Go语言技术文章
-
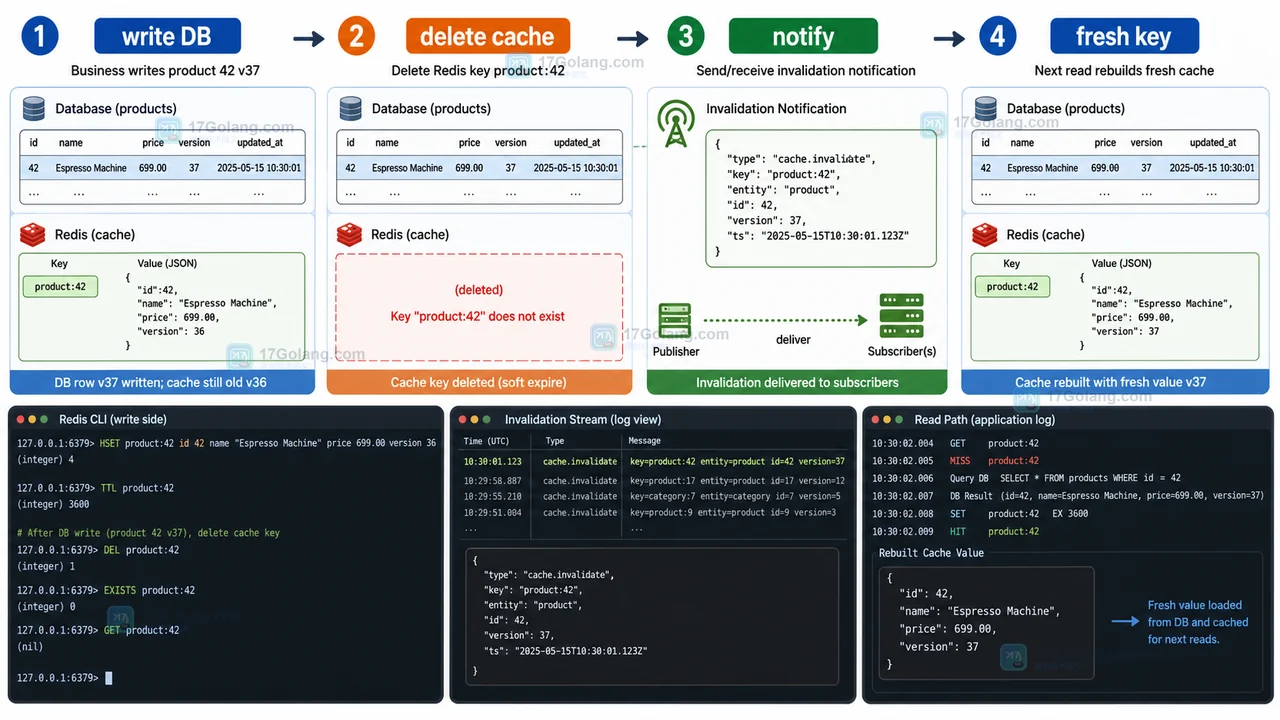 从 Redis 缓存治理趋势出发,分析单一 TTL 的不足,给出软过期、写侧失效通知、新鲜度指标和渐进落地路径,帮助团队在高峰流量下减少脏读窗口。280 收藏
从 Redis 缓存治理趋势出发,分析单一 TTL 的不足,给出软过期、写侧失效通知、新鲜度指标和渐进落地路径,帮助团队在高峰流量下减少脏读窗口。280 收藏 -
数据库 · MySQL | 1天前 | MySQL · InnoDB · 性能排查 · 故障复盘 · 长事务 · mysql PURGE 长事务 Undo history list length 写入延迟
