Go语言技术文章
-
 从手机号后四位和日期函数查询变慢切入,讲清 MySQL 8.x 函数索引、生成列、表达式匹配、EXPLAIN 验证、DDL 风险和上线检查。381 收藏
从手机号后四位和日期函数查询变慢切入,讲清 MySQL 8.x 函数索引、生成列、表达式匹配、EXPLAIN 验证、DDL 风险和上线检查。381 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · InnoDB · 故障排查 · MySQL教程 · DBA实战 · mysql innodb 性能优化 预热 冷启动 MySQL 8.4 Buffer Pool
 从数据库重启后热点接口 P99 抖动切入,讲清 MySQL 8.x InnoDB Buffer Pool dump/load、冷启动诊断、预热脚本、参数检查和上线演练。158 收藏
从数据库重启后热点接口 P99 抖动切入,讲清 MySQL 8.x InnoDB Buffer Pool dump/load、冷启动诊断、预热脚本、参数检查和上线演练。158 收藏 -
数据库 · MySQL | 1个月前 | binlog · 故障恢复 · 备份恢复 · MySQL教程 · DBA实战 · mysql DBA binlog 备份恢复 mysqlbinlog MySQL 8.4 PITR
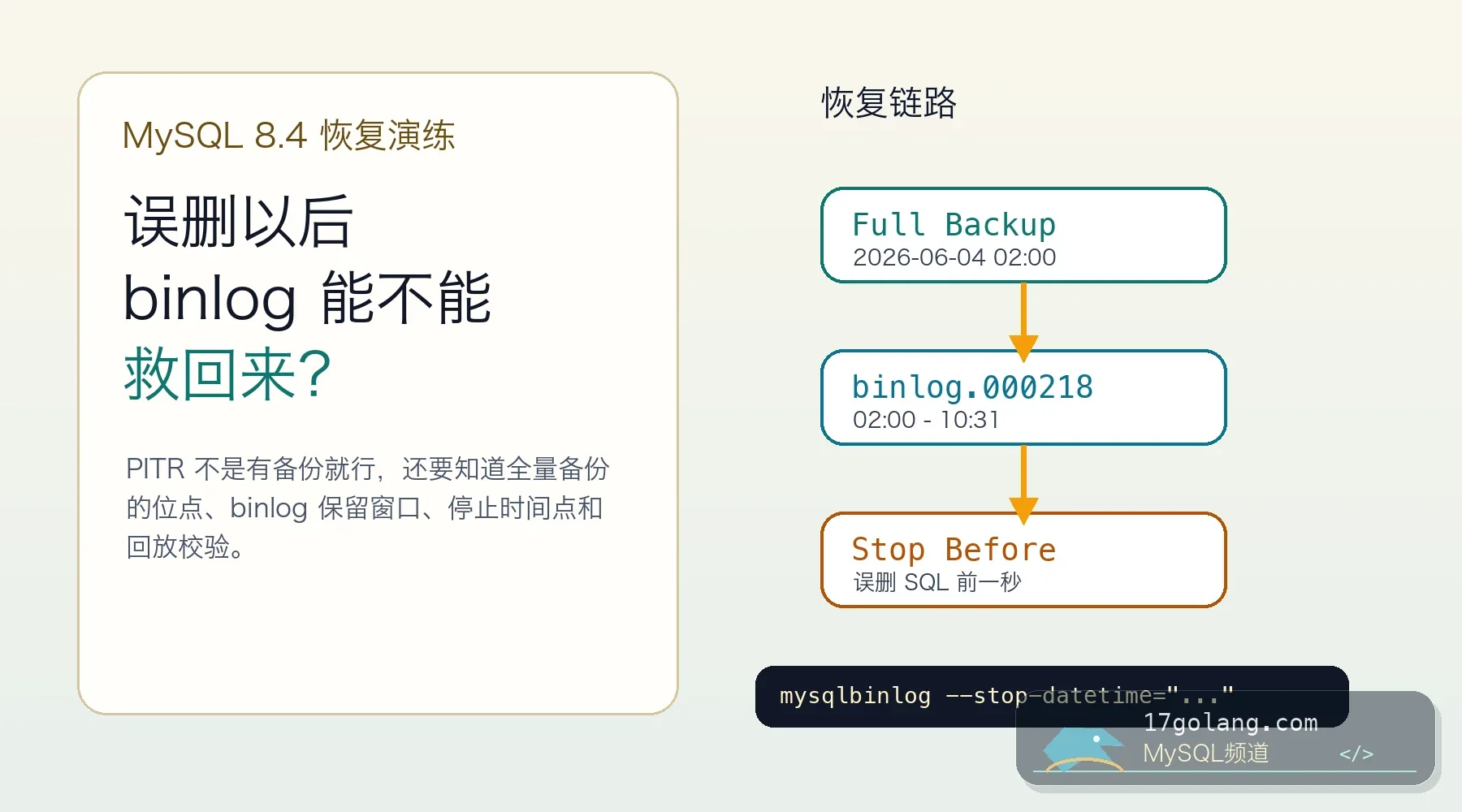 从误删订单数据的恢复演练切入,讲清 MySQL 8.x 完整备份、binlog 保留、mysqlbinlog 按时间点/位置回放、校验与上线检查。432 收藏
从误删订单数据的恢复演练切入,讲清 MySQL 8.x 完整备份、binlog 保留、mysqlbinlog 按时间点/位置回放、校验与上线检查。432 收藏 -
数据库 · MySQL | 1个月前 | 字符集 · 故障排查 · MySQL教程 · 索引优化 · 排序规则 · mysql 排序规则 索引优化 utf8mb4 collation MySQL 8.4
 从账号唯一键和昵称搜索踩坑切入,讲清 MySQL 8.x utf8mb4_0900_ai_ci、大小写/重音敏感、collation 混用、隐式转换与索引命中验证。294 收藏
从账号唯一键和昵称搜索踩坑切入,讲清 MySQL 8.x utf8mb4_0900_ai_ci、大小写/重音敏感、collation 混用、隐式转换与索引命中验证。294 收藏 -
