MySQL技术文章
-
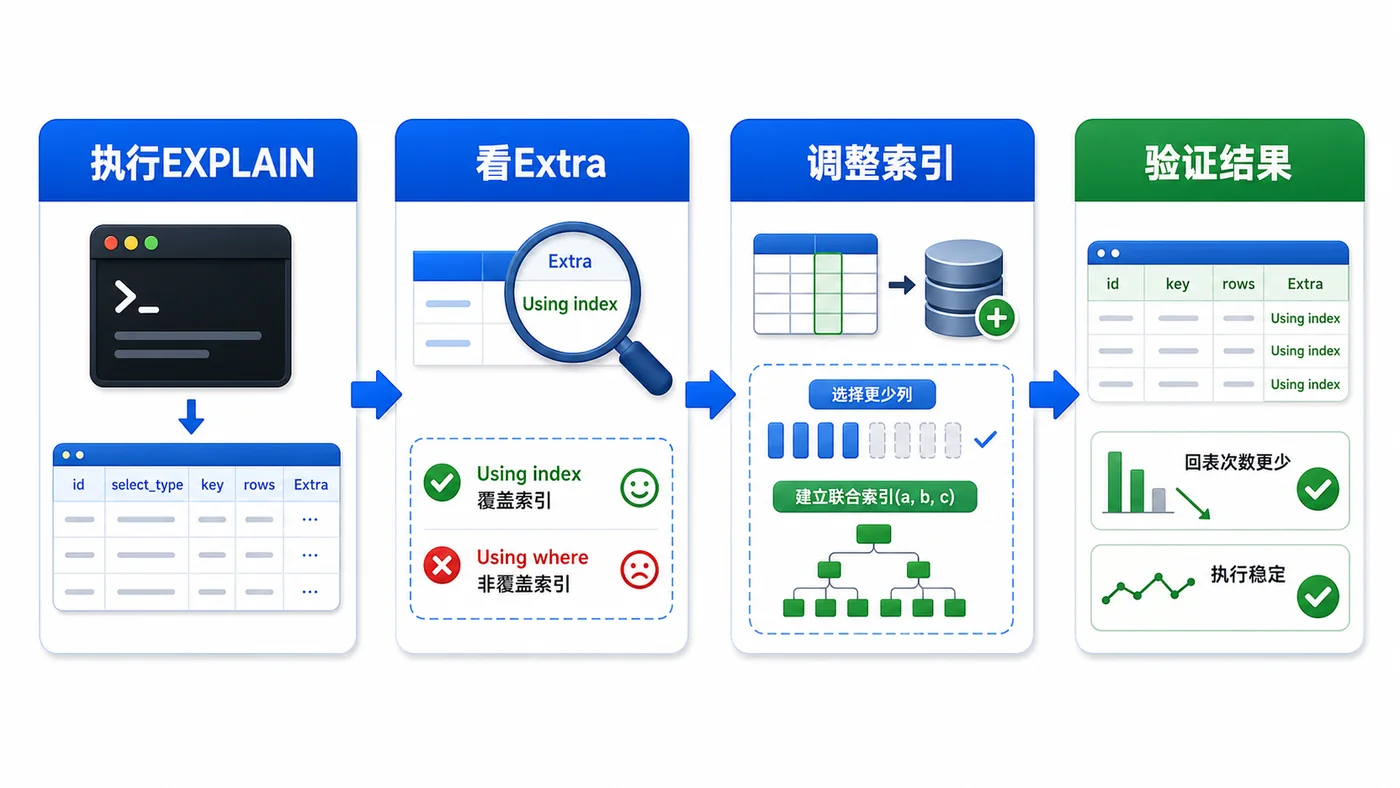 本文用订单列表查询场景,演示普通二级索引为什么需要回表,以及如何通过覆盖索引减少回表,并用 EXPLAIN 的 Extra 验证优化结果。381 收藏
本文用订单列表查询场景,演示普通二级索引为什么需要回表,以及如何通过覆盖索引减少回表,并用 EXPLAIN 的 Extra 验证优化结果。381 收藏 -
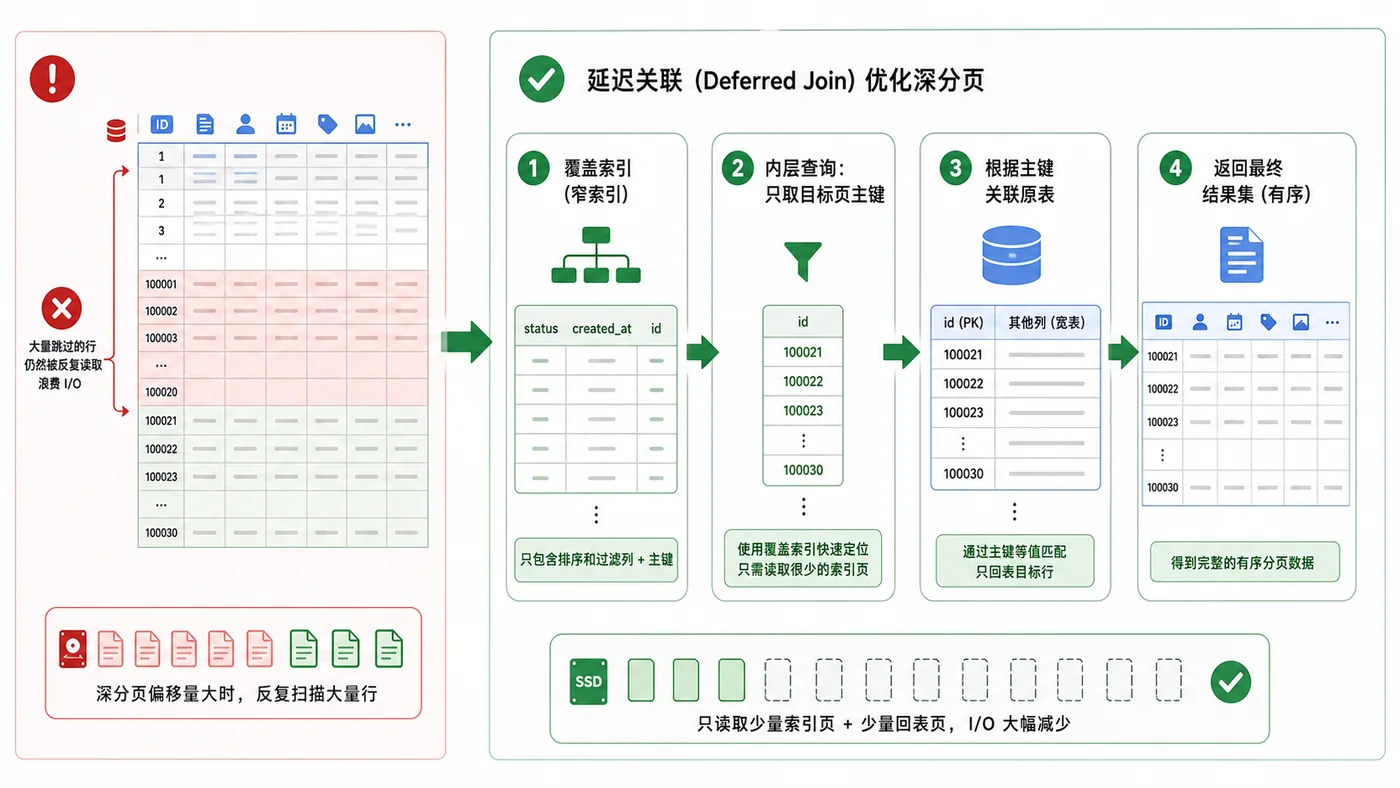 本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。339 收藏
本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。339 收藏 -
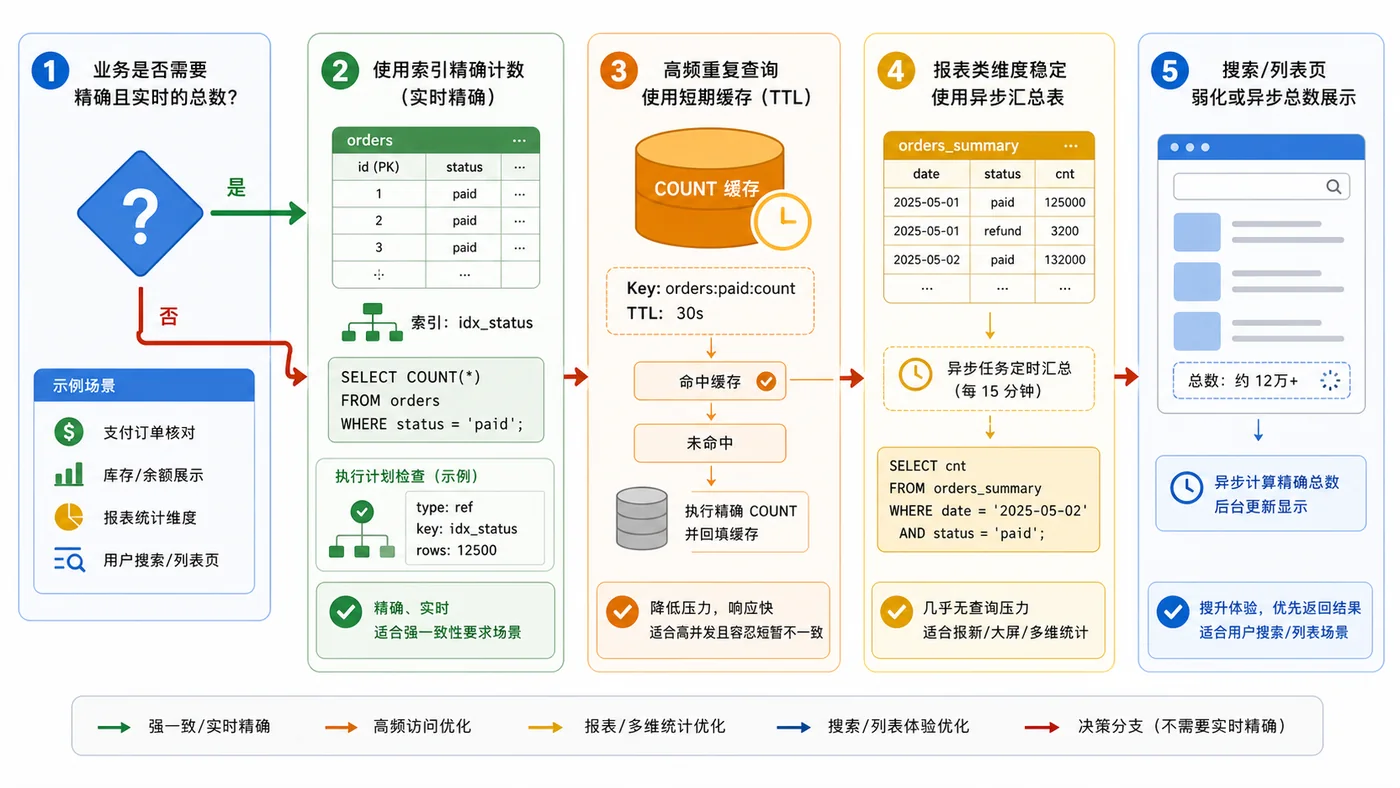 本文用后台订单列表总数统计场景,演示为什么大表每次 COUNT 会拖慢接口,并按精确总数、条件筛选、缓存和汇总表给出优化方案。336 收藏