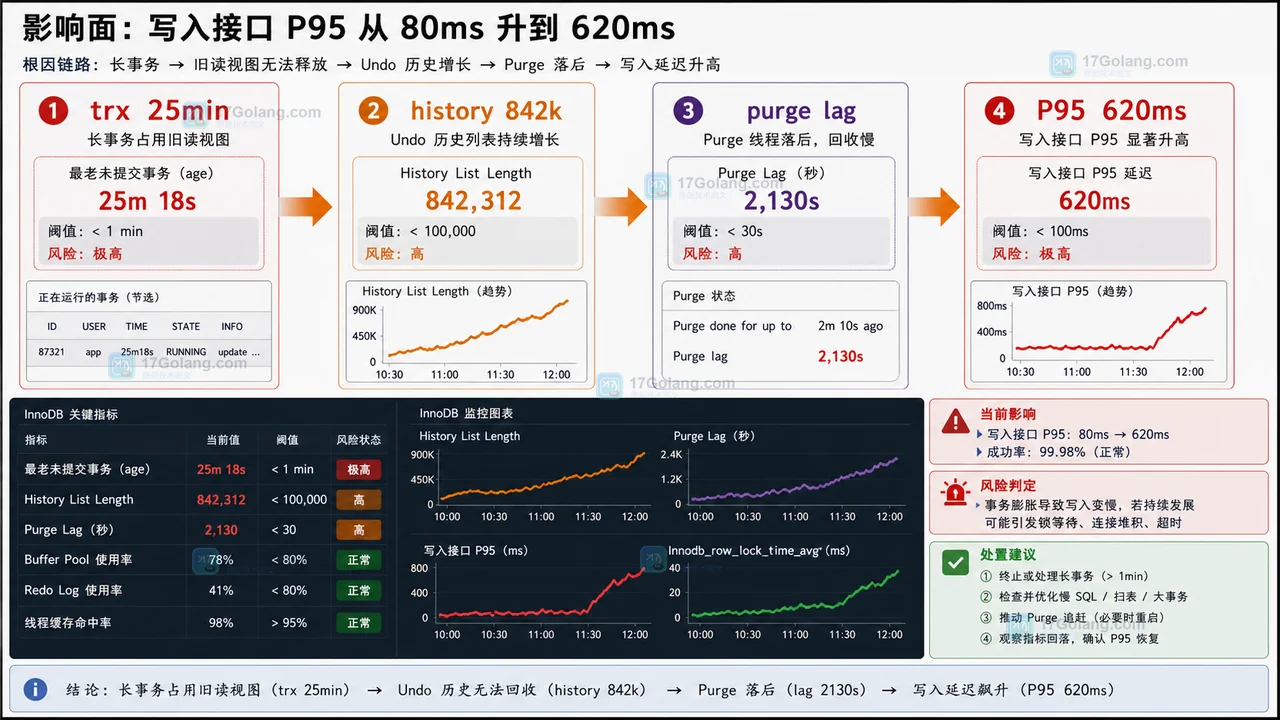 复盘一次 MySQL 写入延迟突然升高的问题:从影响面和时间线入手,通过 innodb_trx、history list length 和 purge 状态定位长事务拖住 undo 清理,并给出修复和防复发清单。242 收藏
复盘一次 MySQL 写入延迟突然升高的问题:从影响面和时间线入手,通过 innodb_trx、history list length 和 purge 状态定位长事务拖住 undo 清理,并给出修复和防复发清单。242 收藏 -
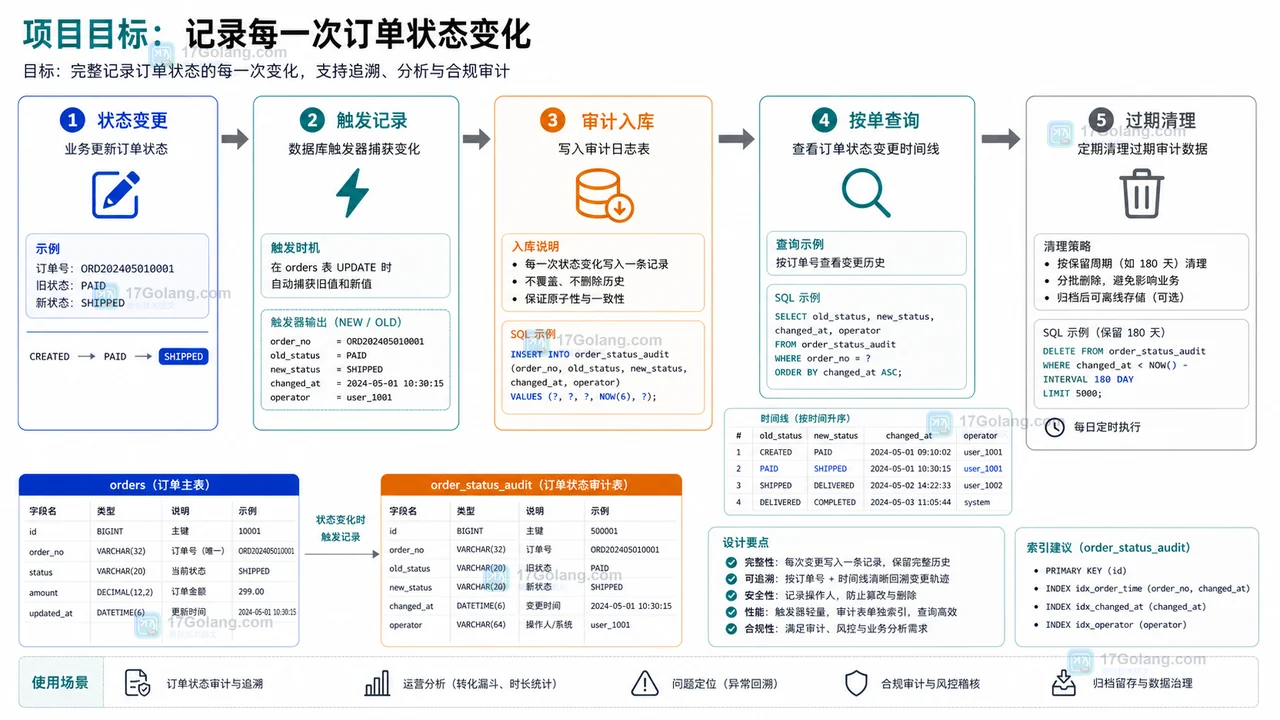 本文从零构建一个 MySQL 