MySQL技术文章
-
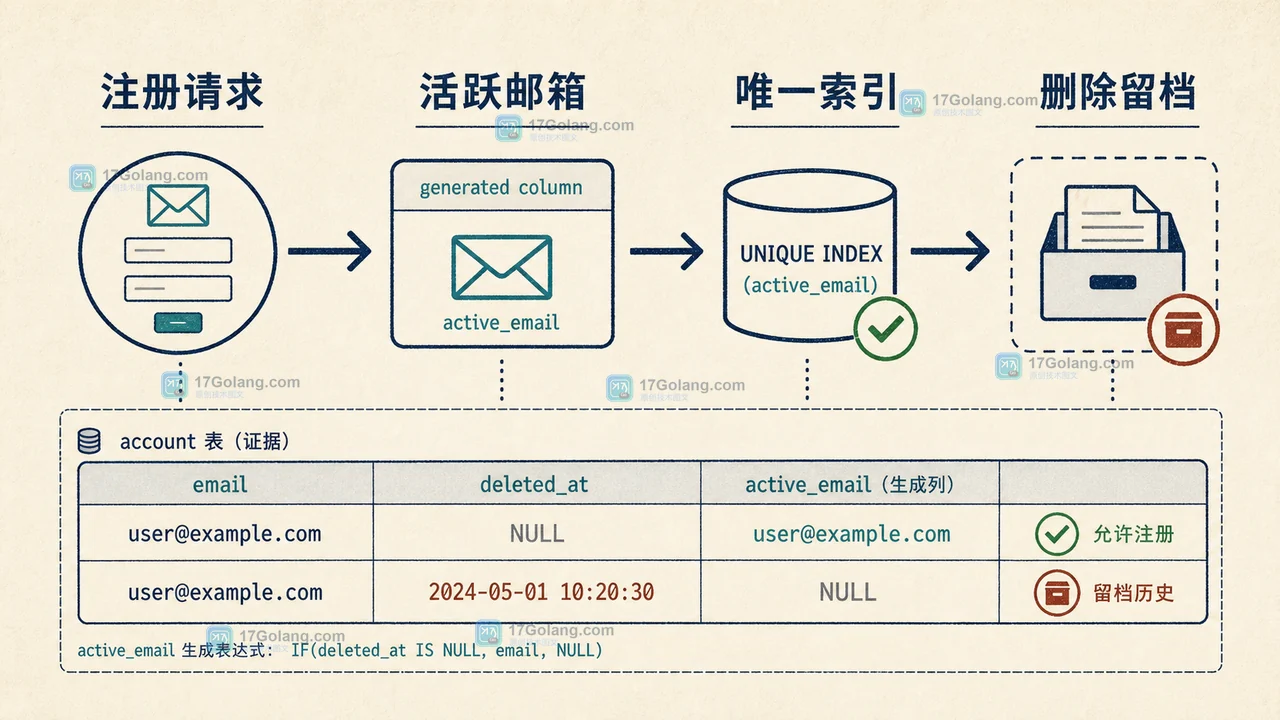 账号表用了软删除后,旧用户数据需要保留,新用户却可能再次使用同一邮箱。本文从真实注册冲突现场出发,说明复合唯一索引为何失效,以及如何用生成列把活跃账号约束、删除留档和恢复校验收进一条稳定的数据链路。471 收藏
账号表用了软删除后,旧用户数据需要保留,新用户却可能再次使用同一邮箱。本文从真实注册冲突现场出发,说明复合唯一索引为何失效,以及如何用生成列把活跃账号约束、删除留档和恢复校验收进一条稳定的数据链路。471 收藏 -
数据库 · MySQL | 5天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows
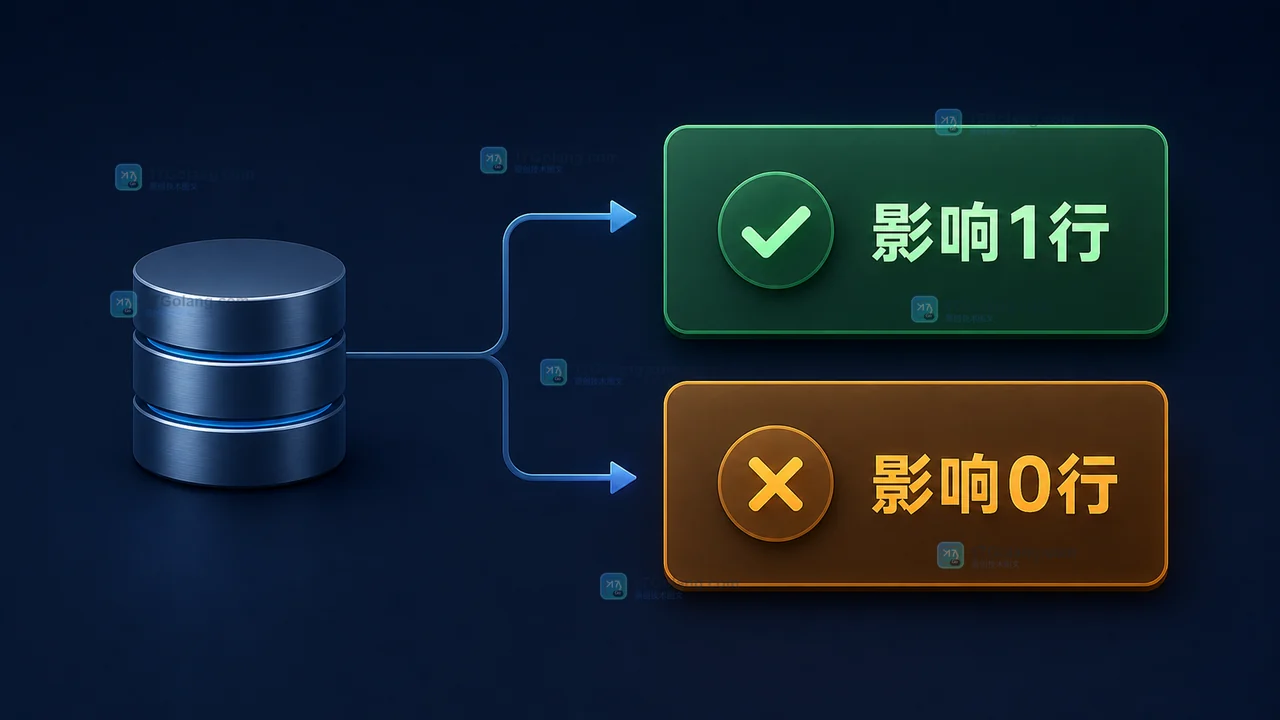 用一条带库存条件的 UPDATE 实现最小扣库存接口,避免先查后改造成超卖;同时说明受影响行、事务边界与死锁重试。470 收藏