本文用后台订单列表总数统计场景,演示为什么大表每次 COUNT 会拖慢接口,并按精确总数、条件筛选、缓存和汇总表给出优化方案。336 收藏 -
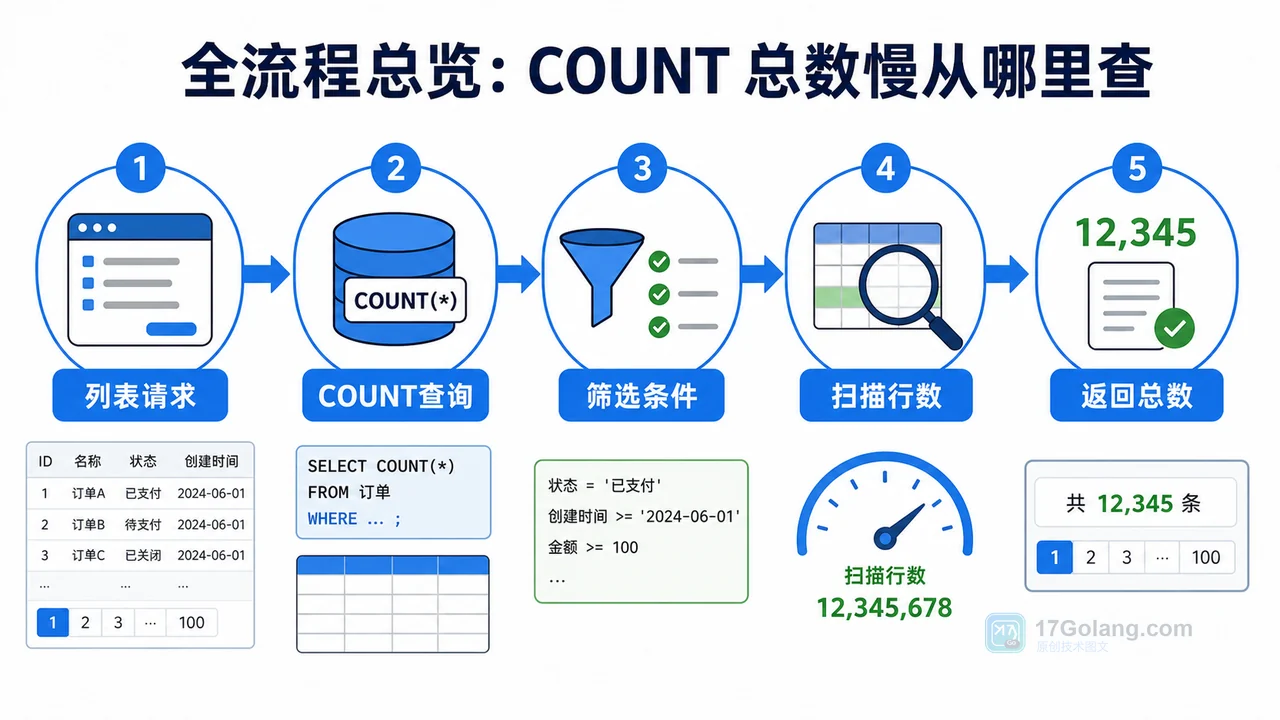 列表页分页常常要查总数,但 COUNT(*) 一慢,整个页面都会被拖住。本文按完整工作流拆解:先确认筛选条件和扫描行数,再选择联合索引、缓存总数或汇总表,最后给出上线检查清单。329 收藏
列表页分页常常要查总数,但 COUNT(*) 一慢,整个页面都会被拖住。本文按完整工作流拆解:先确认筛选条件和扫描行数,再选择联合索引、缓存总数或汇总表,最后给出上线检查清单。329 收藏 -
数据库 · MySQL | 4星期前 | InnoDB · 故障排查 · 生产实践 · MySQL教程 · 事务隔离 · mysql innodb Purge Lag History List 长事务 Undo
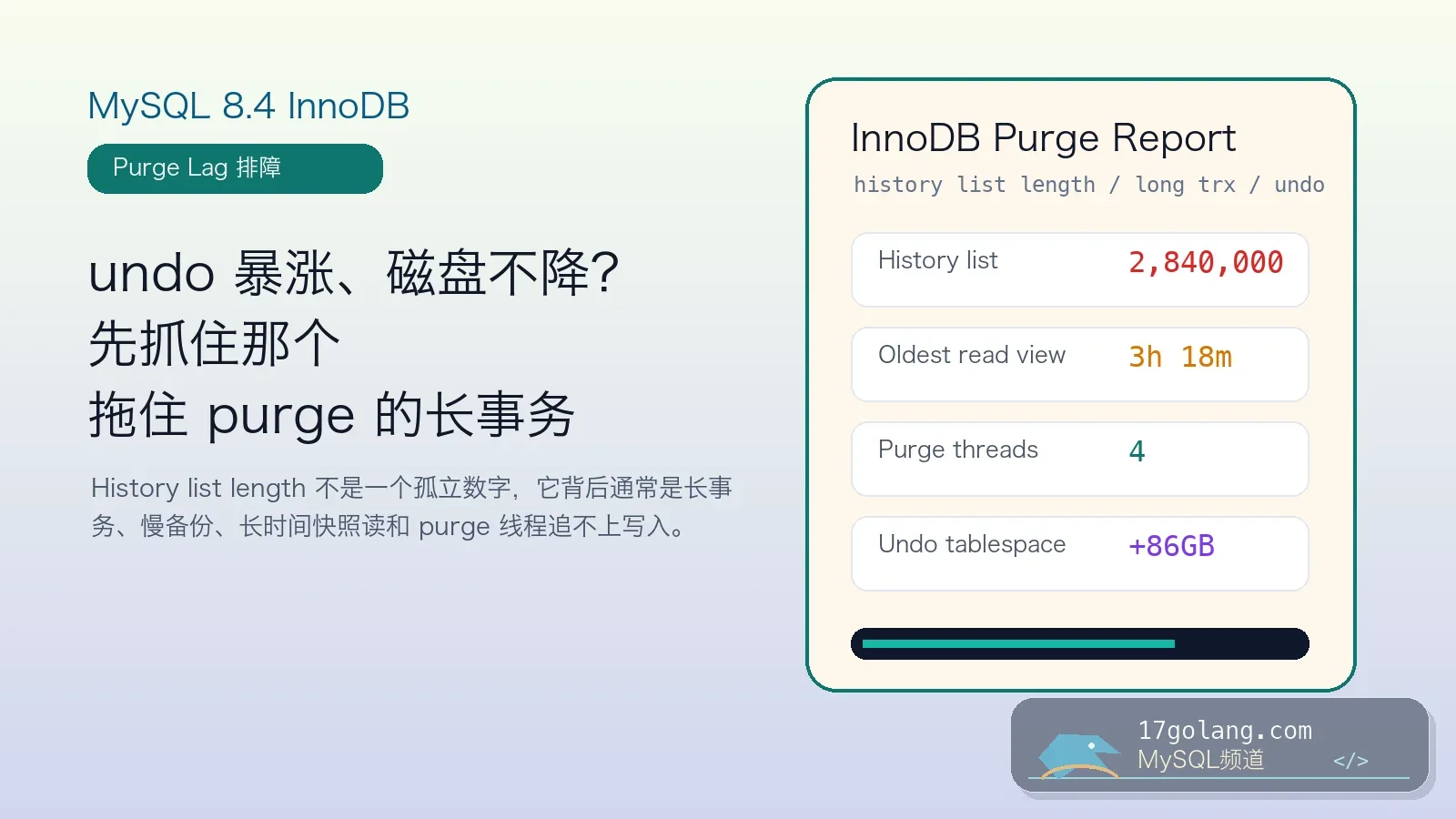 从 MySQL 8.4 InnoDB purge lag 入手,讲清 history list length、长事务、undo 暴涨和 purge 参数的生产排障方法。326 收藏