审计日志小项目:用订单表、审计表和触发器记录状态变更,演示本地运行、按订单查询、索引设计和过期清理。486 收藏
本文从零构建一个 MySQL 审计日志小项目:用订单表、审计表和触发器记录状态变更,演示本地运行、按订单查询、索引设计和过期清理。486 收藏 -
数据库 · MySQL | 1天前 | MySQL · 磁盘空间 · 故障复盘 · 临时表 · 报表优化 · mysql 临时表 Created_tmp_disk_tables 磁盘打满 报表接口 故障复盘
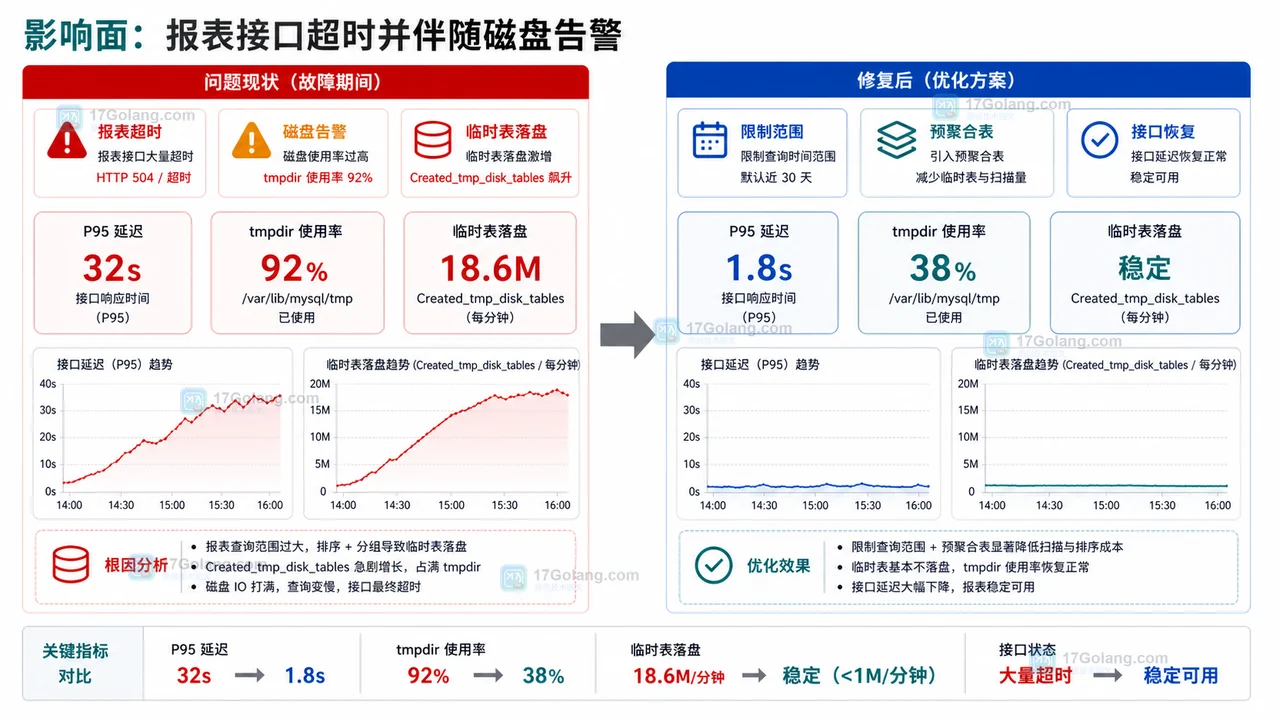 本文用一次报表接口超时故障复盘说明 MySQL 临时表打满磁盘的排查过程:从影响面、时间线、触发 SQL、根因定位到临时止血和防复发措施。114 收藏