数据库 · MySQL | 1个月前 | binlog · 主从复制 · 故障排查 · MySQL教程 · DBA实战 · mysql DBA binlog 主从复制 MySQL 8.4 复制延迟 relay log
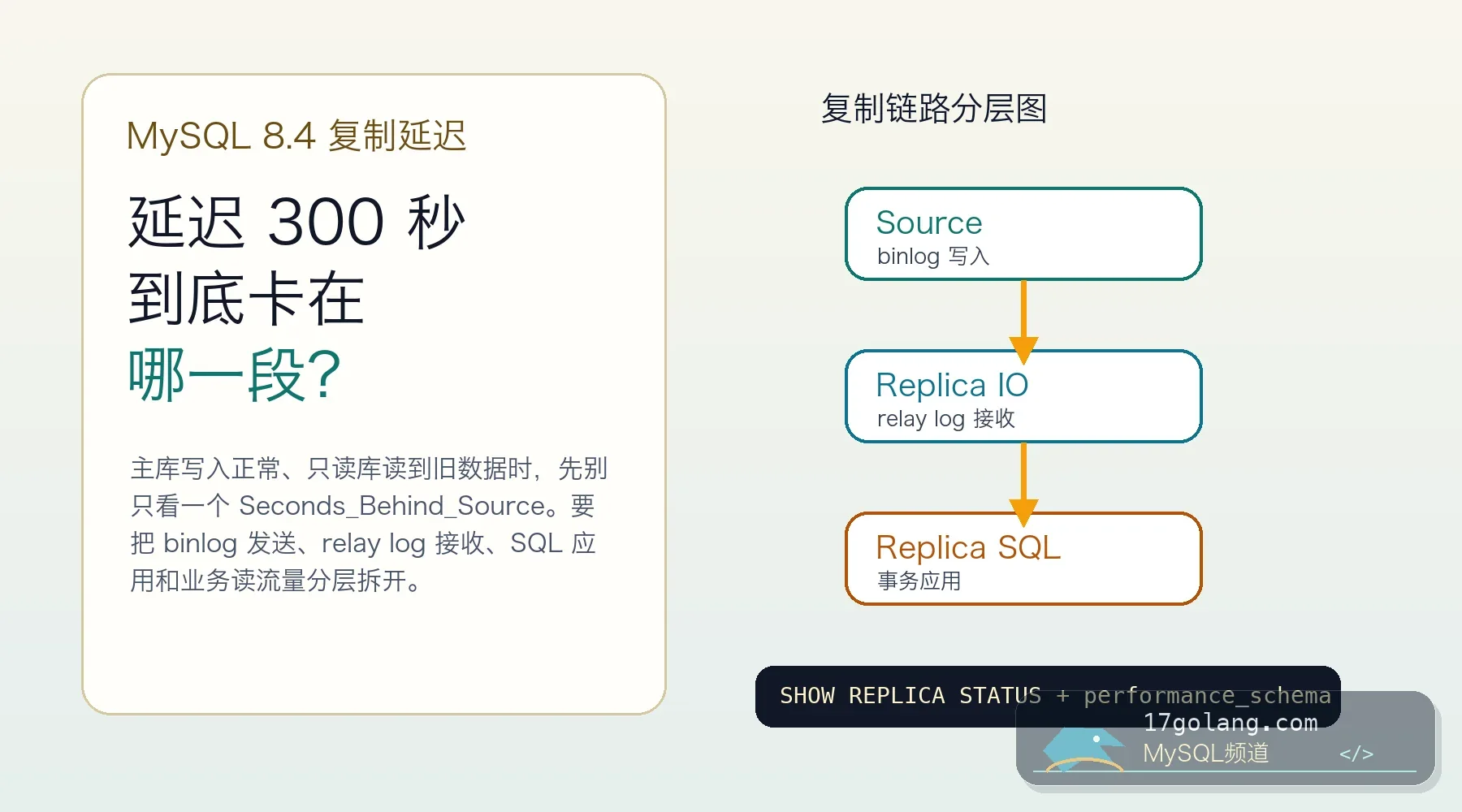 从只读库延迟导致读到旧数据的事故切入,讲清 MySQL 8.x 复制延迟如何区分 IO 接收、relay log 应用、大事务、并行复制和只读流量影响。119 收藏
从只读库延迟导致读到旧数据的事故切入,讲清 MySQL 8.x 复制延迟如何区分 IO 接收、relay log 应用、大事务、并行复制和只读流量影响。119 收藏 -
数据库 · MySQL | 1个月前 | MySQL教程 · 慢查询治理 · 索引优化 · 分区表 · DBA实战 · mysql 分区表 慢查询 索引优化 MySQL 8.4 partition pruning
 从订单历史表按月分区的慢查询切入,讲清 MySQL 8.x 分区裁剪的命中条件、失效写法、EXPLAIN PARTITIONS 验证、索引配合和上线检查。133 收藏
从订单历史表按月分区的慢查询切入,讲清 MySQL 8.x 分区裁剪的命中条件、失效写法、EXPLAIN PARTITIONS 验证、索引配合和上线检查。133 收藏 -
