-

原创:知数堂在《高可用 | Xenon:后 MHA 时代的选择》一文中,我们对 Xenon 的实现原理、应用场景等做了简要介绍。文章发布后,社区小伙伴都在咨询 Xenon 如何与 MySQL 配合使用?本文来自知数
-

MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高InnoDB 引擎执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数count(id) i
-

近日,超聚变服务器操作系统FusionOS签署阿里巴巴开源CLA(Contribution License Agreement, 贡献许可协议), 正式与阿里云PolarDB 开源数据库社区牵手,并率先展开超聚变服务器操作系统FusionOS 22与阿里云Pol
-

写在前面import java.sql.*;这一步你可以理解为加载驱动。try{
Class.forName("com.mysql.jdbc.Driver");
}
catch(Exception e){
// 如果这里的代码执行,说明你的准备工作没做好,这种情况下你后面的代码全会
-

项目成功打包,比较高兴。需要了解的点传送门1.模块配置打开项目点击manifest.json模块配置勾选 支付、登录、分享、 ViderPlayer和自己需要用的模块填写相关配置Ctrl+s保存APP自动生成图标选择一
-
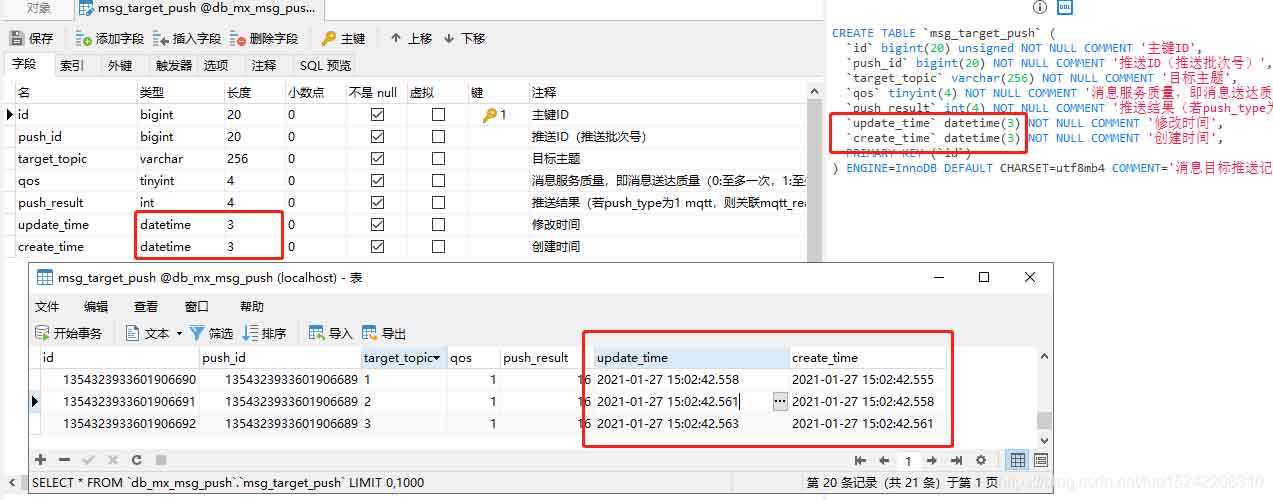
mysql datetime类型精确到毫秒、微秒
mysql里面的datetime类型的精确度是可以到 1 / 1 0 6 1/10^6 1/106秒的(即百万分之一秒,即微妙),
某些客户端(如navicat for mysql)的显示经常只能看到精确到秒,其
-

Btree 在 mysql 中的应用索引相关概念聚簇索引(clustered index) 使用innodb引擎时,每张表都有一个聚簇索引,比如我们设置的主键就是聚簇索引 聚簇是指数据的存储方式,表示数据行和相邻的
-

最近在看数据库相关的东西,重装电脑以后之前的配置都没了,为了方便直接配置XAMPP一键安装包,但是在配置过程中遇见了如下几个小问题。虽然问题不大,但是还是想记录下来,以免以后遇
-

说明
使用mysql的explain时,ken_len表示索引使用的字节数,根据这个值,就可以判断索引使用情况,特别是在组合索引的时候,判断所有的索引字段是否都被查询用到。
环境
Mysql 5.6.19-log
计算基础
-

上一篇:MySQL深入浅出(一):SQL基础、数据类型、运算符
一、 索引的设计原则
查看字段散列度/离散度:select count(distinct col_name),... from table_name,如性别的离散度比较低不适合做索引
InnoDB表
-

说明:环境mysql-master:172.16.200.43mysql-slave:172.16.200.44系统:centos7版本:MySQL5.6.35
一、基于GTID复制环境的搭建前提
主从环境的搭建和5.5没有什么区别,唯一需要注意的是:开启GTID需要启用这三
-

java连接了mysql数据库后,程序行向数据库中插入信息,代码如下:dbhelper boringdb = new dbhelper(); boringdb.connSQL(); String insert = "insert into boring(prflurl,name,post,school,reside) values('www.地址
-

mysql默认字符集是latin1,而该字符集是不支持中文的,所以导致当插入的数据含有中文时,会出现乱码或者无法插入到数据库中;在mysql实践中,建议使用utf8mb4来作为默认的字符集。mysql默认字符集是什么?mysql安装时默认设置的字符集是latin1,而它是不支持中文,所以导致当插入的数据含有中文时,会出现乱码或者无法插入到数据库中。MySQL默认字符集建议使用utf8mb4,而非utf8MySQL中utf8最多使用3个字节(bytes)来存放一个字符,因此和utf8mb3是一个意思。而ut
-

日常需求开发过程中,相信大家对于limit一定不会陌生,但是使用limit时,当偏移量(offset)非常大时,会发现查询效率越来越慢。一开始limit 2000时,可能200ms,就能查询出需要的到
-

1、单实例表的数量必须控制在2000个以内。2、表分表的数量必须控制在1024个以内。3、表必须有主键,建议使用UNSIGNED整数作为主键。潜在坑:删除无主键表,如果是row模式的主从架