从 MySQL 8.4 InnoDB purge lag 入手,讲清 history list length、长事务、undo 暴涨和 purge 参数的生产排障方法。326 收藏 -
数据库 · MySQL | 4星期前 | MySQL教程 · 数据库实战 · 在线DDL · ALTER TABLE · 元数据锁 · mysql innodb MySQL 8 在线 DDL ALTER TABLE MDL 元数据锁 INSTANT
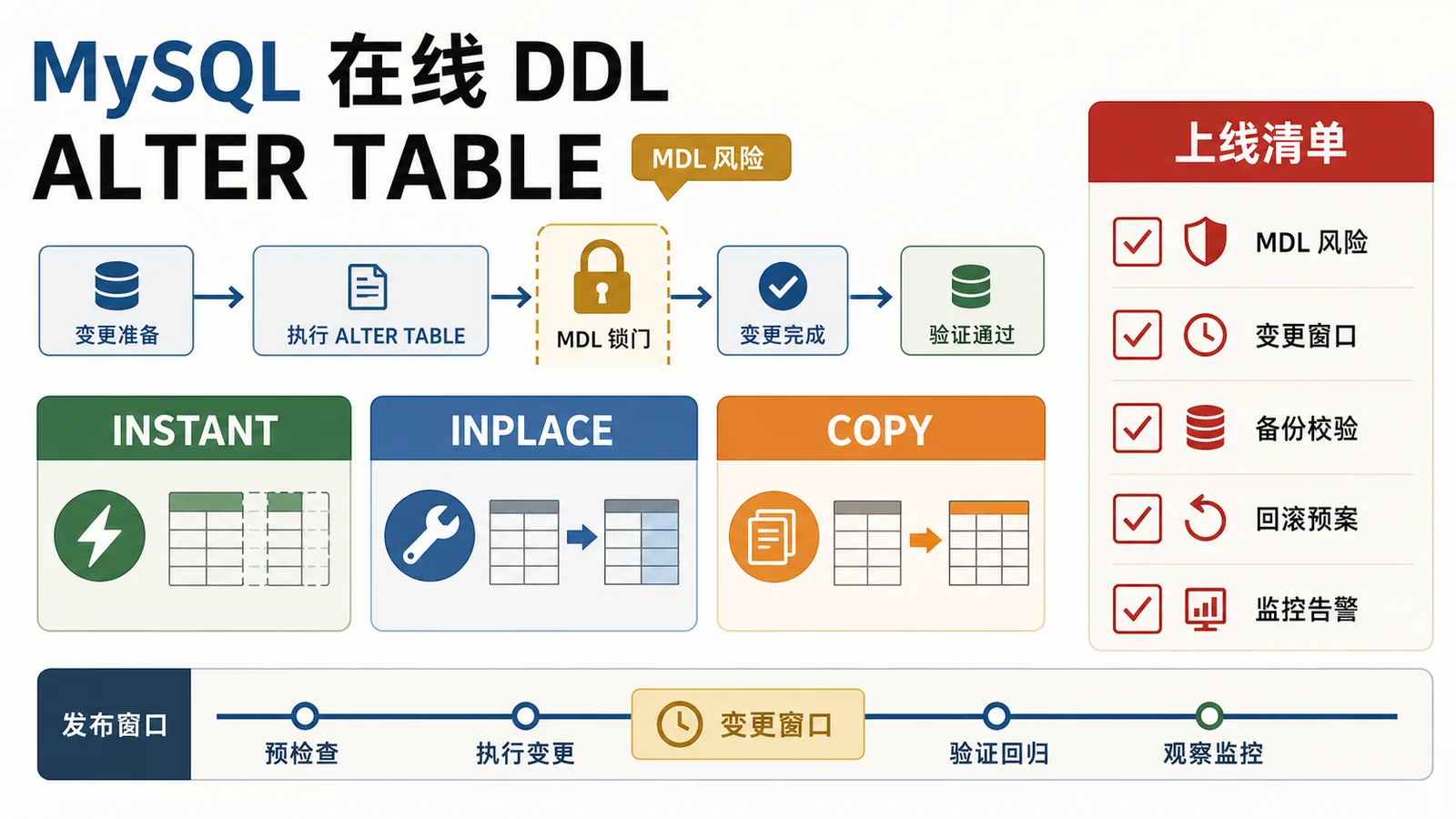 从订单大表加字段出发,讲清 MySQL 8.x 在线 DDL、ALGORITHM=INSTANT/INPLACE/COPY、metadata lock、row version 上限、复制延迟和上线复查。323 收藏
从订单大表加字段出发,讲清 MySQL 8.x 在线 DDL、ALGORITHM=INSTANT/INPLACE/COPY、metadata lock、row version 上限、复制延迟和上线复查。323 收藏 -