数据库 · MySQL | 1个月前 | 高并发 · 故障排查 · MySQL教程 · 事务隔离 · InnoDB锁 · mysql innodb 高并发 锁等待 MySQL 8.4 NOWAIT SKIP LOCKED
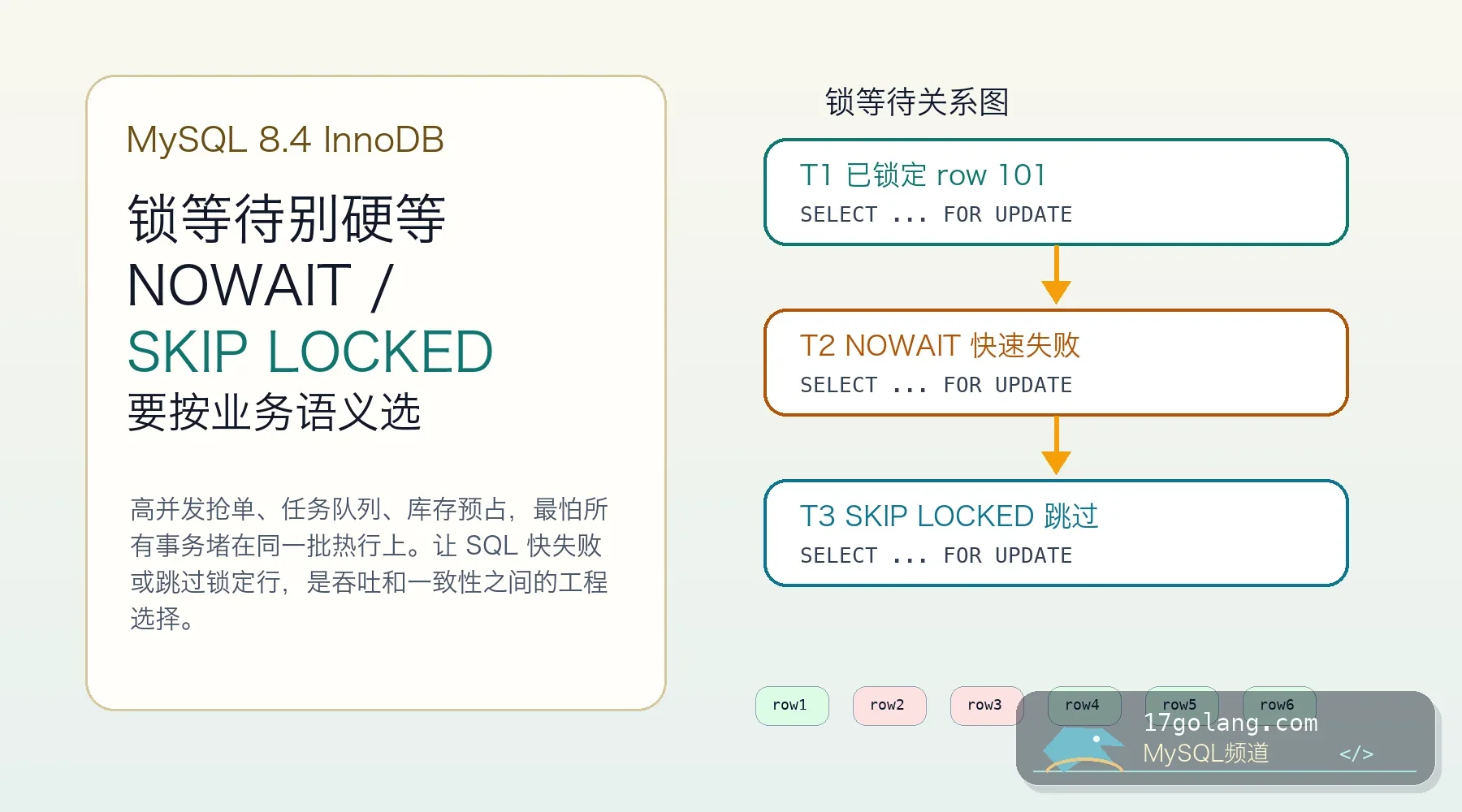 围绕高并发工单抢占和库存预占,讲清 MySQL 8.x InnoDB locking read 中 NOWAIT、SKIP LOCKED 的适用边界、复现方法、SQL 改写、锁等待诊断和上线检查。439 收藏
围绕高并发工单抢占和库存预占,讲清 MySQL 8.x InnoDB locking read 中 NOWAIT、SKIP LOCKED 的适用边界、复现方法、SQL 改写、锁等待诊断和上线检查。439 收藏 -
数据库 · MySQL | 1个月前 | MySQL教程 · 慢查询治理 · 索引优化 · JSON查询 · InnoDB实战 · mysql JSON 慢查询 索引优化 MySQL 8.4 多值索引
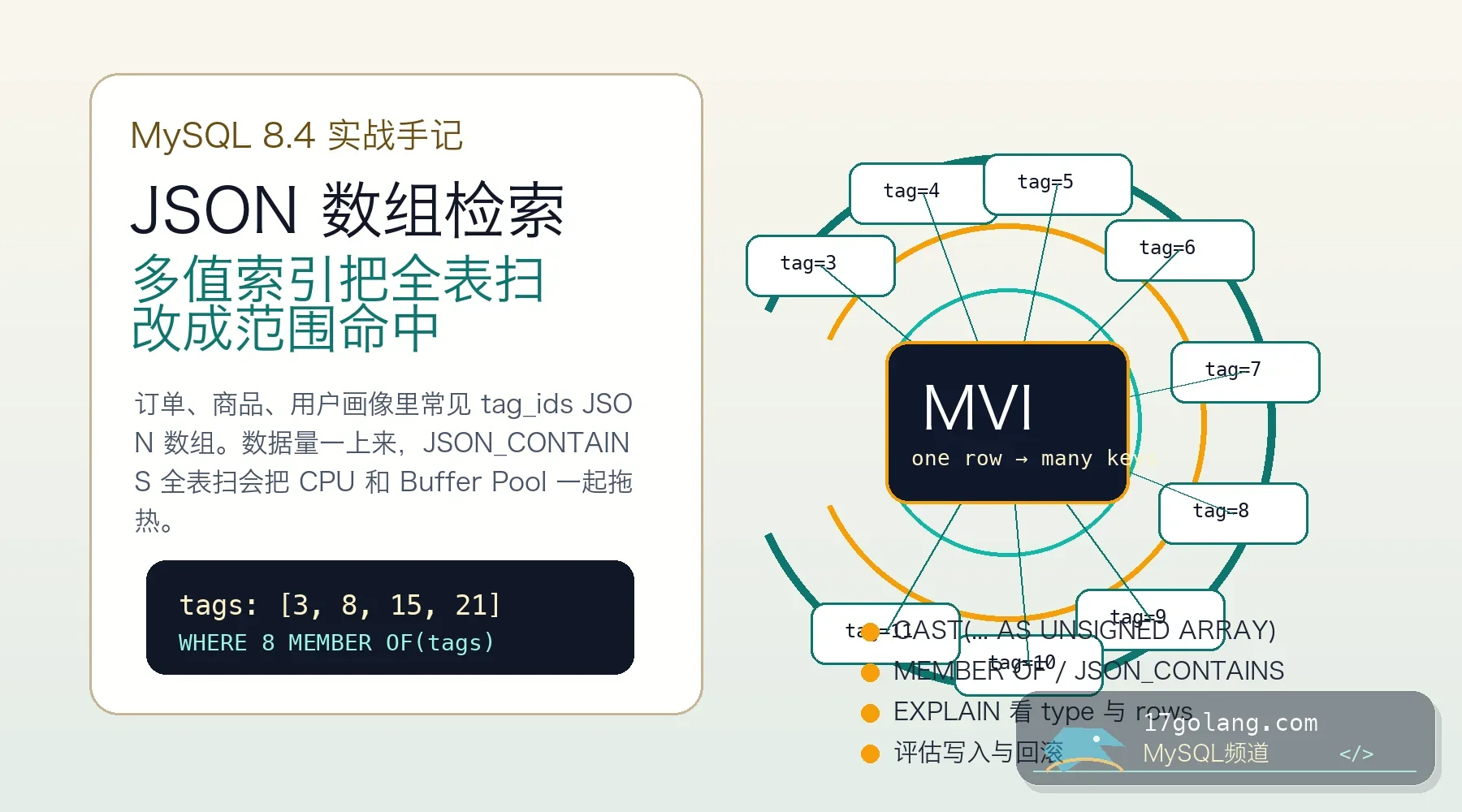 从标签检索接口慢查询切入,讲清 MySQL 8.x 多值索引如何让 JSON 数组条件命中索引,以及建索引、EXPLAIN 验证、写入成本和上线回滚检查。291 收藏