本文用一次报表接口超时故障复盘说明 MySQL 临时表打满磁盘的排查过程:从影响面、时间线、触发 SQL、根因定位到临时止血和防复发措施。114 收藏 -
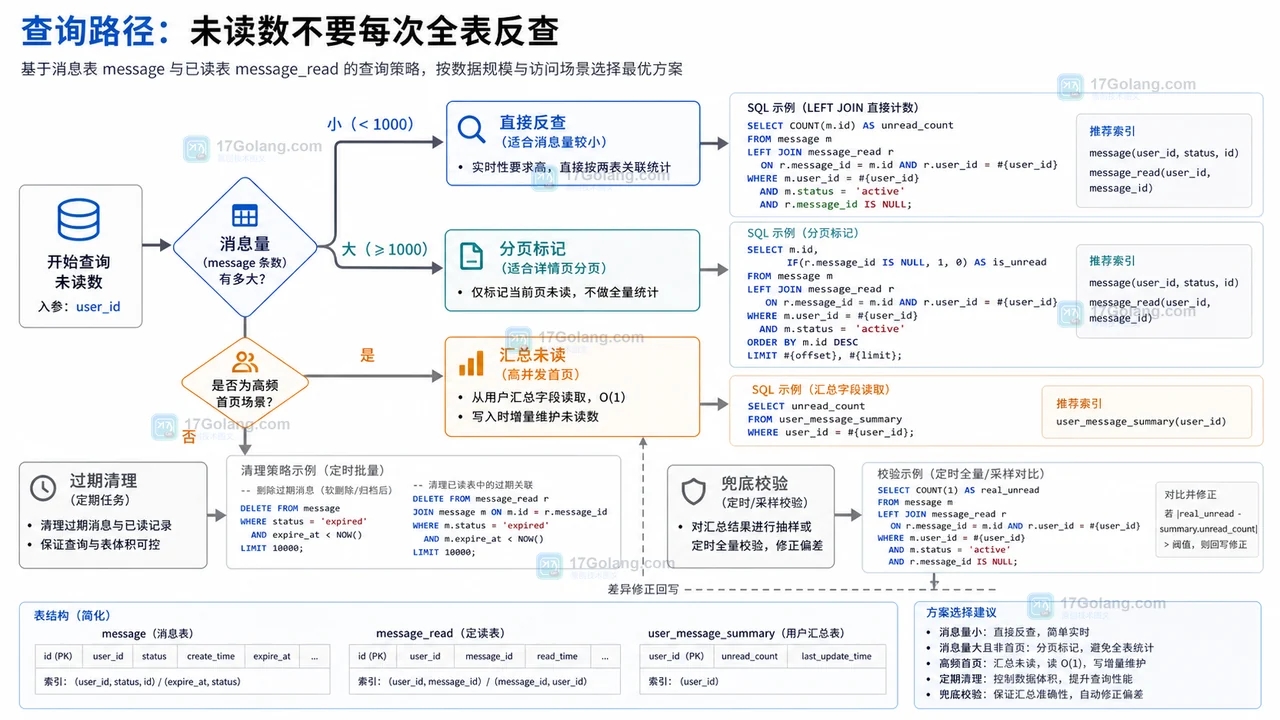 本文按数据生命周期说明 MySQL 消息已读表设计:消息如何产生,已读记录如何去重写入,未读数如何查询,重复点击和并发如何处理,以及历史数据如何清理。243 收藏
本文按数据生命周期说明 MySQL 消息已读表设计:消息如何产生,已读记录如何去重写入,未读数如何查询,重复点击和并发如何处理,以及历史数据如何清理。243 收藏 -