 本文按完整工作流讲解 MySQL 慢 SQL 优化:从慢查询日志发现候选 SQL,聚合同类语句,用 EXPLAIN 判断访问方式和扫描行数,再设计联合索引,并通过延迟、扫描行数和业务结果做回归验证。321 收藏
本文按完整工作流讲解 MySQL 慢 SQL 优化:从慢查询日志发现候选 SQL,聚合同类语句,用 EXPLAIN 判断访问方式和扫描行数,再设计联合索引,并通过延迟、扫描行数和业务结果做回归验证。321 收藏 -
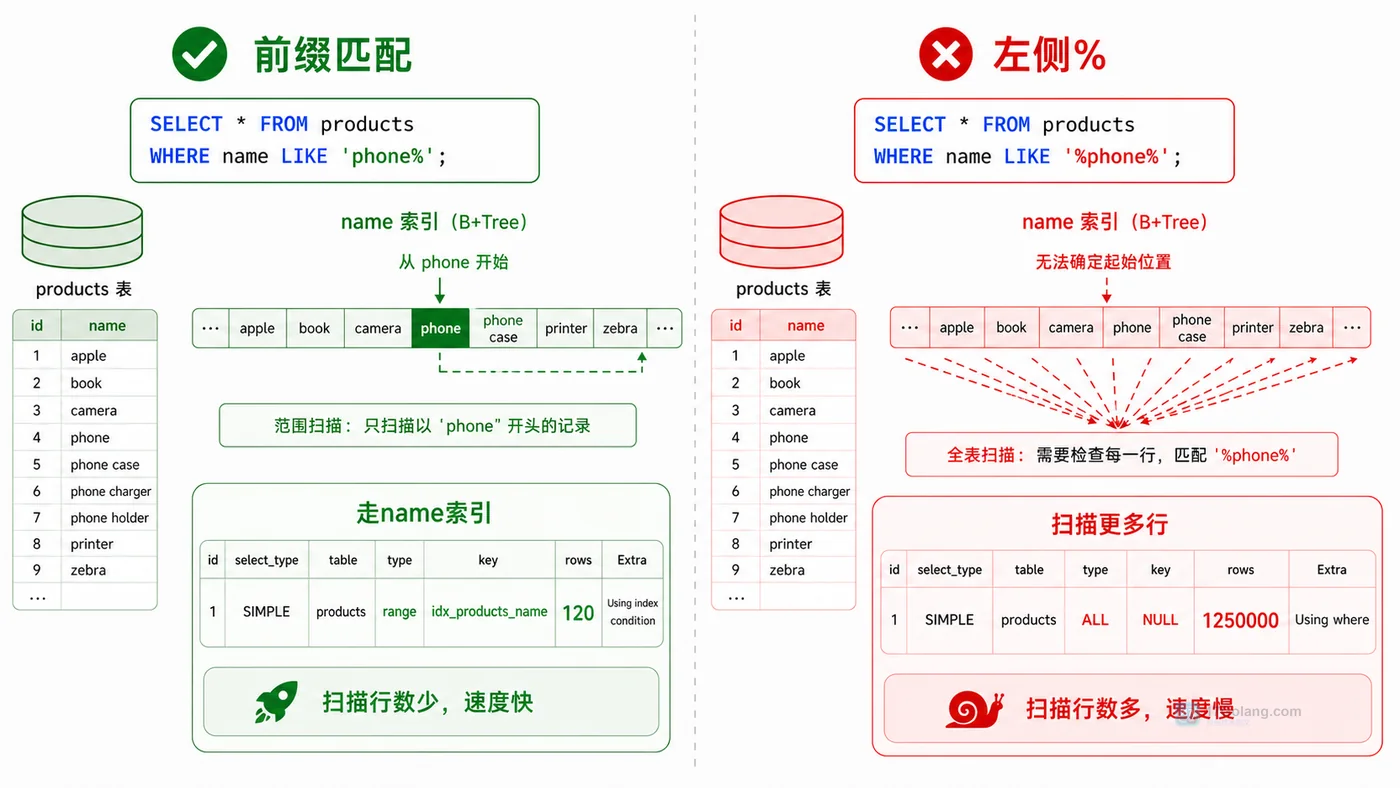 搜索框查询一上线就变慢,很多时候不是数据量突然失控,而是 LIKE 条件写法让索引用不上。本文从慢查询现场开始,逐步验证左通配符、执行计划、前缀匹配和业务改写,整理一套更稳的模糊搜索排查方法。308 收藏
搜索框查询一上线就变慢,很多时候不是数据量突然失控,而是 LIKE 条件写法让索引用不上。本文从慢查询现场开始,逐步验证左通配符、执行计划、前缀匹配和业务改写,整理一套更稳的模糊搜索排查方法。308 收藏 -