用一条带库存条件的 UPDATE 实现最小扣库存接口,避免先查后改造成超卖;同时说明受影响行、事务边界与死锁重试。470 收藏 -
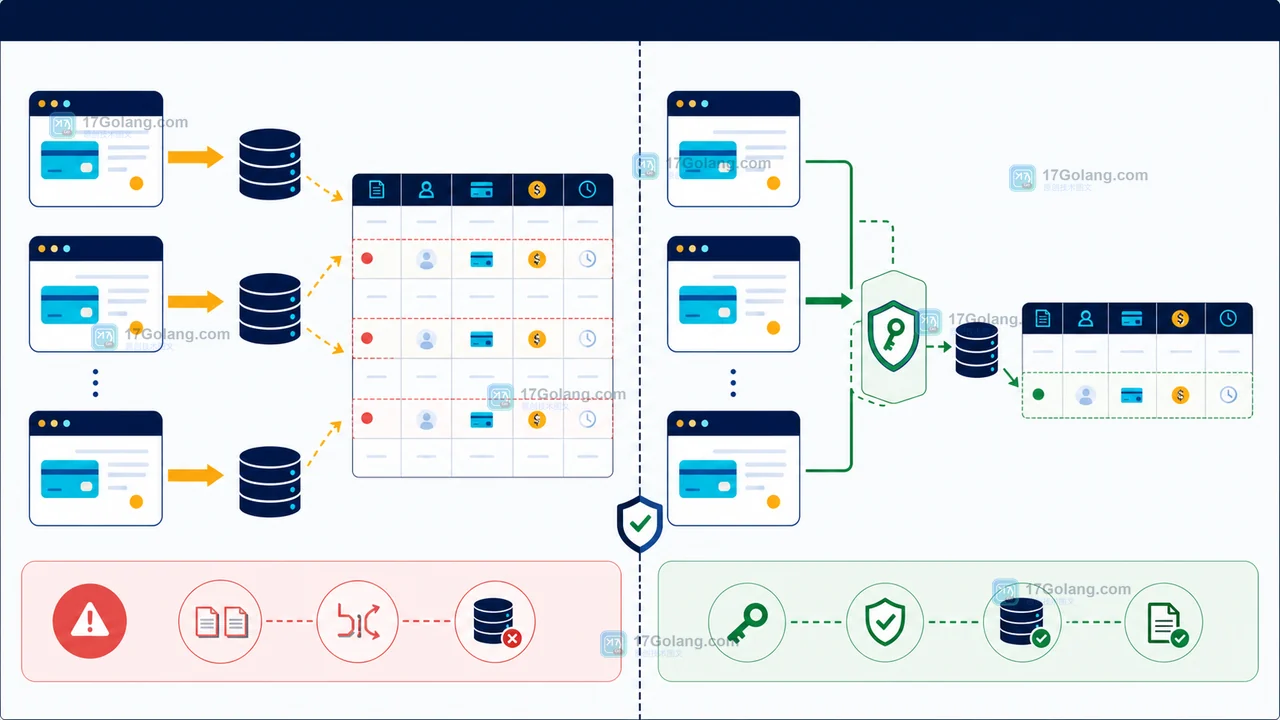 重复点击、网络重试和消息重复投递都会让写入接口面对同一业务请求多次到达。本文说明如何用幂等键和唯一索引建立数据库边界,并比较重复时返回既有结果与更新既有记录的取舍。421 收藏
重复点击、网络重试和消息重复投递都会让写入接口面对同一业务请求多次到达。本文说明如何用幂等键和唯一索引建立数据库边界,并比较重复时返回既有结果与更新既有记录的取舍。421 收藏 -
数据库 · MySQL | 16小时前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
 订单列表把渠道、会员等级放进 JSON 后,筛选条件容易变成逐行计算。本文用 MySQL 生成列和索引把 JSON 路径变成可核对的查询字段,同时处理缺失键、空字符串、类型转换和写入成本。351 收藏