从标签检索接口慢查询切入,讲清 MySQL 8.x 多值索引如何让 JSON 数组条件命中索引,以及建索引、EXPLAIN 验证、写入成本和上线回滚检查。291 收藏 -
数据库 · MySQL | 1个月前 | InnoDB · 故障排查 · 生产实践 · MySQL教程 · 事务隔离 · mysql innodb Purge Lag History List 长事务 Undo
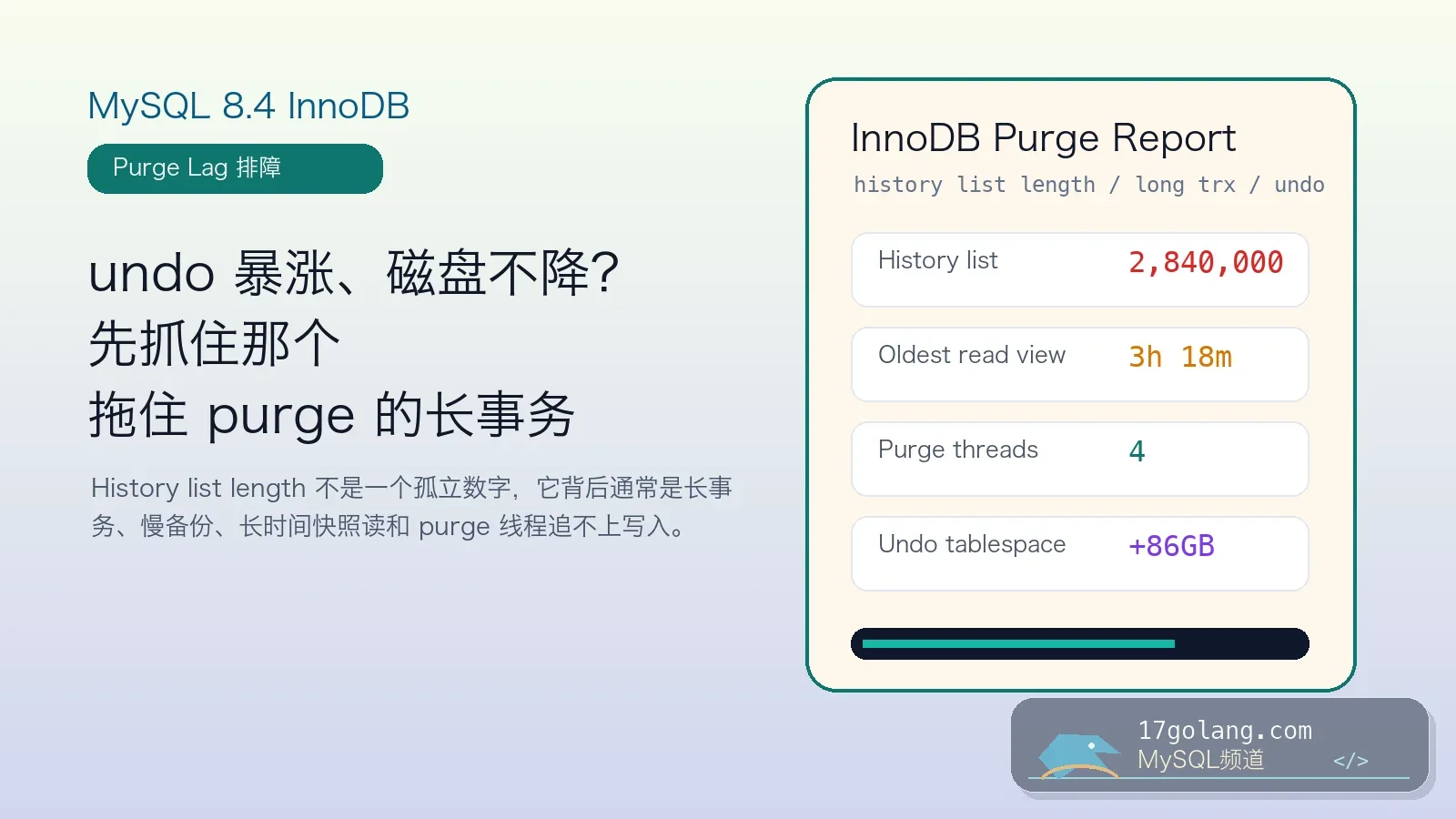 从 MySQL 8.4 InnoDB purge lag 入手,讲清 history list length、长事务、undo 暴涨和 purge 参数的生产排障方法。326 收藏
从 MySQL 8.4 InnoDB purge lag 入手,讲清 history list length、长事务、undo 暴涨和 purge 参数的生产排障方法。326 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · 执行计划 · 生产实践 · MySQL教程 · 索引优化 · mysql explain 索引优化 Index Condition Pushdown ICP