数据库 · MySQL | 3星期前 | 字符集 · 故障排查 · MySQL教程 · 索引优化 · 排序规则 · mysql 排序规则 索引优化 utf8mb4 collation MySQL 8.4
 从账号唯一键和昵称搜索踩坑切入,讲清 MySQL 8.x utf8mb4_0900_ai_ci、大小写/重音敏感、collation 混用、隐式转换与索引命中验证。294 收藏
从账号唯一键和昵称搜索踩坑切入,讲清 MySQL 8.x utf8mb4_0900_ai_ci、大小写/重音敏感、collation 混用、隐式转换与索引命中验证。294 收藏 -
数据库 · MySQL | 3星期前 | MySQL教程 · 慢查询治理 · 索引优化 · JSON查询 · InnoDB实战 · mysql JSON 慢查询 索引优化 MySQL 8.4 多值索引
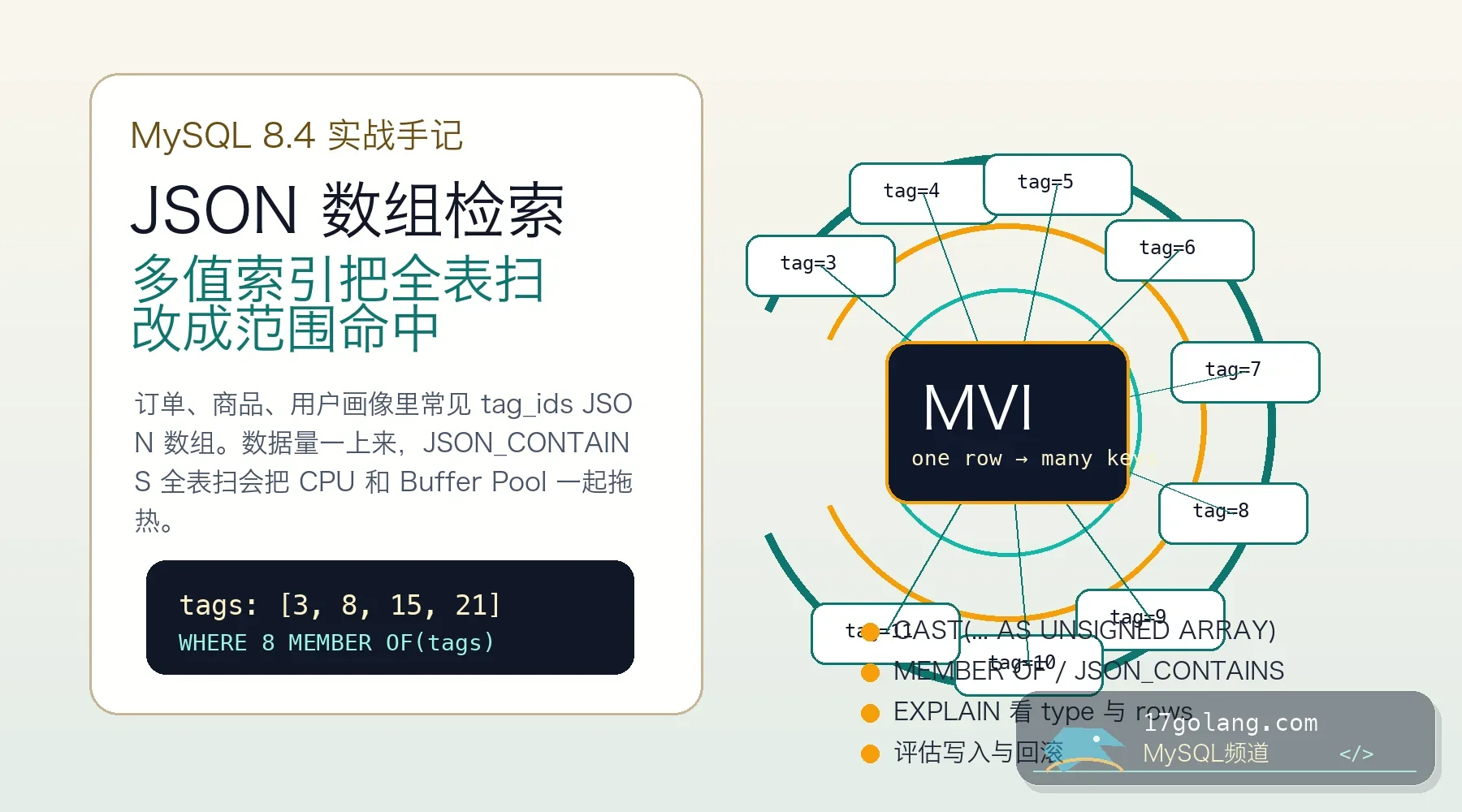 从标签检索接口慢查询切入,讲清 MySQL 8.x 多值索引如何让 JSON 数组条件命中索引,以及建索引、EXPLAIN 验证、写入成本和上线回滚检查。291 收藏
