-
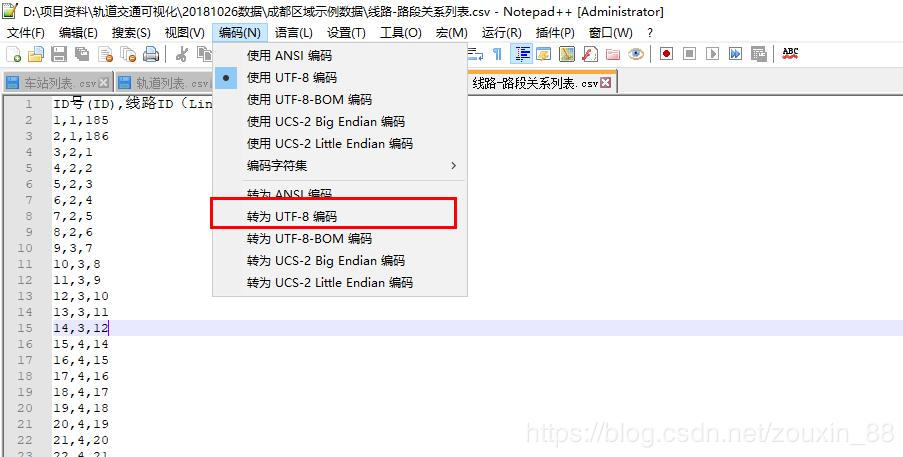
本文为大家分享了Navicat for SQLite导入csv中文数据的具体方法,供大家参考,具体内容如下
1.用Notepad++打开csv文件,点击菜单【编码】【转为UTF-8编码】,保存。
2.在Navicat for SQLite中选择“导入向
-

1、简介
数据无价,MySQL作为一个数据库系统,其备份自然也是非常重要且有必要去做。备份的理由千千万,预防故障,安全需求,回滚,审计,删了又改的需求等等,备份的重要性不言而喻。
-
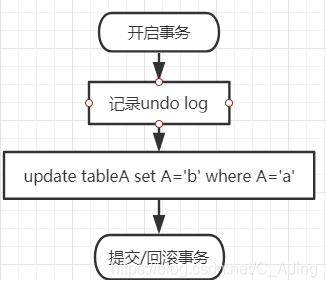
事务的特性:
原子性(Atomicity):原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变到另一个一致
-

优化GROUPBY性能的核心在于减少扫描数据量、合理使用索引并避免多余操作。1.优先让GROUPBY字段有索引,确保最左前缀匹配且覆盖WHERE条件,以跳过排序和临时表;2.避免在GROUPBY中使用函数或表达式,改用生成列加索引提升效率;3.只保留必要字段并用WHERE预过滤数据,减少分组规模;4.拆分复杂分组逻辑,用子查询或应用层合并结果,降低单条SQL复杂度。设计时考虑周全能有效避免后期调优被动。
-

外键约束在MySQL中用于维护数据完整性,级联删除和SETNULL是两种处理删除操作的策略。1.创建父表并定义主键;2.创建子表时通过FOREIGNKEY指定外键,并使用ONDELETECASCADE或ONDELETESETNULL设定删除策略;3.插入测试数据验证约束效果;4.使用ALTERTABLE修改已有表的外键约束。级联删除适用于需同步删除关联数据的场景,而SETNULL适用于保留子表记录但解除关联的场景,且外键字段必须允许为NULL。选择合适策略可提升数据库一致性与业务匹配度。
-

MySQL数据备份的关键方法包括:一、使用mysqldump进行逻辑备份,适合中小型数据库,可通过命令实现全量备份并结合压缩节省空间;二、物理备份通过直接复制数据文件实现,速度快但需停机或使用一致性机制;三、利用binlog实现增量备份,支持时间点恢复,建议定期归档日志以减少数据丢失风险;四、合理策略如每日全量+小时binlog归档、周全量+日增量+binlog、主从复制+定时备份等,同时必须定期验证备份可恢复性。
-

MySQL缓存优化主要通过InnoDB缓冲池和应用层缓存实现。1.合理配置InnoDB缓冲池大小(建议物理内存的50%~80%)、启用多个实例减少争用、预加载热点数据提升重启后性能;2.MySQL8.0以上使用Redis或Memcached做应用层缓存、手动缓存SQL结果、使用物化视图减少复杂查询开销;3.利用操作系统文件系统缓存数据文件,提升读取速度;4.开启慢查询日志优化高频低效语句,提升整体缓存效率并减少资源浪费。
-
![在MySQL中创建表的完整语法如下:CREATETABLE表名(列名1数据类型(长度)[约束],列名2数据类型(长度)[约束],...列名n数据类型(长度)[约束],[PRIMARYKEY(列名)],[FOREIGNKEY(列名)REFERENCES其他表名(列名)],[INDEX索引名(列名)])[ENGINE=存储引擎][DEFAULTCHARSET=字符集];例如,要创建一个名为employ](/uploads/20250603/1748944098683ec4e2b36c3.jpg)
在MySQL中创建表的步骤如下:1.使用CREATETABLE语句定义表结构,包含字段名、数据类型和约束。2.设置主键和唯一键,确保数据唯一性。3.选择合适的存储引擎和字符集。4.考虑性能优化,如使用合适的索引和定期维护。通过这些步骤和最佳实践,可以有效提升数据库的性能和可维护性。
-

在MySQL中创建表的步骤如下:1.使用CREATETABLE语句定义表结构,包含字段名、数据类型和约束。2.设置主键和唯一键,确保数据唯一性。3.选择合适的存储引擎和字符集。4.考虑性能优化,如使用合适的索引和定期维护。通过这些步骤和最佳实践,可以有效提升数据库的性能和可维护性。
-

要解决MySQL中的中文乱码问题,需要修改MySQL的配置文件以支持UTF-8字符集。具体步骤如下:1.打开MySQL配置文件(如/etc/mysql/my.cnf或C:\ProgramData\MySQL\MySQLServerx.x\my.ini)。2.在配置文件中添加或修改[mysqld]、[client]和[mysql]下的字符集设置为utf8mb4。3.重启MySQL服务以使更改生效。
-

MySQL下载失败主要由网络问题、服务器问题、防火墙或代理限制以及下载工具问题导致。1.检查网络连接并尝试在网络状况良好时重新下载;2.更换下载源或稍后再试;3.暂时关闭防火墙或代理服务器,或配置其允许MySQL下载;4.使用wget或curl等更稳定的下载工具,并使用-c参数支持断点续传。建议选择合适的下载时间和工具,并验证文件完整性,确保下载成功。
-

如何处理Redis中的大key?针对任务数据实时保存需求,在任务开始时,每5秒将数据保存到Redis的list...
-

MySQL中"="判断导致“模糊”匹配的原因在MySQL中使用"="...
-

使用Mybatis的数据库厂商标识执行动态SQL在Mybatis中需要根据配置变量值执行不同SQL...
-

BufferPool与RedoLog的作用对比尽管RedoLog的写入速度优于BufferPool,但二者的作用存在本质差异。Redo...