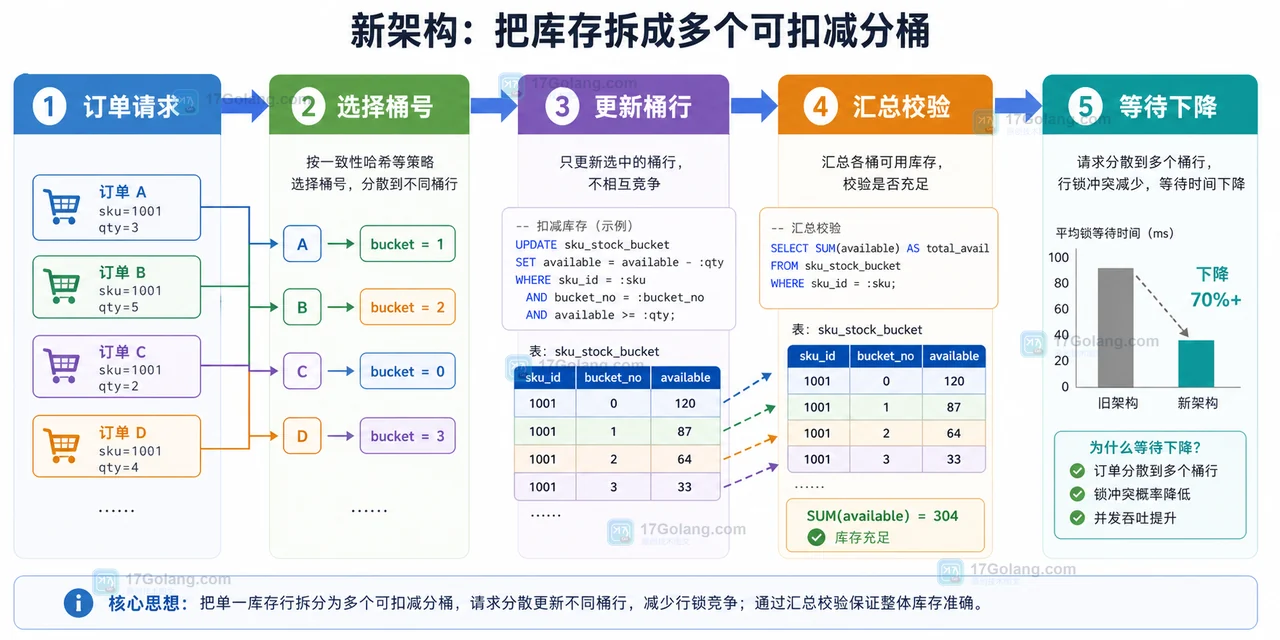 本文从大促库存扣减的热点行争用出发,分析单行库存模型的锁等待瓶颈,演进到分桶库存、汇总校验和灰度上线方案,并说明取舍与验证指标。141 收藏
本文从大促库存扣减的热点行争用出发,分析单行库存模型的锁等待瓶颈,演进到分桶库存、汇总校验和灰度上线方案,并说明取舍与验证指标。141 收藏 -
数据库 · Redis | 2天前 | Redis · 缓存治理 · Keyspace Notifications · 过期事件 · redis Pub/Sub Keyspace Notifications 过期事件 缓存监听 补偿任务