从标签检索接口慢查询切入,讲清 MySQL 8.x 多值索引如何让 JSON 数组条件命中索引,以及建索引、EXPLAIN 验证、写入成本和上线回滚检查。291 收藏 -
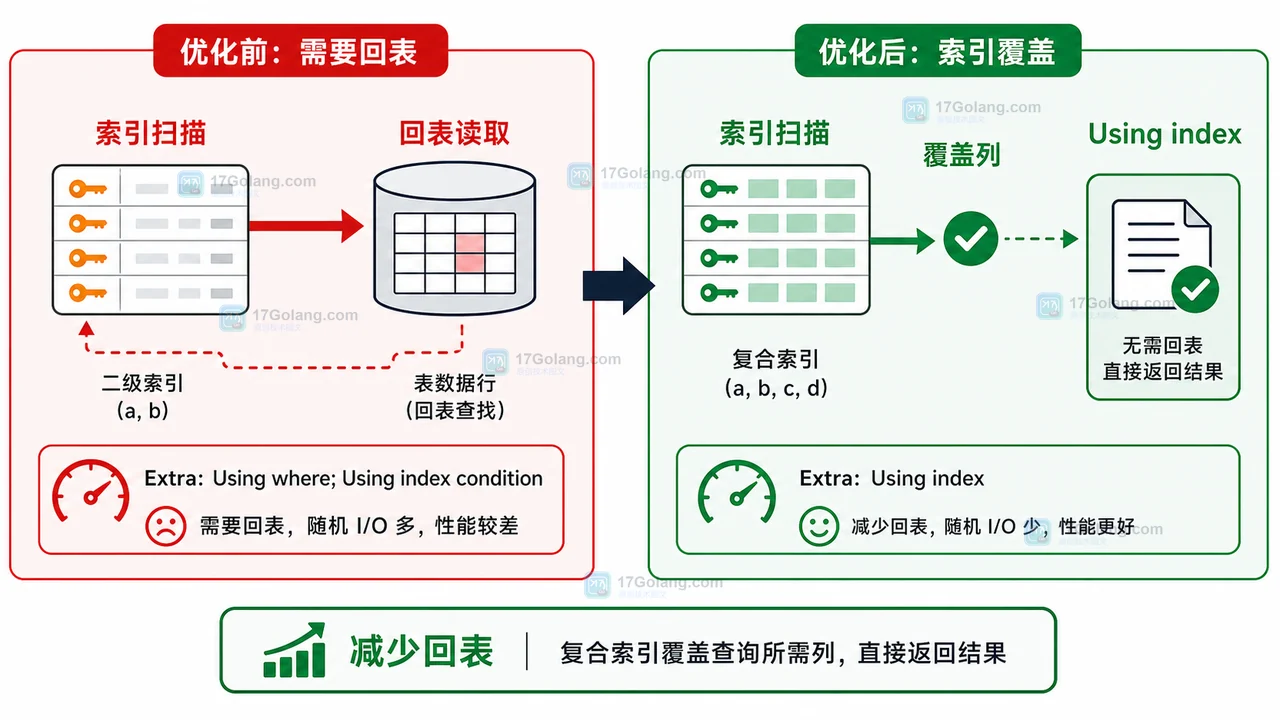 通过一个可复现的小实验,从订单列表慢查询开始,初始化表和数据,添加复合索引,再用 EXPLAIN 检查 Using index,理解覆盖索引的适用边界。276 收藏
通过一个可复现的小实验,从订单列表慢查询开始,初始化表和数据,添加复合索引,再用 EXPLAIN 检查 Using index,理解覆盖索引的适用边界。276 收藏 -
数据库 · MySQL | 3星期前 | 性能优化 · InnoDB · MySQL教程 · 数据库运维 · 高并发写入 · mysql innodb 批量写入 Change Buffer innodb_change_buffering