订单列表把渠道、会员等级放进 JSON 后,筛选条件容易变成逐行计算。本文用 MySQL 生成列和索引把 JSON 路径变成可核对的查询字段,同时处理缺失键、空字符串、类型转换和写入成本。351 收藏 -
数据库 · MySQL | 4天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort
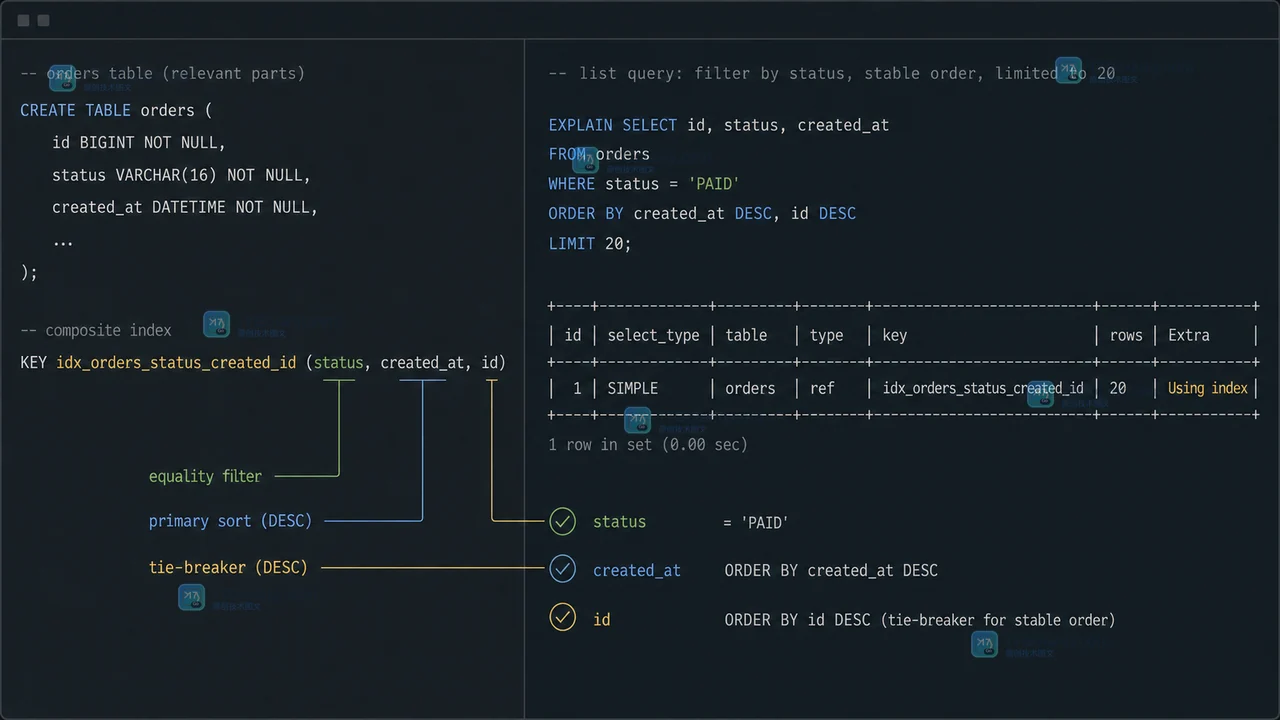 一条只取 20 行的订单查询,EXPLAIN 却可能放弃看似更贴近 WHERE 条件的索引,改走排序索引并在途中筛选。原因是 LIMIT 同时改变了排序、过滤和回表的成本取舍。通过读懂 key、rows 和 Extra,给等值条件与排序字段设计复合索引,再用受控对比核实实际读行,才能避免把 filesort 或某个索引名称当成唯一结论。279 收藏