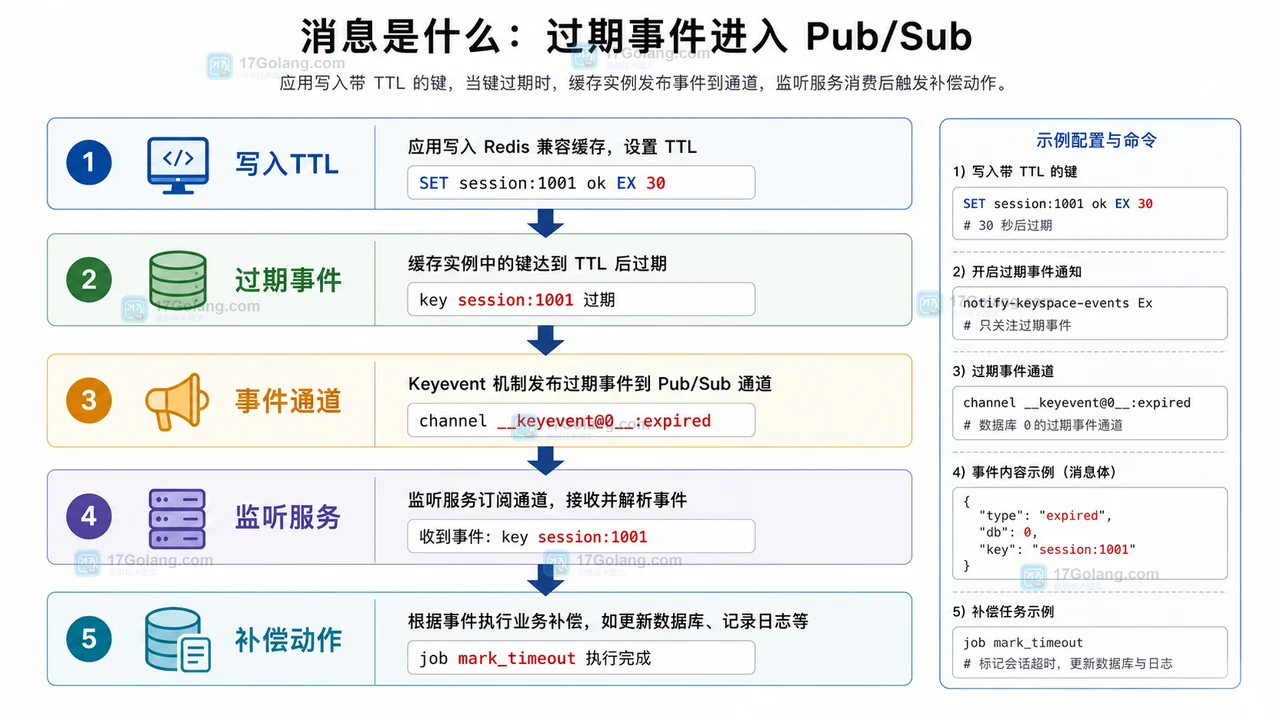 本文用 Redis Keyspace Notifications 演示如何监听过期 Key,配置 notify-keyspace-events,接收 __keyevent@0__:expired 事件,并说明事件通知的丢失风险与补扫兜底做法。181 收藏
本文用 Redis Keyspace Notifications 演示如何监听过期 Key,配置 notify-keyspace-events,接收 __keyevent@0__:expired 事件,并说明事件通知的丢失风险与补扫兜底做法。181 收藏 -