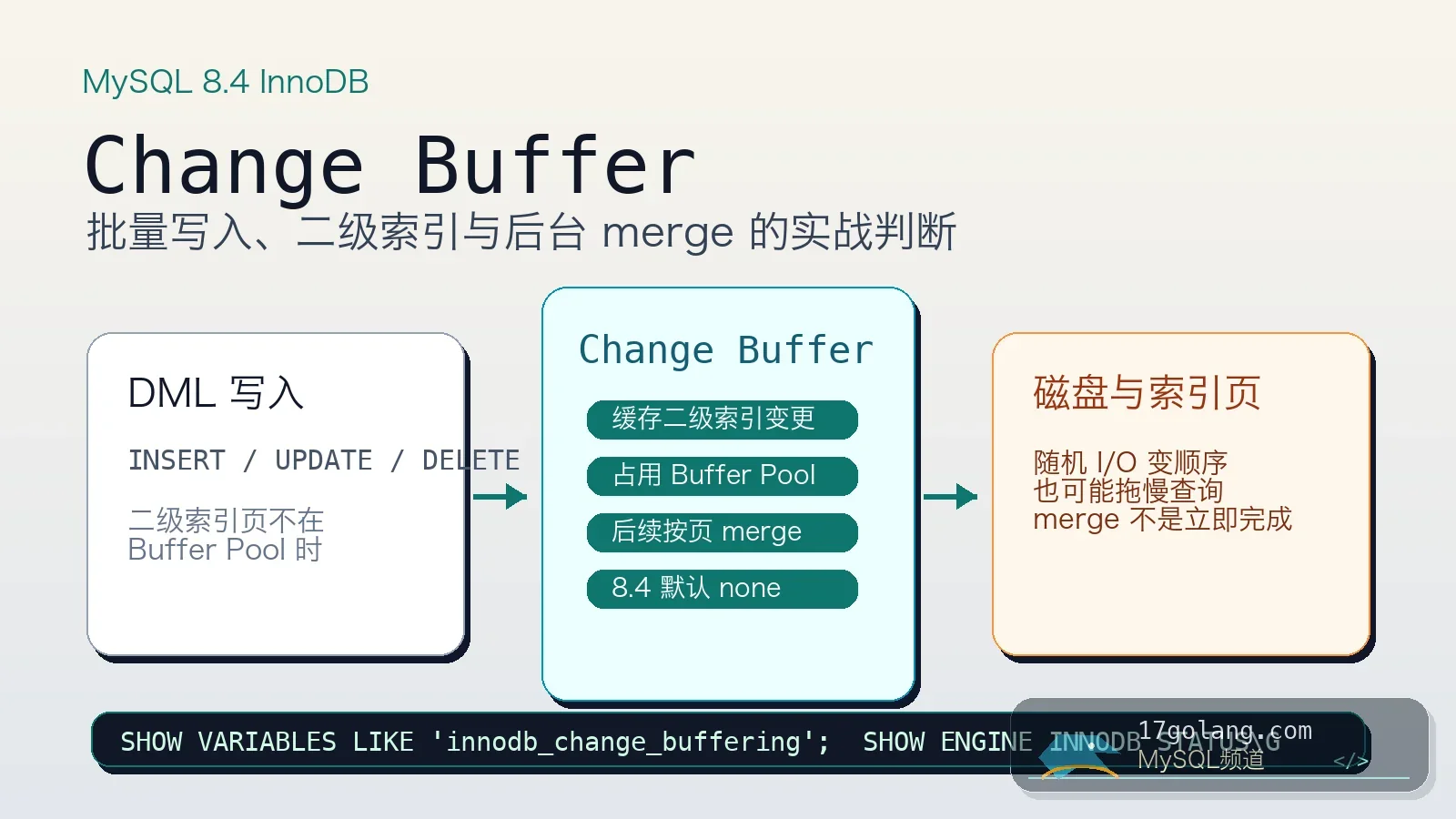 从 MySQL 8.4 InnoDB Change Buffer 默认值变化入手,讲清批量写入、二级索引随机 I/O、merge 观察和上线回滚。270 收藏
从 MySQL 8.4 InnoDB Change Buffer 默认值变化入手,讲清批量写入、二级索引随机 I/O、merge 观察和上线回滚。270 收藏 -
数据库 · MySQL | 3星期前 | 性能优化 · 执行计划 · MySQL教程 · 慢查询治理 · 数据库运维 · mysql GROUP BY优化 TempTable 内部临时表 Created_tmp_disk_tables
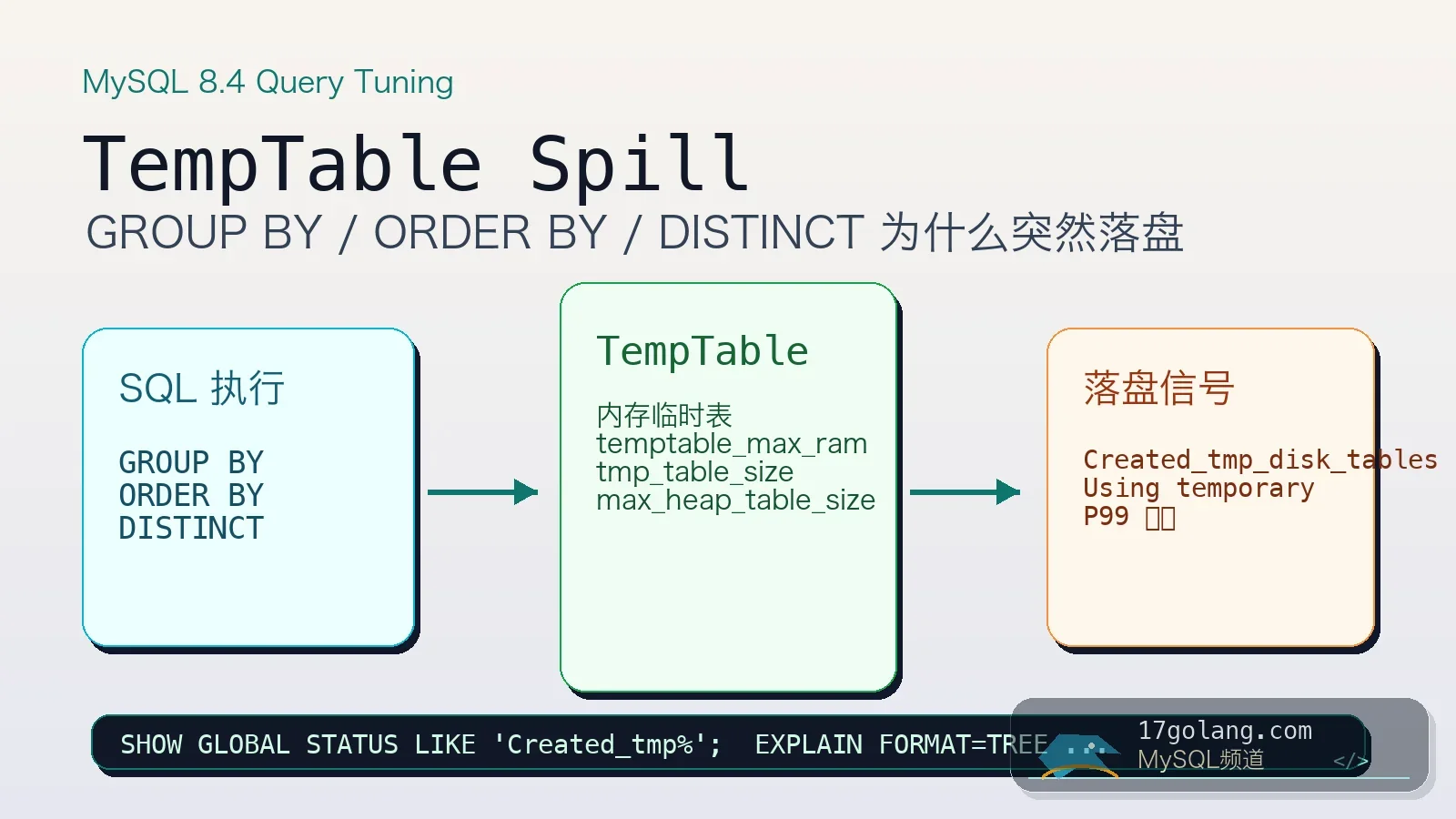 从 MySQL 8.4 内部临时表和 TempTable 入手,讲清 GROUP BY、ORDER BY、DISTINCT 落盘诊断、SQL 改写、索引策略和参数兜底。267 收藏
从 MySQL 8.4 内部临时表和 TempTable 入手,讲清 GROUP BY、ORDER BY、DISTINCT 落盘诊断、SQL 改写、索引策略和参数兜底。267 收藏 -