一条只取 20 行的订单查询,EXPLAIN 却可能放弃看似更贴近 WHERE 条件的索引,改走排序索引并在途中筛选。原因是 LIMIT 同时改变了排序、过滤和回表的成本取舍。通过读懂 key、rows 和 Extra,给等值条件与排序字段设计复合索引,再用受控对比核实实际读行,才能避免把 filesort 或某个索引名称当成唯一结论。279 收藏 -
数据库 · MySQL | 1天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移
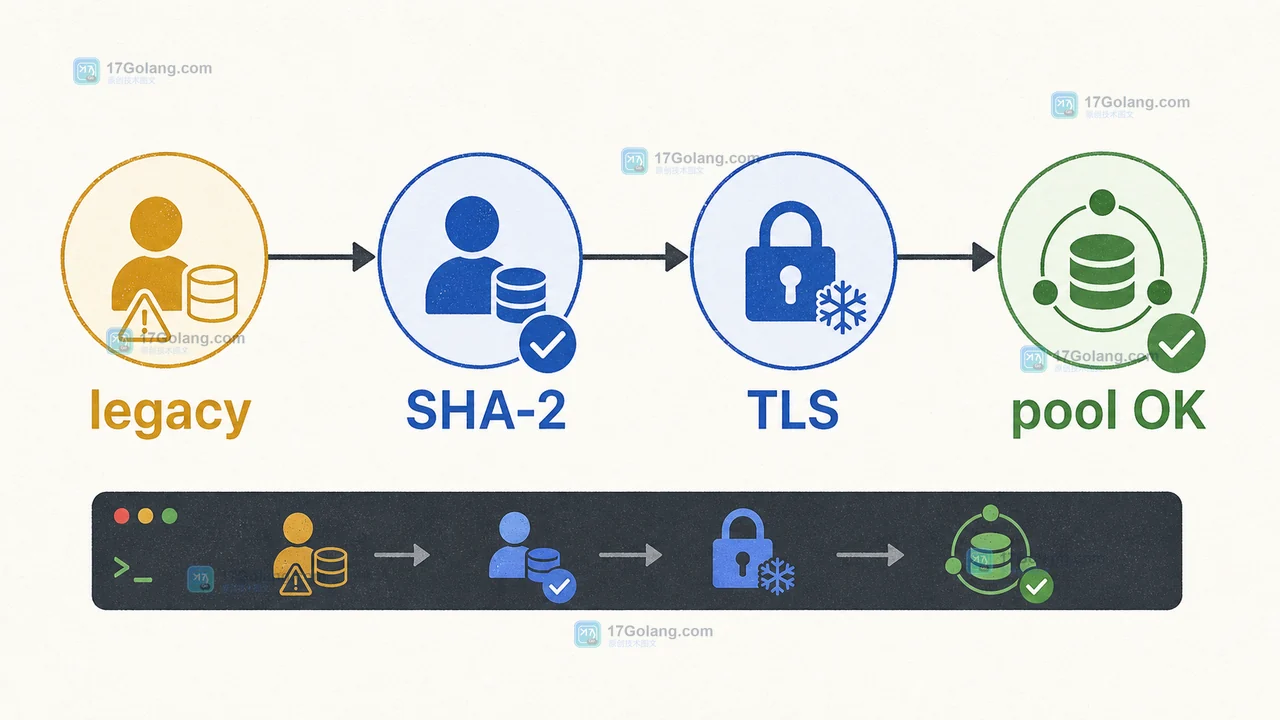 MySQL 8.4 默认不再启用 mysql_native_password,老应用可能在发版后出现账号认证失败。本文用账号盘点、灰度改造、TLS 连通性检查和回退边界,讲清迁移到 caching_sha2_password 的可靠做法。236 收藏
MySQL 8.4 默认不再启用 mysql_native_password,老应用可能在发版后出现账号认证失败。本文用账号盘点、灰度改造、TLS 连通性检查和回退边界,讲清迁移到 caching_sha2_password 的可靠做法。236 收藏 -
