Go教程技术文章
-
 Go项目分层应以internal为根目录,因其提供包级访问控制;domain层须零依赖,用自定义类型封装time.Time;application层只处理domain错误,infrastructure层负责错误转换与具体实现。339 收藏
Go项目分层应以internal为根目录,因其提供包级访问控制;domain层须零依赖,用自定义类型封装time.Time;application层只处理domain错误,infrastructure层负责错误转换与具体实现。339 收藏 -
 Golang利用gorilla/websocket库可高效构建WebSocket实时通信服务,通过HTTP服务器升级连接,使用Hub管理客户端注册、消息广播与连接维护。339 收藏
Golang利用gorilla/websocket库可高效构建WebSocket实时通信服务,通过HTTP服务器升级连接,使用Hub管理客户端注册、消息广播与连接维护。339 收藏 -
 答案:Golang微服务异步通信主要通过消息队列(如RabbitMQ)、Kafka、NATS及gRPC结合消息队列实现;RabbitMQ支持可靠消息传递,Kafka适用于高吞吐场景,NATS轻量实时,gRPC结合队列可实现异步解耦,配合Go的goroutine与channel构建高效系统。339 收藏
答案:Golang微服务异步通信主要通过消息队列(如RabbitMQ)、Kafka、NATS及gRPC结合消息队列实现;RabbitMQ支持可靠消息传递,Kafka适用于高吞吐场景,NATS轻量实时,gRPC结合队列可实现异步解耦,配合Go的goroutine与channel构建高效系统。339 收藏 -
 单机golang.org/x/time/rate.Limiter不能用于分布式场景,因其状态仅存于内存,多实例间不共享,导致实际QPS远超设定值;必须用Redis等外部存储配合Lua原子脚本实现分布式令牌桶。339 收藏
单机golang.org/x/time/rate.Limiter不能用于分布式场景,因其状态仅存于内存,多实例间不共享,导致实际QPS远超设定值;必须用Redis等外部存储配合Lua原子脚本实现分布式令牌桶。339 收藏 -
 TinyGo编译失败主因是main.go位置错误或包名不符:必须置于go.mod同级根目录,文件名严格为main.go且首行为packagemain;tinygobuild需在该目录执行,不支持子路径;target名称须精确匹配(如raspberry-pi-pico非pico),否则烧录后板子无响应。339 收藏
TinyGo编译失败主因是main.go位置错误或包名不符:必须置于go.mod同级根目录,文件名严格为main.go且首行为packagemain;tinygobuild需在该目录执行,不支持子路径;target名称须精确匹配(如raspberry-pi-pico非pico),否则烧录后板子无响应。339 收藏 -
 Go1.17+支持(*[N]T)(s)将slice转为数组指针,要求len(s)≥N,否则运行时panic;此前只能用unsafe或copy,后者最安全稳定。339 收藏
Go1.17+支持(*[N]T)(s)将slice转为数组指针,要求len(s)≥N,否则运行时panic;此前只能用unsafe或copy,后者最安全稳定。339 收藏 -
 协程池是为控制资源争抢和避免goroutine泄漏而设的显式限流机制,非所有场景都适用;ants库最成熟,手写需注意缓冲channel、panic捕获及关闭顺序。339 收藏
协程池是为控制资源争抢和避免goroutine泄漏而设的显式限流机制,非所有场景都适用;ants库最成熟,手写需注意缓冲channel、panic捕获及关闭顺序。339 收藏 -
