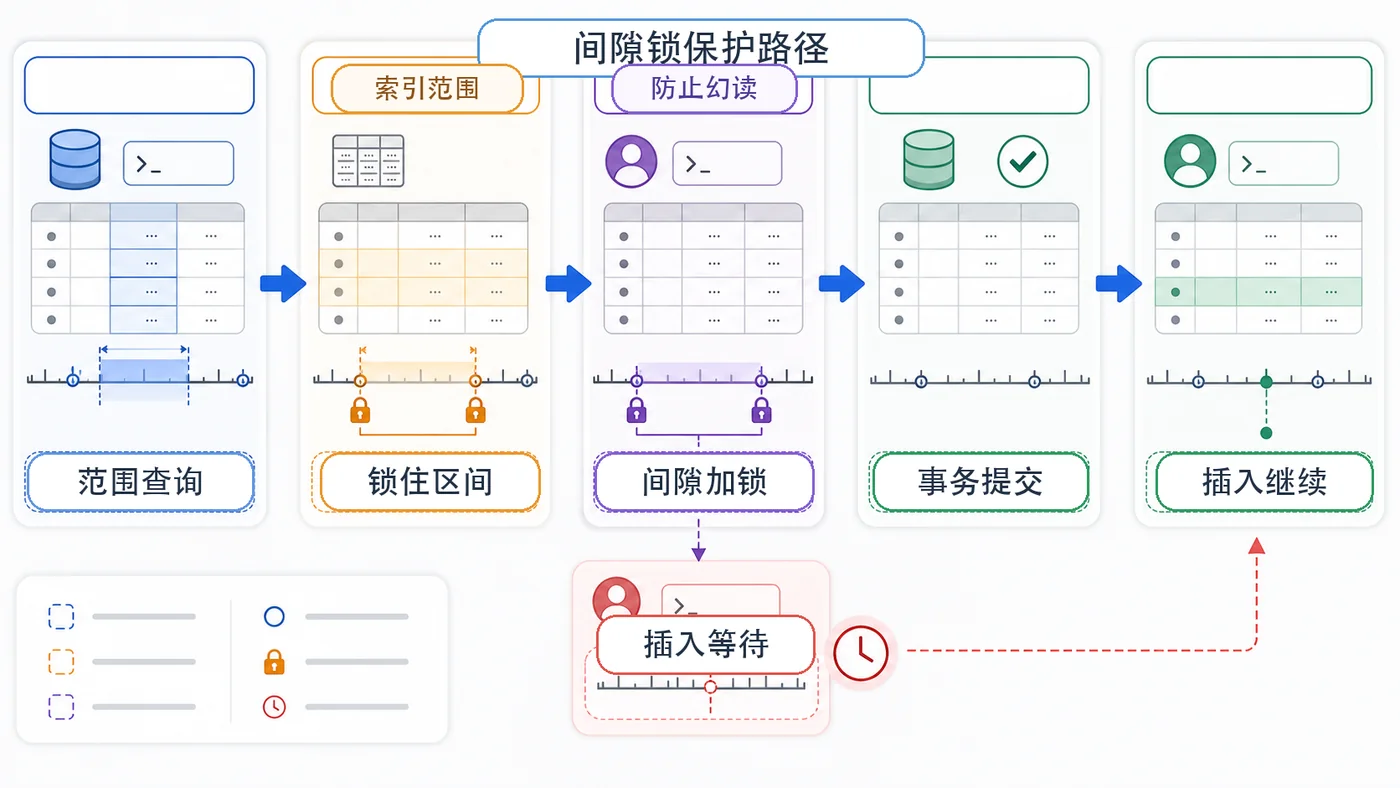 本文用两个 MySQL 会话复现可重复读和幻读场景,解释快照读、当前读、范围查询和间隙锁的关系,帮助排查线上并发写入问题。455 收藏
本文用两个 MySQL 会话复现可重复读和幻读场景,解释快照读、当前读、范围查询和间隙锁的关系,帮助排查线上并发写入问题。455 收藏 -
 根本原因是客户端频繁新建并立即关闭TCP连接,导致Linux内核在主动关闭方维持TIME_WAIT状态(2×MSL,通常60秒),端口无法复用;Redis服务端不产生该状态,问题源于客户端未复用连接池、错误调用close()、配置不当或框架内重复初始化。454 收藏
根本原因是客户端频繁新建并立即关闭TCP连接,导致Linux内核在主动关闭方维持TIME_WAIT状态(2×MSL,通常60秒),端口无法复用;Redis服务端不产生该状态,问题源于客户端未复用连接池、错误调用close()、配置不当或框架内重复初始化。454 收藏 -
 volatile-lru是仅对设置了TTL的key生效的近似LRU淘汰策略,不淘汰无过期时间的key;必须显式配置maxmemory-policy且配合EXPIRE或SETEX使用,否则无效。454 收藏
volatile-lru是仅对设置了TTL的key生效的近似LRU淘汰策略,不淘汰无过期时间的key;必须显式配置maxmemory-policy且配合EXPIRE或SETEX使用,否则无效。454 收藏 -
 是,HLL适合统计日活UV,但需接受约0.81%误差且不支持成员查询与精确交集;按日期分key(如uv:20240520)、设过期、统一用户标识方可稳健使用。453 收藏
是,HLL适合统计日活UV,但需接受约0.81%误差且不支持成员查询与精确交集;按日期分key(如uv:20240520)、设过期、统一用户标识方可稳健使用。453 收藏