数据库 · MySQL | 3天前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT
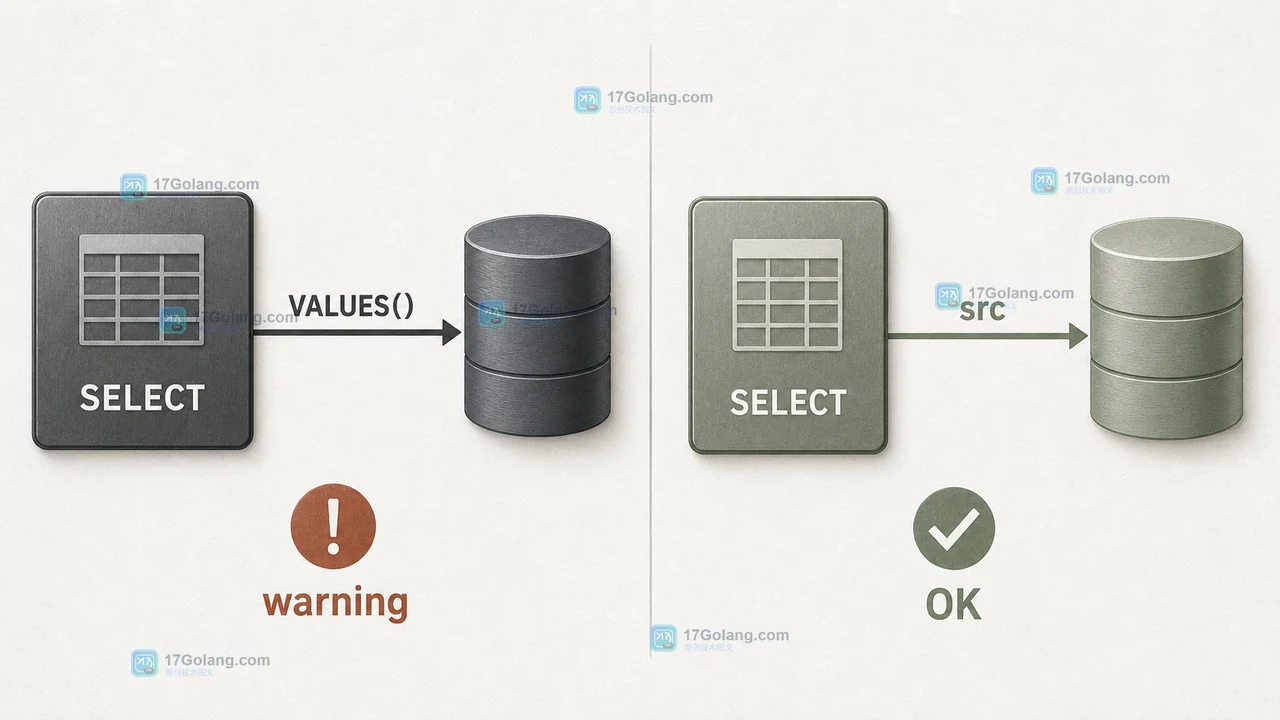 MySQL 已将 ON DUPLICATE KEY UPDATE 中用 VALUES() 读取新行字段的写法标记为弃用。本文从库存快照写入场景出发,给出行别名 AS new 的最小改写、INSERT ... SELECT 的不同处理方式,以及上线前应核对的兼容边界。117 收藏
MySQL 已将 ON DUPLICATE KEY UPDATE 中用 VALUES() 读取新行字段的写法标记为弃用。本文从库存快照写入场景出发,给出行别名 AS new 的最小改写、INSERT ... SELECT 的不同处理方式,以及上线前应核对的兼容边界。117 收藏