 从 MySQL 8.4 Index Condition Pushdown 入手,讲清为什么用了索引仍可能回表拖慢,以及如何用 EXPLAIN、optimizer_switch 和线上指标验证 ICP 收益。179 收藏
从 MySQL 8.4 Index Condition Pushdown 入手,讲清为什么用了索引仍可能回表拖慢,以及如何用 EXPLAIN、optimizer_switch 和线上指标验证 ICP 收益。179 收藏 -
 从 MySQL 8.4 Skip Scan 入手,讲清复合索引没有左前缀条件时优化器为什么仍可能走索引,以及如何用 EXPLAIN ANALYZE 和 optimizer_switch 做生产验证。189 收藏
从 MySQL 8.4 Skip Scan 入手,讲清复合索引没有左前缀条件时优化器为什么仍可能走索引,以及如何用 EXPLAIN ANALYZE 和 optimizer_switch 做生产验证。189 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · 执行计划 · 生产实践 · MySQL教程 · 数据库运维 · mysql 直方图 EXPLAIN ANALYZE Histogram 优化器统计信息
 从 MySQL 8.4 直方图统计信息入手,讲清数据分布倾斜如何影响优化器行数估算,以及如何创建、验证和回滚 histogram。419 收藏
从 MySQL 8.4 直方图统计信息入手,讲清数据分布倾斜如何影响优化器行数估算,以及如何创建、验证和回滚 histogram。419 收藏 -
 从 MySQL Invisible Indexes 入手,讲清如何用不可见索引灰度验证删索引风险,避免直接 DROP INDEX 带来的线上慢查询和回滚成本。388 收藏
从 MySQL Invisible Indexes 入手,讲清如何用不可见索引灰度验证删索引风险,避免直接 DROP INDEX 带来的线上慢查询和回滚成本。388 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · InnoDB · 生产实践 · MySQL教程 · 数据库运维 · mysql redo log innodb 性能优化 innodb_redo_log_capacity