 最稳妥方式是用sync.WaitGroup+sync.Mutex保护错误切片:声明musync.Mutex和errs[]error,每个goroutine执行完后加锁append错误,WaitGroup等待全部完成再返回errs。339 收藏
最稳妥方式是用sync.WaitGroup+sync.Mutex保护错误切片:声明musync.Mutex和errs[]error,每个goroutine执行完后加锁append错误,WaitGroup等待全部完成再返回errs。339 收藏 -
 sync.Once.Do传入函数panic后永远失效,因done字段被原子置1且不可逆,不捕获panic也不重试;须在闭包内defer/recover或改用error返回路径,并避免闭包捕获外部可变变量。339 收藏
sync.Once.Do传入函数panic后永远失效,因done字段被原子置1且不可逆,不捕获panic也不重试;须在闭包内defer/recover或改用error返回路径,并避免闭包捕获外部可变变量。339 收藏 -
 围绕 Go 1.24 正式支持的泛型类型别名,讲清 type Alias[T] = ... 的语义、约束写法、API 迁移、兼容测试和公共库使用边界。339 收藏
围绕 Go 1.24 正式支持的泛型类型别名,讲清 type Alias[T] = ... 的语义、约束写法、API 迁移、兼容测试和公共库使用边界。339 收藏 -
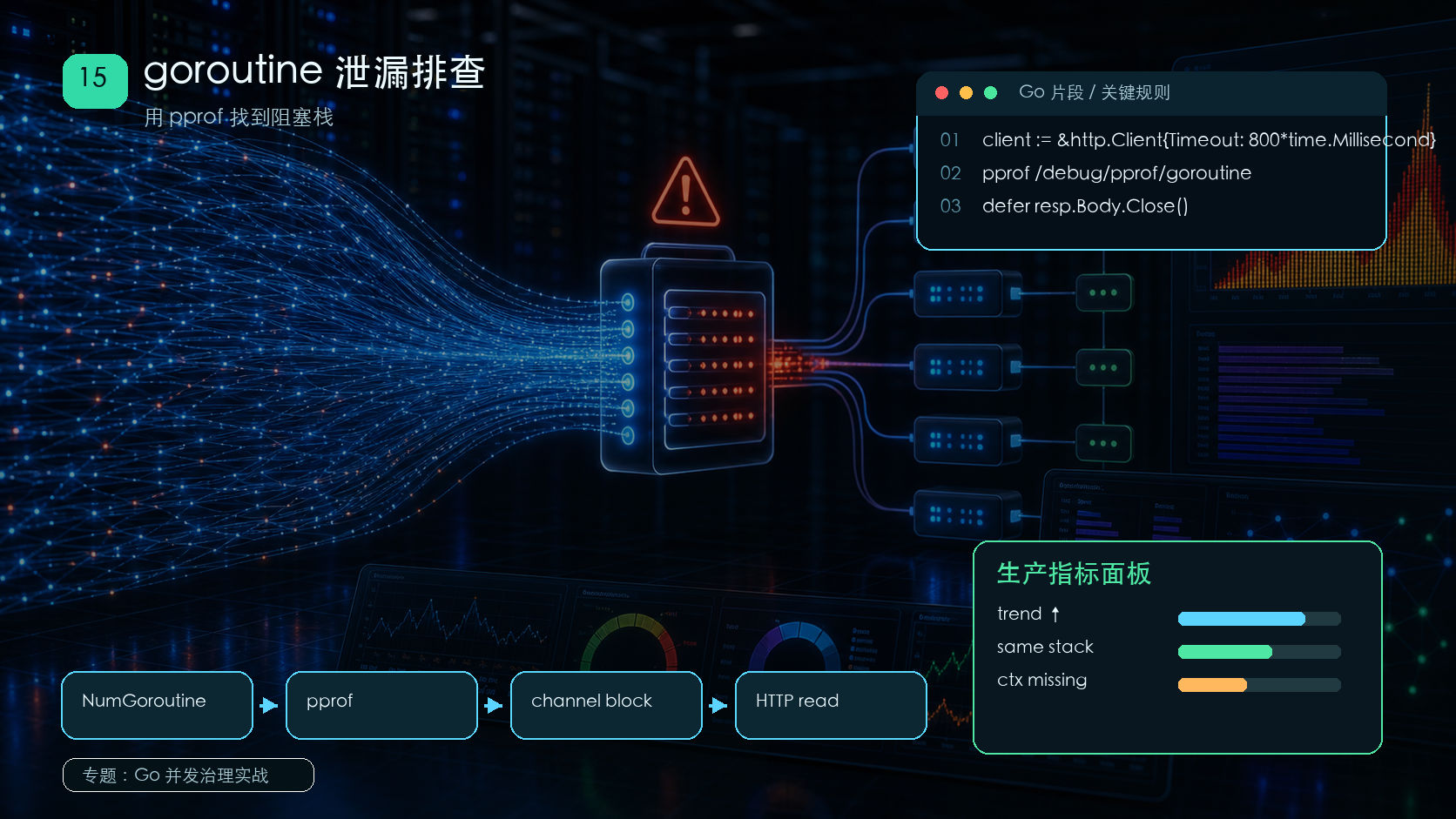 通过 goroutine profile、阻塞栈和请求路径定位泄漏来源。339 收藏
通过 goroutine profile、阻塞栈和请求路径定位泄漏来源。339 收藏 -
 推荐json.NewDecoder而非json.Unmarshal,因其流式解析不缓存全文、内存友好,且报错含具体行号便于调试;json.Unmarshal需全量加载字节切片,大文件易致内存暴涨且仅报偏移量。338 收藏
推荐json.NewDecoder而非json.Unmarshal,因其流式解析不缓存全文、内存友好,且报错含具体行号便于调试;json.Unmarshal需全量加载字节切片,大文件易致内存暴涨且仅报偏移量。338 收藏 -
 Gostruct字段顺序影响内存占用:按类型大小对齐填充,大字段优先排列可减少padding;interface{}比*T多8字节因含类型信息头;CGO需统一struct对齐避免崩溃。338 收藏
Gostruct字段顺序影响内存占用:按类型大小对齐填充,大字段优先排列可减少padding;interface{}比*T多8字节因含类型信息头;CGO需统一struct对齐避免崩溃。338 收藏 -
 Go的作用域由词法块决定:变量在哪个{}内声明,就仅在该块及内嵌块中可见;包级变量全包可访问,首字母大写才导出;:=易引发遮蔽;if/for等语句的{}是独立作用域;包级变量按源码顺序初始化,依赖需谨慎。338 收藏
Go的作用域由词法块决定:变量在哪个{}内声明,就仅在该块及内嵌块中可见;包级变量全包可访问,首字母大写才导出;:=易引发遮蔽;if/for等语句的{}是独立作用域;包级变量按源码顺序初始化,依赖需谨慎。338 收藏 -
 strings.TrimSpace只删除首尾Unicode空白符,不处理中间空格;如需清理中间空格,应按需选用strings.Fields+Join、strings.Map或ReplaceAll等方法。338 收藏
strings.TrimSpace只删除首尾Unicode空白符,不处理中间空格;如需清理中间空格,应按需选用strings.Fields+Join、strings.Map或ReplaceAll等方法。338 收藏