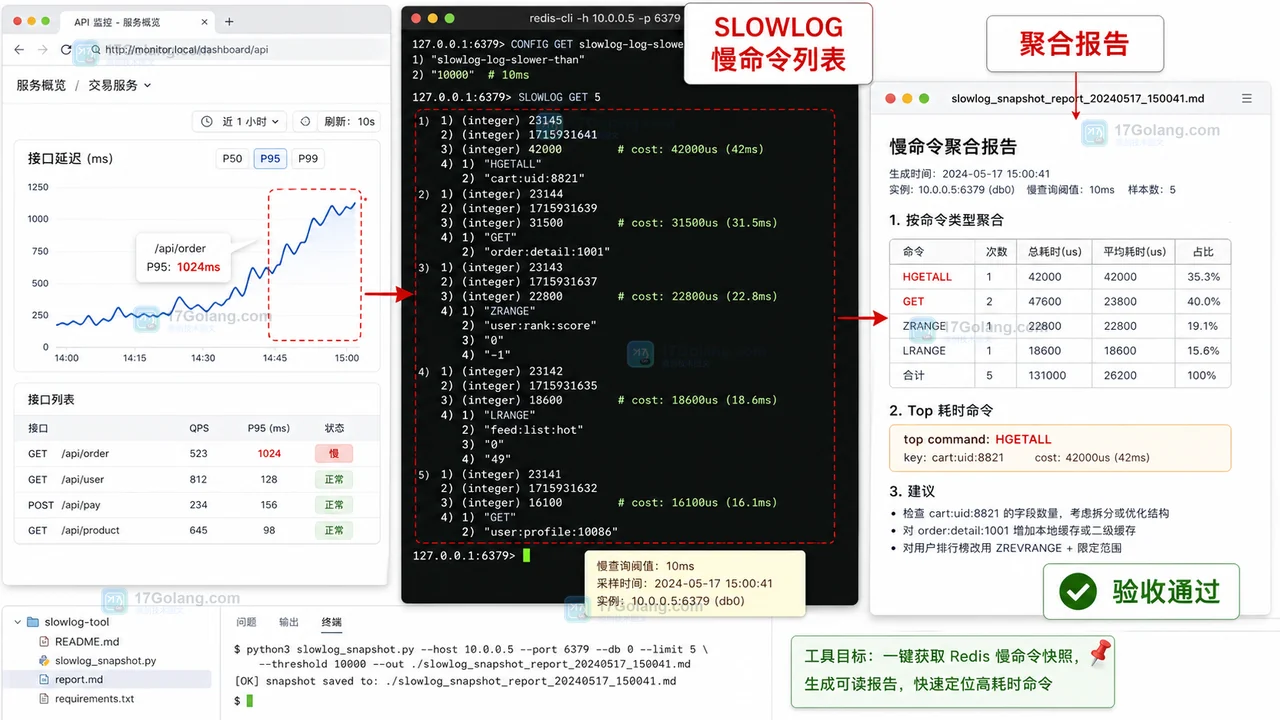 从零做一个 Redis 慢命令快照小工具,采集 SLOWLOG 样本,解析命令耗时和 Key 线索,按命令类型聚合成 Markdown 报告,用于接口延迟排查和上线前验收。501 收藏
从零做一个 Redis 慢命令快照小工具,采集 SLOWLOG 样本,解析命令耗时和 Key 线索,按命令类型聚合成 Markdown 报告,用于接口延迟排查和上线前验收。501 收藏 -
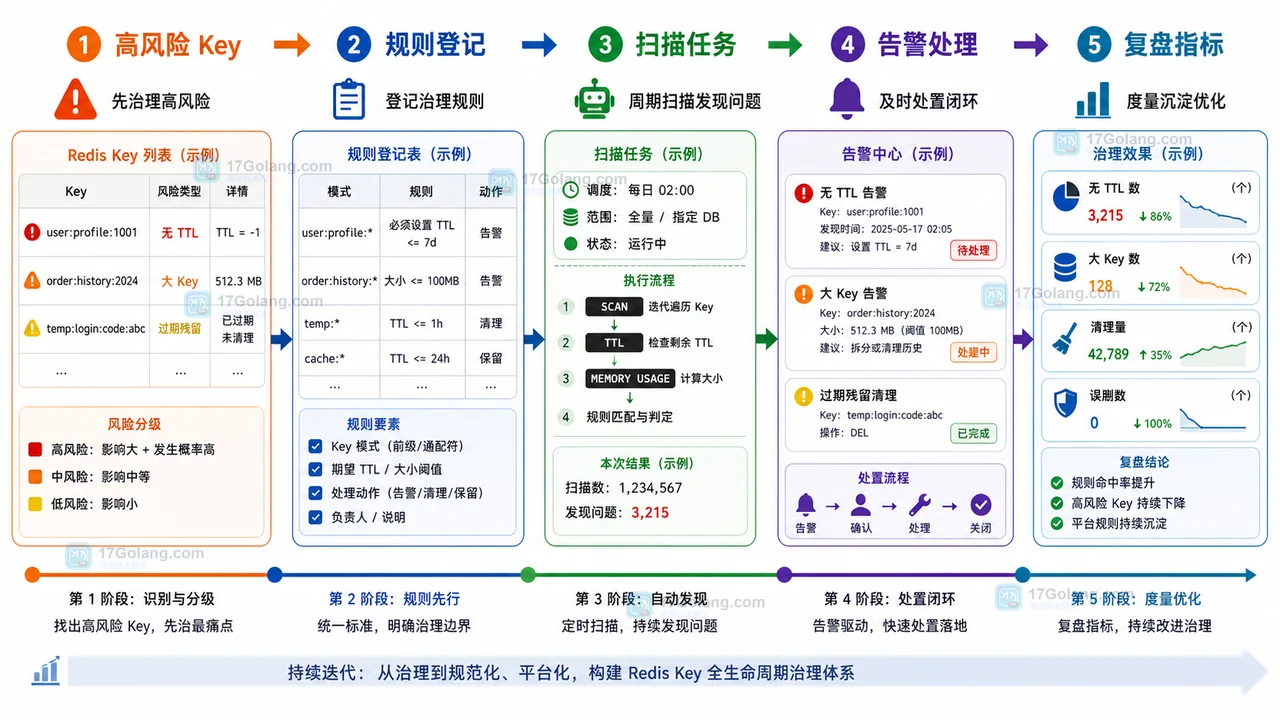 从 Redis Key 生命周期治理趋势入手,分析散落 Key、无 TTL、大 Key 和过期策略带来的问题,给出规则登记、扫描任务、告警处理、复盘指标的渐进式采用路径。400 收藏