 从 MySQL 8.4 的 innodb_redo_log_capacity 入手,讲清 redo log 容量、检查点压力、写入抖动和崩溃恢复时间之间的取舍,并给出上线检查清单。382 收藏
从 MySQL 8.4 的 innodb_redo_log_capacity 入手,讲清 redo log 容量、检查点压力、写入抖动和崩溃恢复时间之间的取舍,并给出上线检查清单。382 收藏 -
数据库 · MySQL | 1个月前 | MySQL教程 · 数据库实战 · 在线DDL · ALTER TABLE · 元数据锁 · mysql innodb MySQL 8 在线 DDL ALTER TABLE MDL 元数据锁 INSTANT
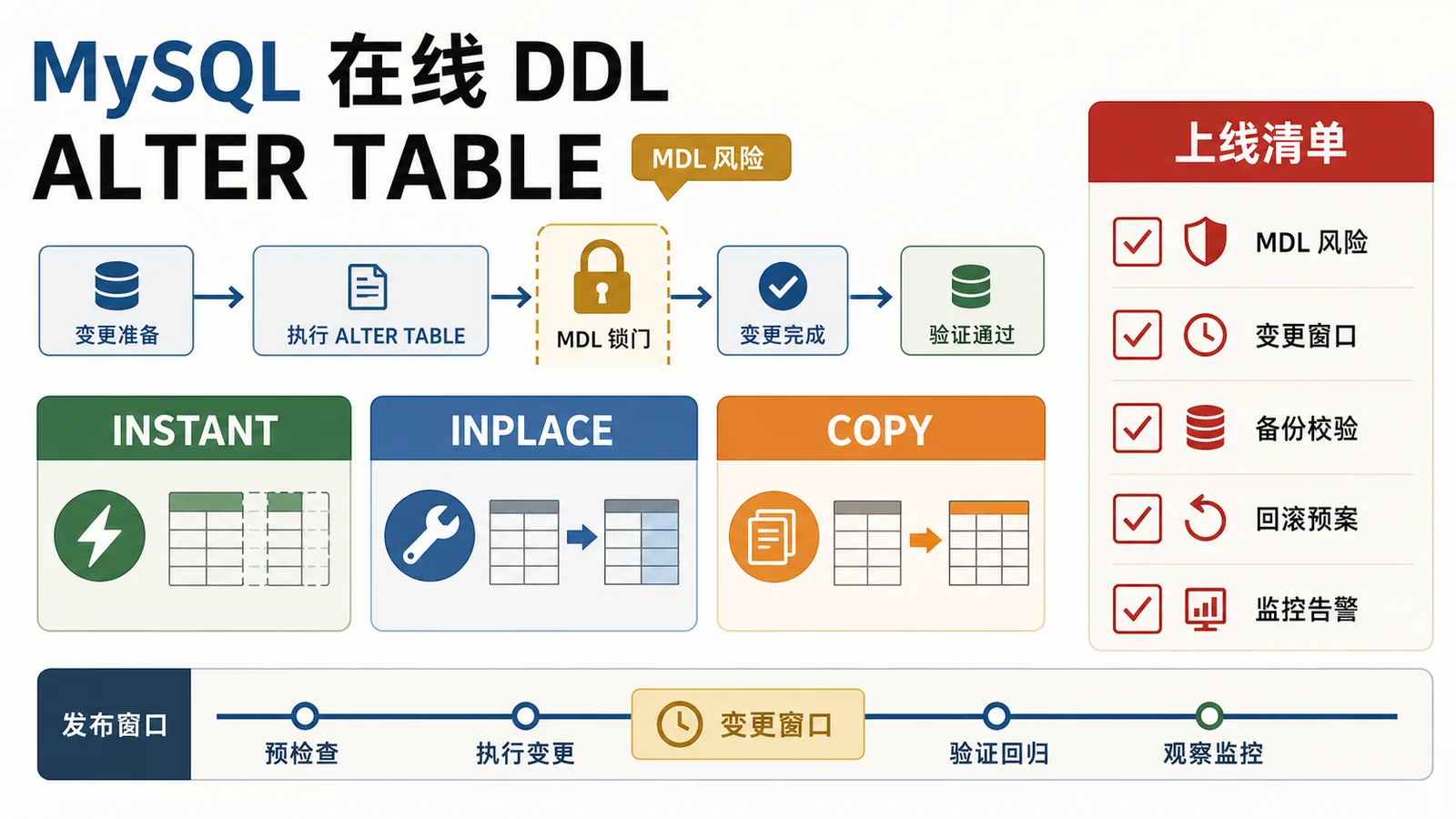 从订单大表加字段出发,讲清 MySQL 8.x 在线 DDL、ALGORITHM=INSTANT/INPLACE/COPY、metadata lock、row version 上限、复制延迟和上线复查。323 收藏
从订单大表加字段出发,讲清 MySQL 8.x 在线 DDL、ALGORITHM=INSTANT/INPLACE/COPY、metadata lock、row version 上限、复制延迟和上线复查。323 收藏