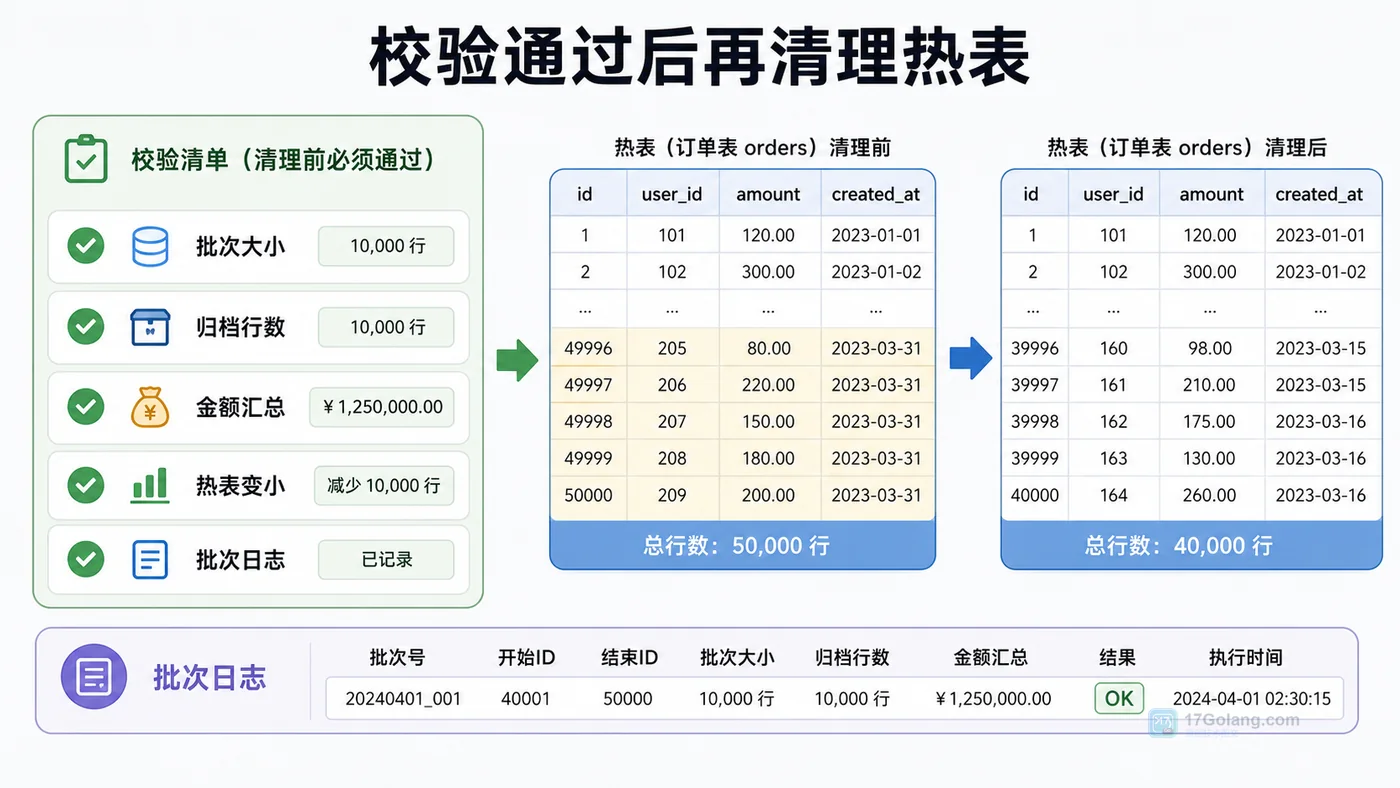 本文用订单表归档为例,讲清 MySQL 历史数据如何按时间窗口分批搬迁:先确定归档边界,再批量写入归档表,校验数量和金额,最后小批量清理热表,降低锁等待和慢查询风险。261 收藏
本文用订单表归档为例,讲清 MySQL 历史数据如何按时间窗口分批搬迁:先确定归档边界,再批量写入归档表,校验数量和金额,最后小批量清理热表,降低锁等待和慢查询风险。261 收藏 -
数据库 · MySQL | 3星期前 | 性能优化 · 高并发 · InnoDB · MySQL教程 · 数据库运维 · mysql innodb AUTO_INCREMENT 高并发写入 innodb_autoinc_lock_mode
 从 MySQL 8.4 AUTO_INCREMENT 锁模式入手,讲清高并发 INSERT、批量导入、复制格式和上线回滚检查。254 收藏
从 MySQL 8.4 AUTO_INCREMENT 锁模式入手,讲清高并发 INSERT、批量导入、复制格式和上线回滚检查。254 收藏