-

将列声明为“NOTNULL”意味着该列不接受NULL值,但接受零(0),并且空字符串本身就是一个值。因此,如果我们想将零或空字符串插入到定义为NOTNULL的MySQL列中,就不会有问题。下面将0和空字符串与NULL进行比较就会清楚-mysql>Select0ISNULL,0ISNOTNULL;+-----------+---------------+|0ISNULL|0ISNOTNULL|+-----------+---------------+| 0
-

MySQL双写缓冲原理及其在数据库开发中的优化应用随着互联网的快速发展,数据库作为后端系统的重要组成部分,承载着大量的数据读写操作。为了提高数据库的性能和稳定性,MySQL引入了双写缓冲机制,成为了数据库开发中的重要优化手段之一。本文将介绍MySQL双写缓冲的工作原理,并给出代码示例,展示其在数据库开发中的优化应用。一、双写缓冲的工作原理MySQL的双写缓冲
-

如何在Node.js程序中重连MySQL连接?MySQL是一种流行的关系型数据库,而Node.js是一种非常流行的服务器端编程语言。将两者结合使用是很常见的,在Node.js程序中连接到MySQL数据库可以让我们对数据进行操作、存储和检索。然而,有时候MySQL连接可能会由于各种原因断开,这时我们就需要在程序中实现重连机制,以确保程序的稳定性和可靠性。本文将
-

MySQL是一款非常流行的关系型数据库管理系统,广泛应用于各个领域。在实际的应用场景中,我们可能需要在同一台服务器上同时运行多个MySQL实例,以满足不同应用程序的需求。本文将介绍MySQL中的多实例管理技巧,帮助您更好地管理多个MySQL实例。安装MySQL多实例在安装MySQL时,我们可以选择安装多个MySQL实例。安装多个MySQL实例的方法与安装单个
-

常规篇1、说一下数据库的三大范式? 第一范式:字段原子性,第二范式:行唯一,有主键列,第三范式:每列和主键列都相关。实际应用中会通过冗余少量字段来少关联表,提升
-
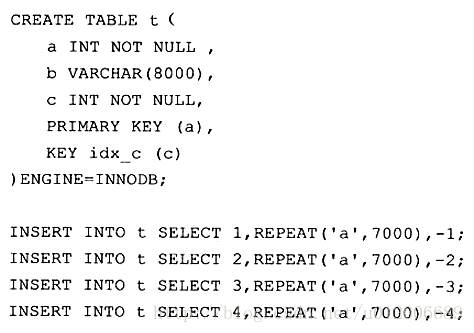
聚集索引(Clustered Index)聚集索引就是按照每张表的主键构造一棵B+树,同时叶子节点中存放的即为整张表的行记录数据。举个例子,直观感受下聚集索引。创建表t,并以人为的方
-

还是之前工作中遇到的一个小问题。我在做一个收据采集的程序,需要记录起始时间和结束时间,在数据库中是用timestamp字段来保存的,有些情况下不存在起始时间,此时就需要设置一个默认的
-

一 MyISAM
1.1 MyISAM简介
MyISAM是MySQL的默认数据库引擎(5.5版之前),由早期的 ISAM (Indexed Sequential Access Method:有索引的顺序访问方法)所改良。虽然性能极佳,而且提供了大量的特性,包括全文
-

6.5 条件判断函数
条件判断函数也被称为控制流程函数,根据满足的条件的不同,执行相应的流程,Mysql中进行条件判断的有IF,IFNULL,和CASE。
6.5.1 IF(expr,v1,v2)函数
IF(expr,v1,v2)如果表达式expr是true(exp
-

mysql unix时间戳存储与FROM_UNIXTIME()格式化时间戳函数定义: 存储时间比如 user 表 login_time 字段用unix时间戳的方式存储`login_time` int(11) NOT NULL DEFAULT 0 COMMENT '登录时间',from_unixtime 语法FROM_UNIXTIME(unixtim
-

作者 谢恩铭,公众号「程序员联盟」(微信号:coderhub)。转载请注明出处。原文:https://www.jianshu.com/p/cc9...
《Web探索之旅》全系列
内容简介
前言
数据库
SQL 语言
动态网站
总结
第二部分
-

一、什么叫数据类型?人们能够非常容易地区分数字与字符,可是计算机并不会。除非是你明确地告诉它,1是数字,“汉”是文本,不然它始终没法分辨1和‘汉’的区别。因而,在每一个计算
-

1.Lambda表达式简介 Lambda表达式是java 1.8才开始有的重要功能,使用Lambda表达式可以替代匿名内部类,代码简洁易懂,提升工作效率。上代码:2.函数式接口简介 有且只有一个抽象方法(可以包
-

对于数据库领域的业内人士来讲,一年一度的DTCC中国数据库技术大会承载了大家太多的期待,在这里有数据库大厂之间的PK较量,有业内专家的干货分享。然而受新冠疫情的影响,为响应北京市
-

触发器简介
触发器是和表关联的特殊的存储过程,可以在插入,删除或修改表中的数据时触发执行,比数据库本身标准的功能有更精细和更复杂的数据控制能力。
触发器的优点:
安全性: