-

MySQL缓存优化主要通过InnoDB缓冲池和应用层缓存实现。1.合理配置InnoDB缓冲池大小(建议物理内存的50%~80%)、启用多个实例减少争用、预加载热点数据提升重启后性能;2.MySQL8.0以上使用Redis或Memcached做应用层缓存、手动缓存SQL结果、使用物化视图减少复杂查询开销;3.利用操作系统文件系统缓存数据文件,提升读取速度;4.开启慢查询日志优化高频低效语句,提升整体缓存效率并减少资源浪费。
-

在MySQL中,可以通过以下步骤进入并使用已创建的数据库:1.连接到MySQL服务器;2.使用CREATEDATABASE命令创建数据库,例如CREATEDATABASEmy_new_db;3.使用USE命令切换到新数据库,例如USEmy_new_db,这样即可在该数据库中进行操作。
-

统计29万条数据耗时13秒,是否合理?问题:执行如下SQL查询时,耗时13秒,查询29万条数据。SELECTcount(*)FROM...
-

如何使用PHPExcel通过模板导出包含图片的Excel文件?问题:如何修改PHPExcel代码,以便导出包含从数据库img字段获...
-

为什么MySQL的WHERE之间无法使用=检索布尔值?在MySQL中,WHERE...
-

MySQL中的proc表是系统表之一,用于存储存储过程(storedprocedure)的相关信息。存储过程是一组预定义的SQL语句集合,可以在需要时被多次调用执行,提高了数据库的灵活性和可维护性。proc表中包含了数据库中所有存储过程的元数据,如存储过程的名称、参数信息、定义的SQL语句等。通过proc表,用户可以查看和管理数据库中的存储过程,从而更好地
-

Oracle数据库版本更新速览:了解最新的Oracle版本特点,需要具体代码示例Oracle数据库一直是企业级数据库管理系统领域的领头羊,持续不断地更新版本以提供更好的性能、安全性和功能。本文将带您速览最新的Oracle数据库版本,探讨其特点,并通过具体的代码示例展示其应用。1.Oracle19cOracle19c是目前最新的稳定版本,于2019年发布
-

MySQL是一个开源的关系型数据库管理系统,广泛应用于Web应用程序的开发中。其中一个重要的特性就是MVCC(Multi-VersionConcurrencyControl,多版本并发控制)机制。本文将详细解析MySQL中MVCC的原理,并分析其对数据库性能的影响。一、什么是MVCCMVCC是一种并发控制技术,用于解决多个事务同时对数据库进行读写的并发操
-

MySQLORDERBY子句用于指定查询结果的排序。关键字ORDERBY后面必须跟有我们要排序的列的名称。例如,我们要根据“价格”列对名为“ratelist”的下表进行排序-mysql>Select*fromratelist;+----+------+-------+|Sr|Item|Price|+----+------+-------+|1|A|502||2|B|630||3|C|1005||4|h|850||5|T|250|+----+------+-------+5rowsinset(0.05
-
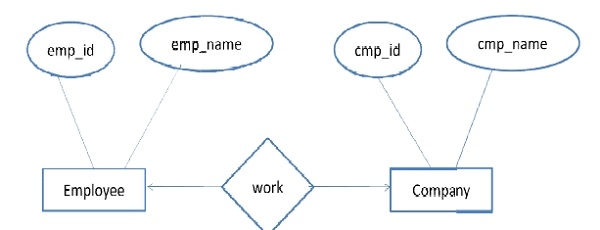
问题陈述ER图是显示各种表格及其之间关系的图形表示。ER图我们可以减少数据库的数量。一对一基数让我们考虑下面的一对一基数图-上面的ER图代表3个实体-Employee实体有2个属性,即emp_name。emp_id是主键公司实体有2个属性,即cmp_name。cmp_id是主键Work实体的主键可以是emp_id或cmp_id我们不能将3个表合并为一个表,可以将Work合并到Employee或Company中。在一对一基数场景中至少需要2个表。一对多基数让我们考虑下面具有一对多基数的图表-在此ER图中,员
-

让我们看看MySQL中的管理和实用程序,并了解如何使用它们-ibd2sdi它是一个提取实用程序来自InnoDB表空间文件的序列化字典信息(SDI)。SDI数据存在于所有持久性InnoDB表空间文件中。ibd2sdi可以在运行时或服务器离线时使用。innochecksum它打印InnoDB文件的校验和。它读取InnoDB表空间文件,计算每个页面的校验和,将计算的校验和与存储的校验和进行比较,并报告不匹配情况,从而显示损坏的页面。它最初是为了加快断电后表空间文件完整性的验证而开发的,但它也可以在文件复制后使用
-

探索MySQL和PostgreSQL的高可扩展性和负载平衡引言:在当前的信息时代,对于数据的存储和处理需求越来越大、越来越复杂。为了应对这样的挑战,数据库系统需要具备高可扩展性和负载平衡的能力。本文将探讨两个主流的开源关系型数据库系统MySQL和PostgreSQL的高可扩展性和负载平衡特性,并给出代码示例。一、MySQL的高可扩展性和负载平衡MySQL集群
-

随着互联网的普及,越来越多的小型企业开始了自己的在线业务。这些业务所涉及的数据量通常不是很大,但对于小型企业来说,数据的存储和处理仍然是一个非常重要的问题。MySQL数据库是目前用于存储和处理数据的最流行的数据库之一,也是许多小型企业的首选。本文将介绍如何使用Go语言进行快速开发和管理MySQL数据库。安装MySQL数据库在使用MySQL之前,我们需要先安装
-
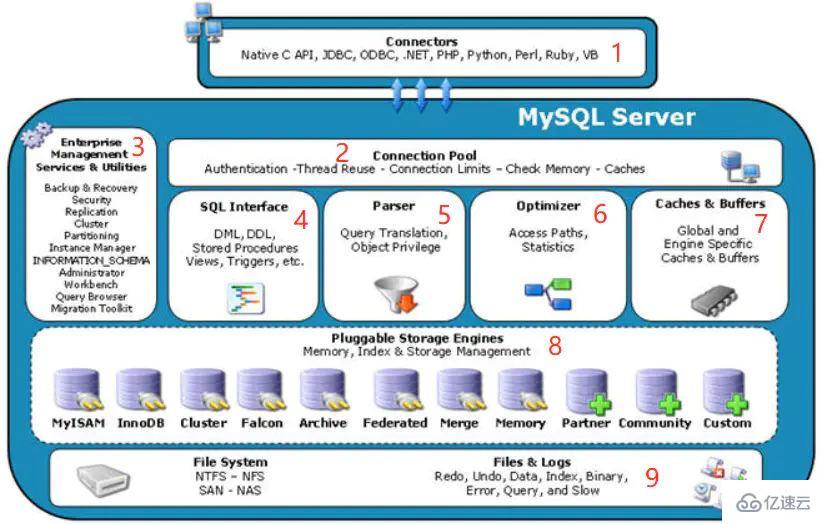
MySQL 由连接池、SQL 接口、解析器、优化器、缓存、存储引擎等组成,可以分为三层,即 MySQL Server 层、存储引擎层和文件系统层。MySQL Server 层又包括连接层和 SQL 层。1、客户端如上
-

什么是主从延迟在讨论如何解决主从延迟之前,我们先了解下什么是主从延迟。为了完成主从复制,从库需要通过 I/O 线程获取主库中 dump 线程读取的 binlog 内容并写入到自己的中继