从 Redis Key 生命周期治理趋势入手,分析散落 Key、无 TTL、大 Key 和过期策略带来的问题,给出规则登记、扫描任务、告警处理、复盘指标的渐进式采用路径。400 收藏 -
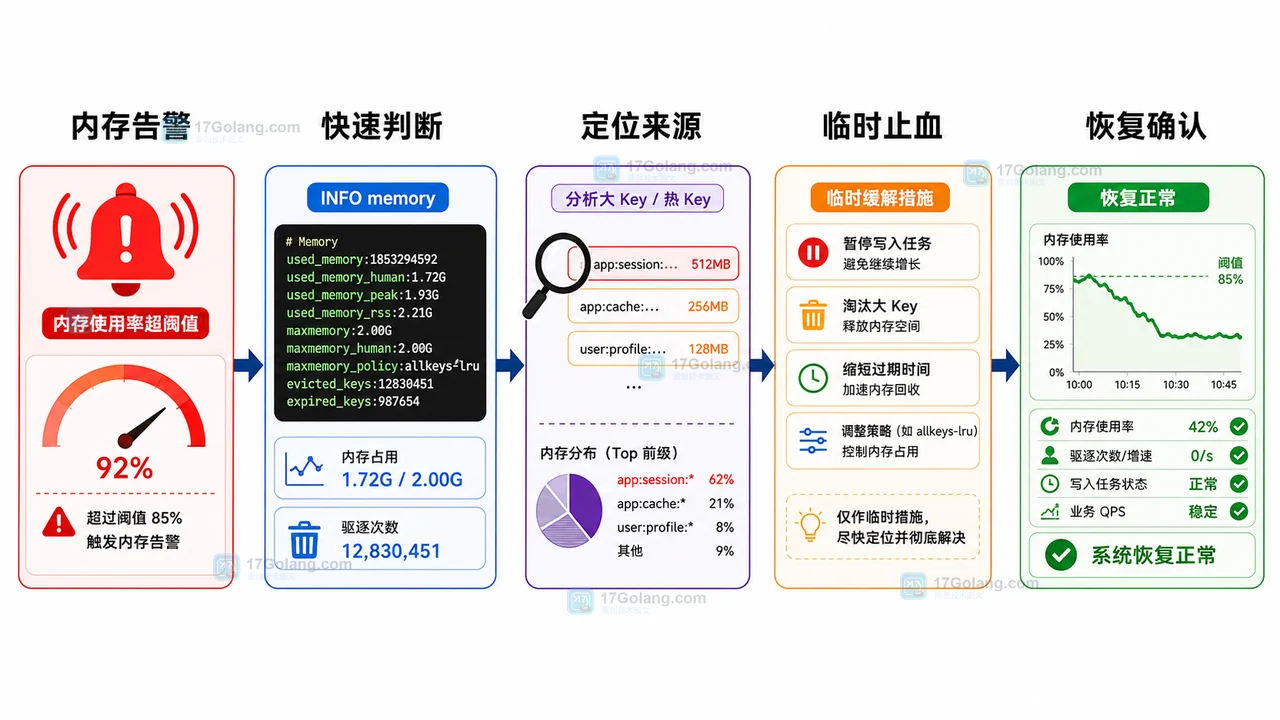 面向线上 Redis 内存告警的运行手册,覆盖触发信号、INFO memory 快速判断、bigkeys 排查、maxmemory 与淘汰策略检查、临时止血、回滚和复盘清单。313 收藏
面向线上 Redis 内存告警的运行手册,覆盖触发信号、INFO memory 快速判断、bigkeys 排查、maxmemory 与淘汰策略检查、临时止血、回滚和复盘清单。313 收藏